

Paxos Made Live - An Engineering Perspective
Tushar Chandra
Robert Griesemer
Joshua Redstone
June 26, 2007
Abstract
We describe our experience bu ilding a fault-tolerant data-base using t he Paxos consensus algorithm.
Despite the existing literature in the field, building such a database proved to be non-trivial. We describe
selected algorithmic and engineering problems encountered, and the solutions we found for them. Our
measurements indicate that we have built a competitive system.
1 Introduction
It is well known that fault-tolerance on commodity hardware can be achieved through replication [17, 18]. A
common approach is to use a consensus algorithm [7] to ensure that all r e plicas are mutually consistent [8 ,
14, 17]. By repeatedly applying such an algorithm on a sequence of input values, it is possible to build an
identica l log of values on each replica. If the values are operations on some data structure, application of
the same log on all replicas may be used to a rrive at mutually consistent data structures on all replicas. For
instance, if the log contains a sequence of database operations, and if the same sequence of operations is
applied to the (local) database on each re plica, eventually all replica s will end up with the same database
content (provided that they all started with the same initial database state).
This general approach can be used to implement a wide variety o f fault-tolerant primitives, of which a
fault-tolerant database is just an example. As a result, the consensus problem has been s tudied ex tensively
over the past two decades. There are several well-known consensus algorithms that operate within a multitude
of settings and which toler ate a variety of failures. The Paxos consensus algorithm [8] has been discussed in
the theoretical [16] and applied community [10, 11, 12] for over a dec ade.
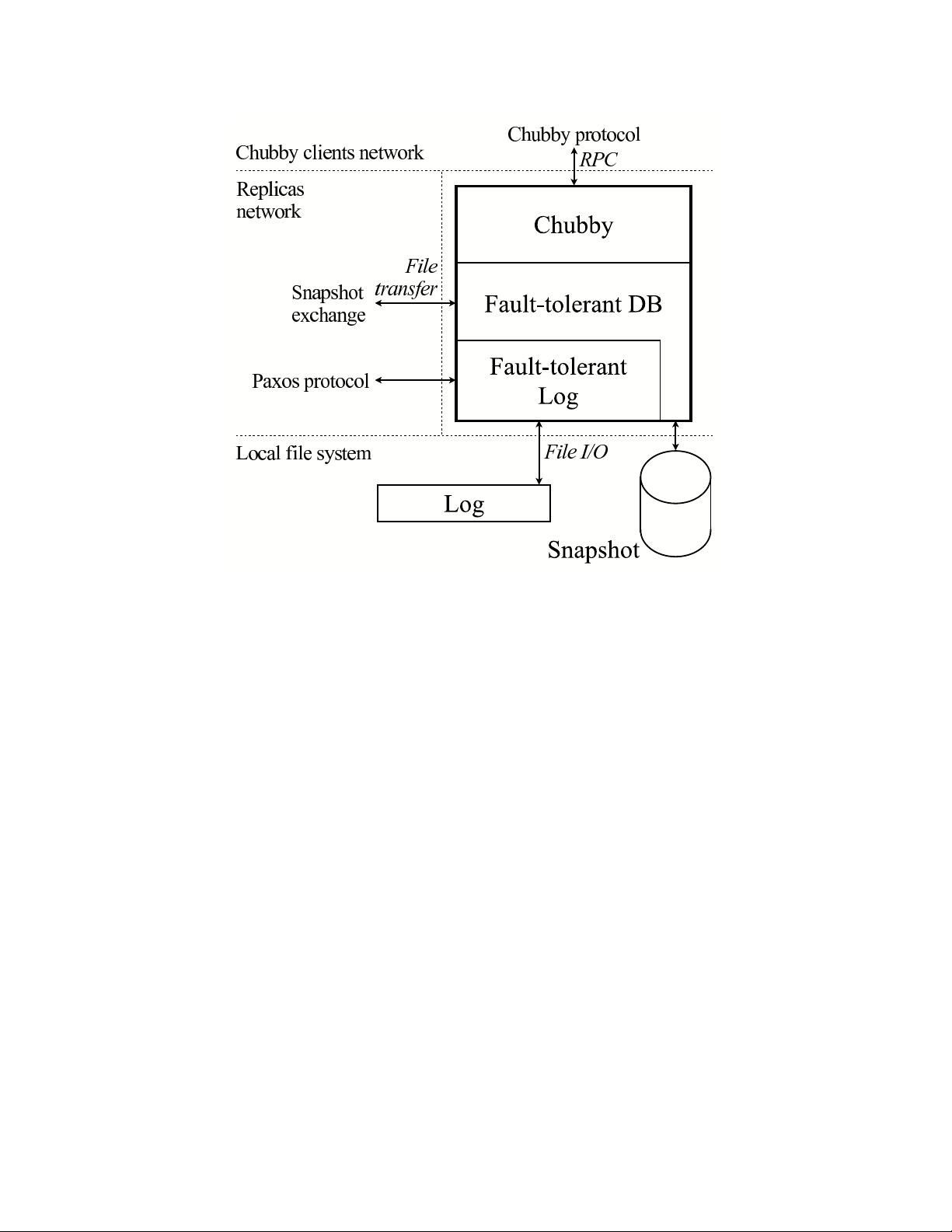
We used the Paxos algorithm (“Paxos” ) as the base for a framework that implements a fault-tolerant
log. We then relied o n that framework to build a fault-tolerant database. Despite the existing literature on
the subject, building a production system turned out to be a non-trivial task for a variety of reaso ns:
• While Paxos can be described with a page of pseudo-code, our complete implementation contains several
thousand lines of C++ code. The blow-up is not due simply to the fact that we used C++ ins tead
of pseudo notation, nor because our code style may have been verbose. Converting the algorithm into
a practical, production-ready system involved implementing many features and optimizations – some
published in the literature and some not.
• The fault-tolerant algorithms community is a ccustomed to proving short algorithms (one page of pseudo
code) correc t. This approa ch does not sca le to a system with thousands of lines of code. To gain
confidence in the “correctness” of a real system, different methods had to be use d.
• Fault-tolerant algorithms tolerate a limited set of carefully selected faults. However, the real world
exp oses software to a wide variety of failure modes, including e rrors in the algorithm, bugs in its
c
ACM 2007. This is a minor revision of the work that wil l be published in the proceedings of ACM PODC 2007.
1

剩余15页未读,继续阅读
资源评论

 cisco_vpn2014-08-26又是一篇关于paxos算法的经典论文,正在学习中,很不错。
cisco_vpn2014-08-26又是一篇关于paxos算法的经典论文,正在学习中,很不错。 baidu_225254132016-07-19不错,很好用,很经典!
baidu_225254132016-07-19不错,很好用,很经典!












