
<p align="left">
<span>
中文
</span>
<span> • </span>
<a href="README_ja.md">
日本語
</a>
<span> • </span>
<a href="README_en.md">
English
</a>
</p>
<p align="center">
<a href="https://github.com/hiroi-sora/Umi-OCR">
<img width="200" height="128" src="https://tupian.li/images/2022/10/27/icon---256.png" alt="Umi-OCR">
</a>
</p>
<h1 align="center">Umi-OCR 文字识别工具</h1>
<p align="center">
<a href="https://github.com/hiroi-sora/Umi-OCR/releases/latest">
<img src="https://img.shields.io/github/v/release/hiroi-sora/Umi-OCR?style=flat-square" alt="Umi-OCR">
</a>
<a href="License">
<img src="https://img.shields.io/github/license/hiroi-sora/Umi-OCR?style=flat-square" alt="LICENSE">
</a>
<a href="#下载发行版">
<img src="https://img.shields.io/github/downloads/hiroi-sora/Umi-OCR/total?style=flat-square" alt="forks">
</a>
<a href="https://star-history.com/#hiroi-sora/Umi-OCR">
<img src="https://img.shields.io/github/stars/hiroi-sora/Umi-OCR?style=flat-square" alt="stars">
</a>
<a href="https://github.com/hiroi-sora/Umi-OCR/forks">
<img src="https://img.shields.io/github/forks/hiroi-sora/Umi-OCR?style=flat-square" alt="forks">
</a>
<a href="https://hosted.weblate.org/engage/umi-ocr/">
<img src="https://hosted.weblate.org/widget/umi-ocr/svg-badge.svg" alt="翻译状态">
</a>
</p>
<div align="center">
<h3>
<a href="#目录">
使用说明
</a>
<span> • </span>
<a href="#下载发行版">
下载地址
</a>
<span> • </span>
<a href="CHANGE_LOG.md">
更新日志
</a>
<span> • </span>
<a href="https://github.com/hiroi-sora/Umi-OCR/issues">
提交Bug
</a>
</h3>
</div>
<br>
<div align="center">
<strong>免费,开源,可批量的离线OCR软件</strong><br>
<sub>适用于 Windows7 x64 及以上</sub>
</div><br>
- **免费**:本项目所有代码开源,完全免费。
- **方便**:解压即用,离线运行,无需网络。
- **高效**:自带高效率的离线OCR引擎,内置多种语言识别库。
- **灵活**:支持命令行、HTTP接口等外部调用方式。
- **功能**:截图OCR / 批量OCR / PDF识别 / 二维码 / 公式识别([测试中](https://github.com/hiroi-sora/Umi-OCR/issues/254))
<p align="center"><img src="https://tupian.li/images/2023/11/19/65599097ab5f4.png" alt="1-标题-1.png" style="width: 80%;"></p>
## 目录
- [截图识别](#截图OCR)
- [排版解析](#文本后处理) - 识别不同排版,按正确顺序输出文字
- [批量识别](#批量OCR)
- [忽略区域](#忽略区域) - 排除截图水印处的文字
- [二维码](#二维码) 支持扫码或生成二维码图片
- [文档识别](#文档识别) 从PDF扫描件中提取文本,或转为双层可搜索PDF
- [全局设置](#全局设置) 添加更多PP-OCR支持的语言模型库!
