Large-scale cluster management at Google with Borg
需积分: 0 144 浏览量
2017-09-18
12:43:25
上传
评论
收藏 793KB PDF 举报

Large-scale cluster management at Google with Borg
Abhishek Verma
†
Luis Pedrosa
‡
Madhukar Korupolu
David Oppenheimer Eric Tune John Wilkes
Google Inc.
Abstract
Google’s Borg system is a cluster manager that runs hun-
dreds of thousands of jobs, from many thousands of differ-
ent applications, across a number of clusters each with up to
tens of thousands of machines.
It achieves high utilization by combining admission con-
trol, efficient task-packing, over-commitment, and machine
sharing with process-level performance isolation. It supports
high-availability applications with runtime features that min-
imize fault-recovery time, and scheduling policies that re-
duce the probability of correlated failures. Borg simplifies
life for its users by offering a declarative job specification
language, name service integration, real-time job monitor-
ing, and tools to analyze and simulate system behavior.
We present a summary of the Borg system architecture
and features, important design decisions, a quantitative anal-
ysis of some of its policy decisions, and a qualitative ex-
amination of lessons learned from a decade of operational
experience with it.
1. Introduction
The cluster management system we internally call Borg ad-
mits, schedules, starts, restarts, and monitors the full range
of applications that Google runs. This paper explains how.
Borg provides three main benefits: it (1) hides the details
of resource management and failure handling so its users can
focus on application development instead; (2) operates with
very high reliability and availability, and supports applica-
tions that do the same; and (3) lets us run workloads across
tens of thousands of machines effectively. Borg is not the
first system to address these issues, but it’s one of the few op-
erating at this scale, with this degree of resiliency and com-
pleteness. This paper is organized around these topics, con-
†
Work done while author was at Google.
‡
Currently at University of Southern California.
Permission to make digital or hard copies of part or all of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for third-party components of this work must be honored.
For all other uses, contact the owner/author(s).
EuroSys’15, April 21–24, 2015, Bordeaux, France.
