

细细品味 Nutch
——Nutch 搜索引擎(第 3 期)
精
华
集
锦
csAxp
http://www.xiapistudio.com/
2012 年 4 月 9 日

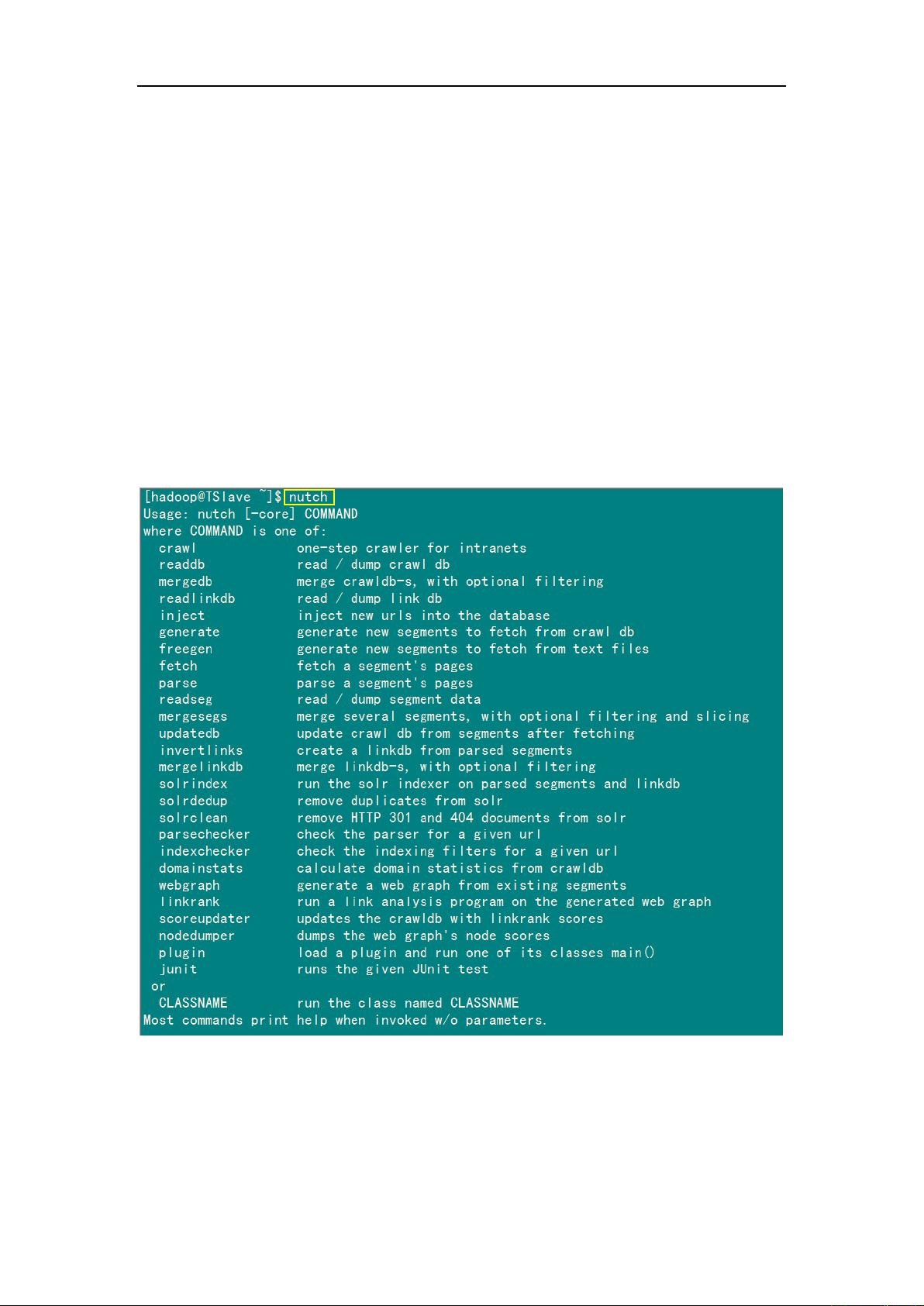

剩余23页未读,继续阅读
资源评论


Tadas-Gao
- 粉丝: 190
- 资源: 390









最新资源
- python006-django基于python技术的学生管理系统的设计与开发.zip
- java毕设项目之教师工作量管理系统(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之教学资料管理系统_(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之教学资料管理系统(完整前后端+说明文档+mysql+lw).zip
- centos7 Docker镜像
- 开启电影订票互动新时代:SSM 结合 JSP 系统方案
- python007-django疫情数据可视化分析系统(论文+PPT).zip
- java毕设项目之酒店管理系统(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之就业信息管理系统lw(完整前后端+说明文档+mysql).zip
- java毕设项目之经方药食两用服务平台(完整前后端+说明文档+mysql+lw).zip
- 宠物服务管理系统_c2e8kave--论文.zip
- java毕设项目之科研项目验收管理系统(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之科研工作量管理系统的设计与实现(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之老年一站式服务平台(完整前后端+说明文档+mysql).zip
- java毕设项目之旅游管理系统(完整前后端+说明文档+mysql+lw).zip
- java毕设项目之流浪动物管理系统(完整前后端+说明文档+mysql+lw).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