- [命令行调用](docs/README_CLI.md)
- [HTTP接口](docs/README_HTTP.md)
- [构建项目](#构建项目)
## 使用源码
开发者请务必阅读 [构建项目](#构建项目) 。
## 下载发行版
以下发布链接均长期维护,提供最新软件版本。
- **蓝奏云** https://hiroi-sora.lanzoul.com/s/umi-ocr (国内推荐,免注册/无限速)
- **GitHub** https://github.com/hiroi-sora/Umi-OCR/releases/latest
- **Source Forge** https://sourceforge.net/projects/umi-ocr
## 开始使用
软件发布包下载为 `.7z` 压缩包或 `.7z.exe` 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件。
本软件无需安装。解压后,点击 `Umi-OCR.exe` 即可启动程序。
遇到任何问题,请提 [Issue](https://github.com/hiroi-sora/Umi-OCR/issues) ,我会尽可能帮助你。
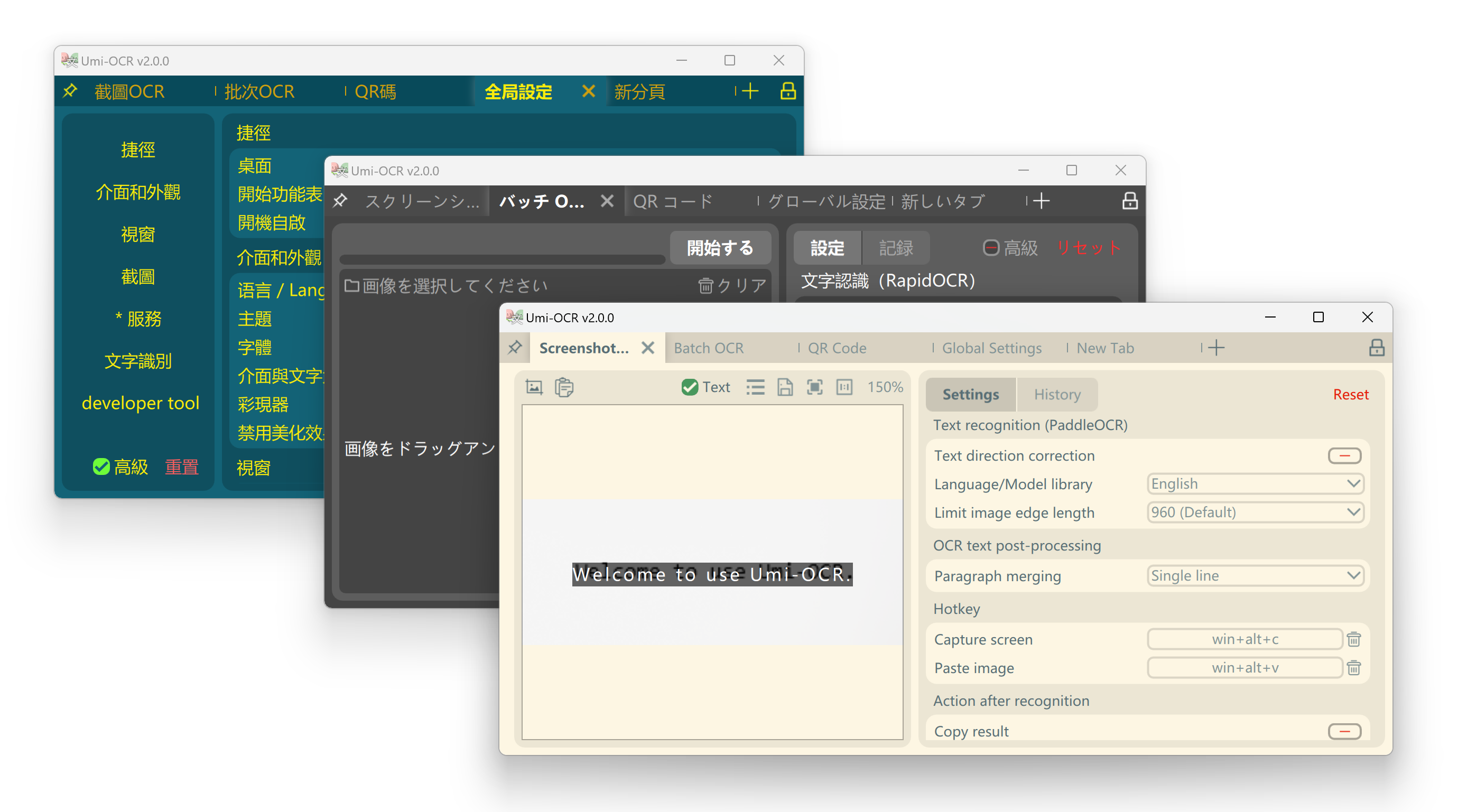
## 界面语言
Umi-OCR 支持的界面多国语言。在第一次打开软件时,将会按照你的电脑的系统设置,自动切换语言。
如果需要手动切换语言,请参考下图,`全局设置`→`语言/Language` 。
<p align="center"><img src="https://tupian.li/images/2023/11/19/65599c3f9e600.png" alt="1-标题-1.png" style="width: 80%;"></p>
## 标签页
Umi-OCR v2 由一系列灵活好用的**标签页**组成。您可按照自己的喜好,打开需要的标签页。
标签栏左上角可以切换**窗口置顶**。右上角能够**锁定标签页**,以防止日常使用中误触关闭标签页。
### 截图OCR
<p align="center"><img src="https://tupian.li/images/2023/11/19/65599097aba8e.png" alt="2-截图-1.png" style="width: 80%;"></p>
**截图OCR**:打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
- 左侧的图片预览栏,可直接用鼠标划选复制。
- 右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
- 也支持在别处复制图片,粘贴到Umi-OCR进行识别。
#### 文本后处理
<p align="center"><img src="https://tupian.li/images/2023/11/19/6559909f3e378.png" alt="2-截图-2.png" style="width: 80%;"></p>
关于 **OCR文本后处理 - 排版解析方案**: 可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案:
- `多栏-按自然段换行`:适合大部分情景,自动识别多栏布局,按自然段规则进行换行。
- `多栏-总是换行`:每段语句都进行换行。
- `多栏-无换行`:强制将所有语句合并到同一行。
- `单栏-按自然段换行`/`总是换行`/`无换行`:与上述类似,不过 不区分多栏布局。
- `单栏-保留缩进`:适用于解析代码截图,保留行首缩进和行中空格。
- `不做处理`:OCR引擎的原始输出,默认每段语句都进行换行。
上述方案,均能自动处理横排和竖排(从右到左)的排版。(竖排文字还需要OCR引擎本身支持)
---
### 批量OCR
<p align="center"><img src="https://tupian.li/images/2023/11/19/655990a2511e0.png" alt="3-批量-1.png" style="width: 80%;"></p>
**批量OCR**:这一页用于批量导入本地图片进行识别。
- 支持格式:`jpg, jpe, jpeg, jfif, png, webp, bmp, tif, tiff`。
- 保存识别结果的支持格式:`txt, jsonl, md, csv(Excel)`。
- 与截图OCR一样,支持`文本后处理`功能,整理OCR文本的排版和顺序。
- 没有数量上限,可一次性导入几百张图片进行任务。
- 支持任务完成后自动关机/待机。
- 如果要识别像素超大的长图或大图,请调整:**页面的设置→文字识别→限制图像边长→【调高数值】**。
- 拥有特殊功能 `忽略区域` 。
#### 忽略区域
<p align="center"><img src="https://tupian.li/images/2023/11/19/6559911d28be7.png" alt="3-批量-2.png" style="width: 80%;"></p>
关于 **OCR文本后处理 - 忽略区域**: 批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。