Copyright is held by the owner/author(s).
ACM 978-1-4503-3238-5/15/04.
http://dx.doi.org/10.1145/2741948.2741964
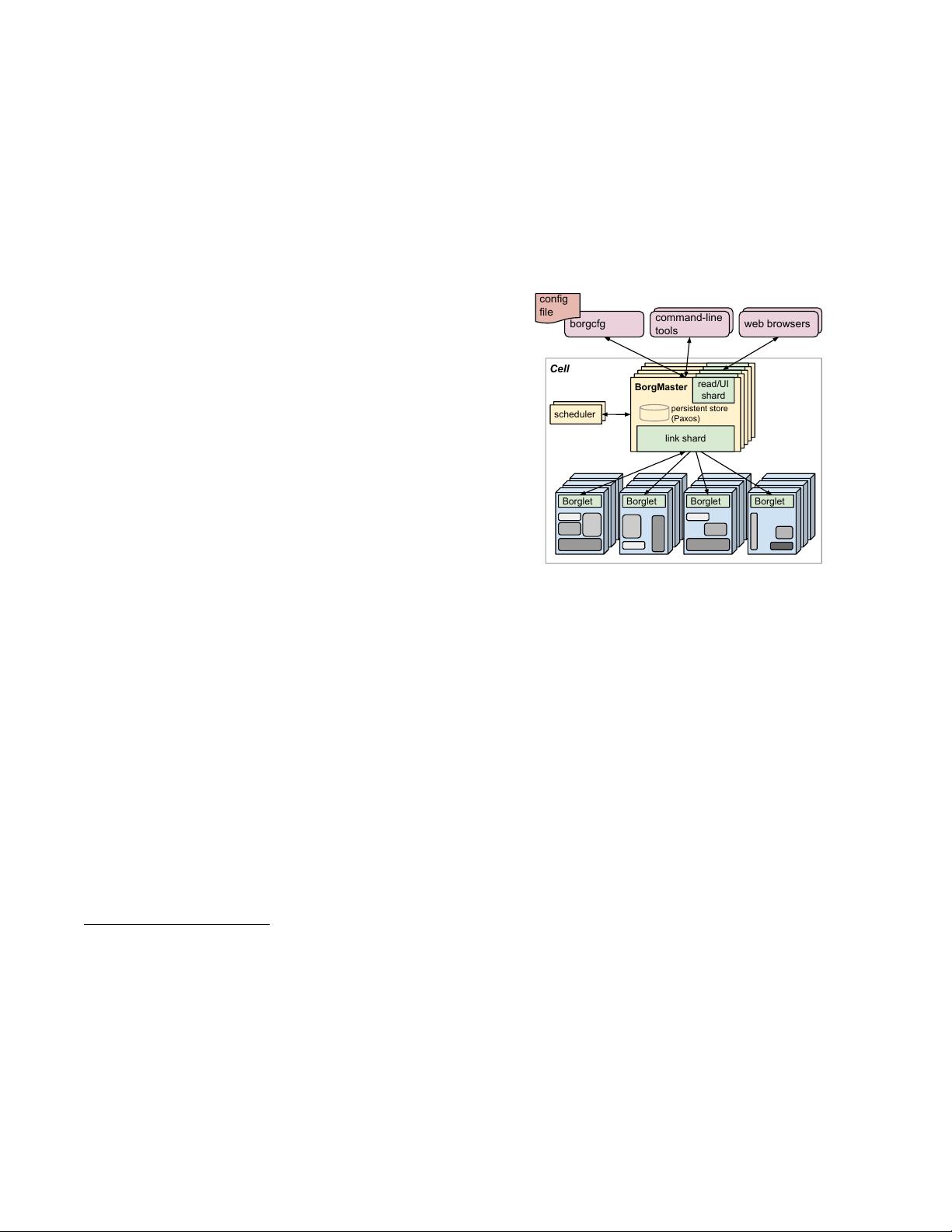
web browsers
BorgMaster
link shard
UI shard
BorgMaster
link shard
UI shard
BorgMaster
link shard
UI shard
BorgMaster
link shard
UI shard
Cell
Scheduler
borgcfg
command-line
tools
web browsers
scheduler
Borglet Borglet Borglet Borglet
BorgMaster
link shard
read/UI
shard
config
file
persistent store
(Paxos)
Figure 1: The high-level architecture of Borg. Only a tiny fraction
of the thousands of worker nodes are shown.
cluding with a set of qualitative observations we have made
from operating Borg in production for more than a decade.
2. The user perspective
Borg’s users are Google developers and system administra-
tors (site reliability engineers or SREs) that run Google’s
applications and services. Users submit their work to Borg
in the form of jobs, each of which consists of one or more
tasks that all run the same program (binary). Each job runs
in one Borg cell, a set of machines that are managed as a
unit. The remainder of this section describes the main fea-
tures exposed in the user view of Borg.
2.1 The workload
Borg cells run a heterogenous workload with two main parts.
The first is long-running services that should “never” go
down, and handle short-lived latency-sensitive requests (a
few µs to a few hundred ms). Such services are used for
end-user-facing products such as Gmail, Google Docs, and
web search, and for internal infrastructure services (e.g.,
BigTable). The second is batch jobs that take from a few
seconds to a few days to complete; these are much less sen-
sitive to short-term performance fluctuations. The workload
mix varies across cells, which run different mixes of applica-
tions depending on their major tenants (e.g., some cells are
quite batch-intensive), and also varies over time: batch jobs


剩余16页未读,继续阅读
资源评论


ShaoKaiyang
- 粉丝: 76
- 资源: 2









最新资源
- docker一键安装包
- Screenshot_20240430_144340_com.ss.android.ugc.live.jpg
- 回到山沟沟.mp3
- 基于matlab实现自适应波束形成RLS及LMS算法仿真源程序1.rar
- 基于matlab实现自己编写的基于卡尔曼滤波的利用加速度传感器的计步器,测试数据是传感器放在腰部和手臂 .rar
- 基于matlab实现阵列信号处理,波束形成.rar
- 111111111111111111
- 基于matlab实现计步器编程;对当前的计步器装置的数值算法模拟 .rar
- Mdb学习查看PW;access;mdb;pw;password;patch
- 基于matlab实现关于语音信号声源定位DOA估计所用的一些传统算法.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


