






大连东软信息技术职业学院
外文资料和译文
专 业:
班 级:
姓 名:
学 号:
指导教师:

年 月 日

大连东软信息技术职业学院毕业设计(论文) 译文
CHAPTER 3: STACKS AND QUEUES
3.1 FUNDAMENTALS
Two of the more common data objects found in computer algorithms are stacks and queues.
They arise so often that we will discuss them separately before moving on to more complex
objects. Both these data objects are special cases of the more general data object, an ordered list
which we considered in the previous chapter. Recall that A = (a1, a2, ...,an), is an ordered list of
elements. The ai are referred to as atoms which are taken from some set. The null or empty list
has n = 0 elements.
A stack is an ordered list in which all insertions and deletions are made at one end, called the top.
A queue is an ordered list in which all insertions take place at one end, the rear, while all
deletions take place at the other end, the front. Given a stack S = (a1, ...an) then we say that a1 is
the bottommost element and element ai is on top of element ai - 1, 1 < i n. When viewed as a
queue with an as the rear element one says that ai+1 is behind ai, 1 i< n.
Figure 3.1
The restrictions on a stack imply that if the elements A,B,C,D,E are added to the stack, in that
order, then the first element to be removed/deleted must be E. Equivalently we say that the
last"element to be inserted into the stack will be the first to be removed. For this reason stacks are
sometimes referred to as Last In
First Out (LIFO) lists. The
restrictions on a queue require
that the first element which is
inserted into the queue will be
the first one to be removed.
Thus A is the first letter to be
removed, and queues are known
as First In First Out (FIFO) lists. Note that the data object queue as defined here need not
necessarily correspond to the mathematical concept of queue in which the insert/delete ru les may
be different.
1
大连东软信息技术职业学院毕业设计(论文) 译文
One natural example of stacks which arises in computer programming is the processing of
subroutine calls and their returns. Suppose we have a main procedure and three subroutines as
below:
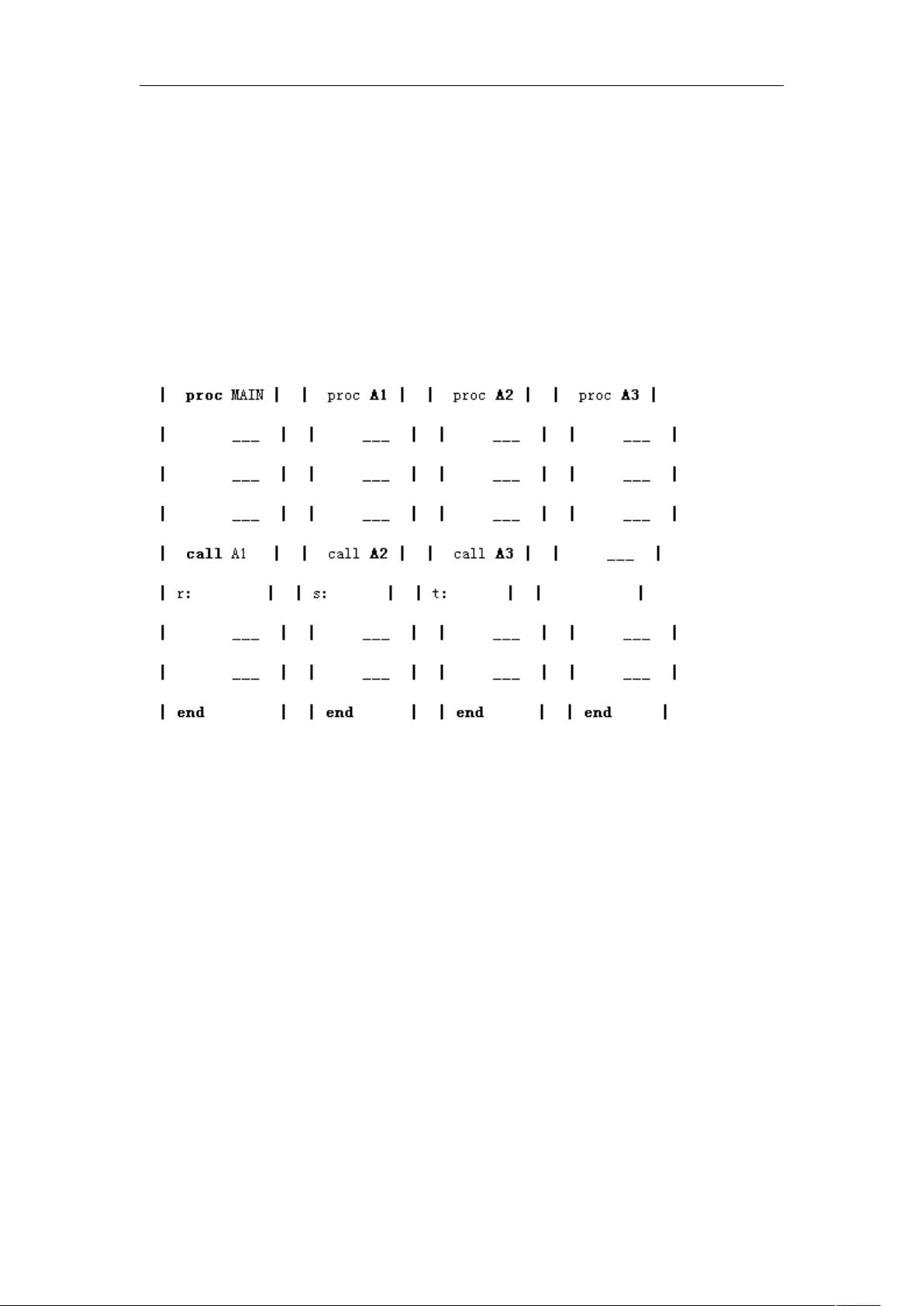
Figure 3.2. Sequence of subroutine calls
The MAIN program calls subroutine A1. On completion of A1 execution of MAIN will resume at
location r. The address r is passed to Al which saves it in some location for later processing. Al
then invokes A2 which in turn calls A3. In each case the calling procedure passes the return
address to the called procedure. If we examine the memory while A3 is computing there will be an
implicit stack which looks like
(q,r,s,t).
The first entry, q, is the address in the operating system where MAIN returns control. This list
operates as a stack since the returns will be made in the reverse order of the calls. Thus t is
removed before s, s before r and r before q. Equivalently, this means that A3 must finish
processing before A2, A2 before A1, and A1 before MAIN. This list of return addresses need not
be maintained in consecutive locations. For each subroutine there is usually a single location
associated with the machine code which is used to retain the return address. This can be severely
limiting in the case of recursive calls and re-entrant routines, since every time we call a subroutine
the new return address wipes out the old one. For example, if we inserted a call to A1 within
subroutine A3 expecting the return to be at location u, then at execution time the stack would
become (q,u,s,t) and the return address r would be lost. When recursion is allowed, it is no longer
adequate to reserve one location for the return address of each subroutine. Since returns are made
2