---
### 文档识别
<p align="center"><img src="https://github.com/hiroi-sora/Umi-OCR/assets/56373419/fc2266ee-b9b7-4079-8b10-6610e6da6cf5" alt="" style="width: 80%;"></p>
**文档识别**:
- 支持格式:`pdf, xps, epub, mobi, fb2, cbz`。
- 对扫描件进行OCR,或提取原有文本。可输出为 **双层可搜索PDF** 。
- 支持设定 **忽略区域** ,可用于排除页眉页脚的文字。
- 可设置任务完成后 **自动关机/休眠** 。
---
### 二维码
<p align="center"><img src="https://tupian.li/images/2023/11/19/655991268d6b1.png" alt="4-二维码-1.png" style="width: 80%;"></p>
**扫�
 图片转文字识别软件:它可离线使用,支持截屏识别文字、批量导入图片、横/竖排文字,同时能够自动忽略水印区域 (234个子文件)
图片转文字识别软件:它可离线使用,支持截屏识别文字、批量导入图片、横/竖排文字,同时能够自动忽略水印区域 (234个子文件)  RUN_GUI.bat 50B test_speed.bat 49B RUN_CLI.bat 49B Umi-OCR_v2.code-workspace 1KB 翻译.code-workspace 240B Qt5Gui.dll 5.63MB Qt5Core.dll 5.14MB Qt5Widgets.dll 4.26MB qwindows.dll 1.17MB Qt5PrintSupport.dll 266KB Qt5Xml.dll 175KB qwindowsvistastyle.dll 135KB
RUN_GUI.bat 50B test_speed.bat 49B RUN_CLI.bat 49B Umi-OCR_v2.code-workspace 1KB 翻译.code-workspace 240B Qt5Gui.dll 5.63MB Qt5Core.dll 5.14MB Qt5Widgets.dll 4.26MB qwindows.dll 1.17MB Qt5PrintSupport.dll 266KB Qt5Xml.dll 175KB qwindowsvistastyle.dll 135KB linguist.exe 1.02MB lupdate.exe 483KB lrelease.exe 177KB .gitignore 676B umiocr.ico 78KB launch.json 3KB about.json 3KB settings.json 848B LICENSE 1KB README_HTTP.md 23KB CHANGE_LOG.md 15KB README.md 14KB README_ja.md 12KB README_en.md 11KB README_CLI.md 6KB 翻译步骤(完整).md 5KB 翻译注意事项.md 4KB 翻译步骤(简易).md 3KB README.md 1KB
linguist.exe 1.02MB lupdate.exe 483KB lrelease.exe 177KB .gitignore 676B umiocr.ico 78KB launch.json 3KB about.json 3KB settings.json 848B LICENSE 1KB README_HTTP.md 23KB CHANGE_LOG.md 15KB README.md 14KB README_ja.md 12KB README_en.md 11KB README_CLI.md 6KB 翻译步骤(完整).md 5KB 翻译注意事项.md 4KB 翻译步骤(简易).md 3KB README.md 1KB i18n.png 462KB Preview1.png 367KB Umi-OCR-截图页2.png 144KB Umi-OCR-批量页1.png 140KB Umi-OCR-截图页1.png 126KB Umi-OCR_logo_full.png 100KB icon-256.png 94KB Umi-OCR-全局页1.png 57KB dango_right.png 45KB bottle.py 151KB cmd_server.py 18KB gap_tree.py 15KB mission_doc.py 11KB mission_qrcode.py 11KB mission.py 10KB BatchDOC.py 8KB image_provider.py 8KB keyboard.py 7KB paragraph_parse.py 7KB BatchOCR.py 7KB run.py 7KB cmd_client.py 6KB utils.py 5KB tag_pages_connector.py 5KB output_pdf_layered.py 5KB web_server.py 5KB ImageQt.py 5KB mission_ocr.py 5KB