大连东软信息技术职业学院毕业设计(论文) 译文
in the reverse order of calls, an elegant and natural solution to this subroutine return problem is
afforded through the explicit use of a stack of return addresses. Whenever a return is made, it is to
the top address in the stack. Implementing recursion using a stack is discussed in Section 4.10.
Associated with the object stack there are several operations that are necessary:
CREATE (S) which creates S as an empty stack;
ADD (i,S) which inserts the element i onto the stack S and returns the new stack;
DELETE (S) which removes the top element of stack S and returns the new stack;
TOP (S) which returns the top element of stack S;
ISEMTS (S) which returns true if S is empty else false;
These five functions constitute a working definition of a stack. However we choose to represent a
stack, it must be possible to build these operations. But before we do this let us describe formally
the structure STACK.
structure STACK (item)
1 declare CREATE ( ) stack
2 ADD (item, stack) stack
3 DELETE (stack) stack
4 TOP (stack) item
5 ISEMTS (stack) boolean;
6 for all S stack, i item let
7 ISEMTS (CREATE) :: = true
8 ISEMTS (ADD (i,S)) :: = false
9 DELETE (CREATE) :: = error
10 DELETE (ADD (i,S)) :: = S
11 TOP(CREATE) :: = error
12 TOP(ADD(i,S)) :: = i
13 end
end STACK
The five functions with their domains and ranges are declared in lines 1 through 5. Lines 6
through 13 are the set of axioms which describe how the functions are related. Lines 10 and 12 are
the essential ones which define the last-in-first-out behavior. The above definitions describe an
infinite stack for no upper bound on the number of elements is specified. This will be dealt with
when we represent this structure in a computer.
The simplest way to represent a stack is by using a one-dimensional array, say STACK(1:n),
where n is the maximum number of allowable entries. The first or bottom element in the stack
will be stored at STACK(1), the second at STACK(2) and the i-th at STACK(i). Associated with
the array will be a variable, top, which points to the top element in the stack. With this decision
made the following implementations result:
CREATE ( ) :: = declare STACK(1:n); top 0
3