main.py 5KB qrcode_server.py 5KB ocr_server.py 5KB ScreenshotOCR.py 4KB doc_preview_connector.py 4KB i18n_configs.py 4KB line_preprocessing.py 4KB pubsub_service.py 4KB screenshot_controller.py 3KB umi_about.py 3KB plugins_controller.py 3KB QRCode.py 3KB parser_single_code.py 3KB output_csv.py 3KB shortcut.py 2KB simple_mission.py 2KB app_opengl.py 2KB parser_single_line.py 2KB win32_api.py 2KB global_configs_connector.py 2KB pre_configs.py 2KB pubsub_connector.py 2KB call_func.py 2KB call_func.py 2KB key_translator.py 2KB plugin_i18n.py 2KB output_md.py 2KB parser_single_para.py 2KB output_txt.py 1KB image_connector.py 1KB mission_connector.py 1KB page.py 1KB utils_connector.py 1KB output_txt_individual.py 1KB __init__.py 1KB output.py 1KB parser_multi_para.py 1KB parser_multi_none.py 1KB output_txt_plain.py 1KB __init__.py 1024B __init__.py 995B
i18n.png 462KB Preview1.png 367KB Umi-OCR-截图页2.png 144KB Umi-OCR-批量页1.png 140KB Umi-OCR-截图页1.png 126KB Umi-OCR_logo_full.png 100KB icon-256.png 94KB Umi-OCR-全局页1.png 57KB dango_right.png 45KB bottle.py 151KB cmd_server.py 18KB gap_tree.py 15KB mission_doc.py 11KB mission_qrcode.py 11KB mission.py 10KB BatchDOC.py 8KB image_provider.py 8KB keyboard.py 7KB paragraph_parse.py 7KB BatchOCR.py 7KB run.py 7KB cmd_client.py 6KB utils.py 5KB tag_pages_connector.py 5KB output_pdf_layered.py 5KB web_server.py 5KB ImageQt.py 5KB mission_ocr.py 5KB main.py 5KB qrcode_server.py 5KB ocr_server.py 5KB ScreenshotOCR.py 4KB doc_preview_connector.py 4KB i18n_configs.py 4KB line_preprocessing.py 4KB pubsub_service.py 4KB screenshot_controller.py 3KB umi_about.py 3KB plugins_controller.py 3KB QRCode.py 3KB parser_single_code.py 3KB output_csv.py 3KB shortcut.py 2KB simple_mission.py 2KB app_opengl.py 2KB parser_single_line.py 2KB win32_api.py 2KB global_configs_connector.py 2KB pre_configs.py 2KB pubsub_connector.py 2KB call_func.py 2KB call_func.py 2KB key_translator.py 2KB plugin_i18n.py 2KB output_md.py 2KB parser_single_para.py 2KB output_txt.py 1KB image_connector.py 1KB mission_connector.py 1KB page.py 1KB utils_connector.py 1KB output_txt_individual.py 1KB __init__.py 1KB output.py 1KB parser_multi_para.py 1KB parser_multi_none.py 1KB output_txt_plain.py 1KB __init__.py 1024B __init__.py 995B共 234 条
- 1
- 2
- 3
资源评论













