实验 4 用 Yacc 工具构造语法分析器
一、实验目的
掌握移进-归约技术语法分析技术,利用语法分析器生成工具 Yacc/Bison 实
现语法分析器的构造。
二、实验内容
利用语法分析器生成工具 Yacc/Bison 编写一个语法分析程序,与词法分析
器结合,能够根据语言的上下文无关文法,识别输入的单词序列是否文法的句
子。
源语言的文法定义见教材附录 A.1,p394,要求实现完整的语言。
三、实验要求
1.个人完成,提交实验报告。
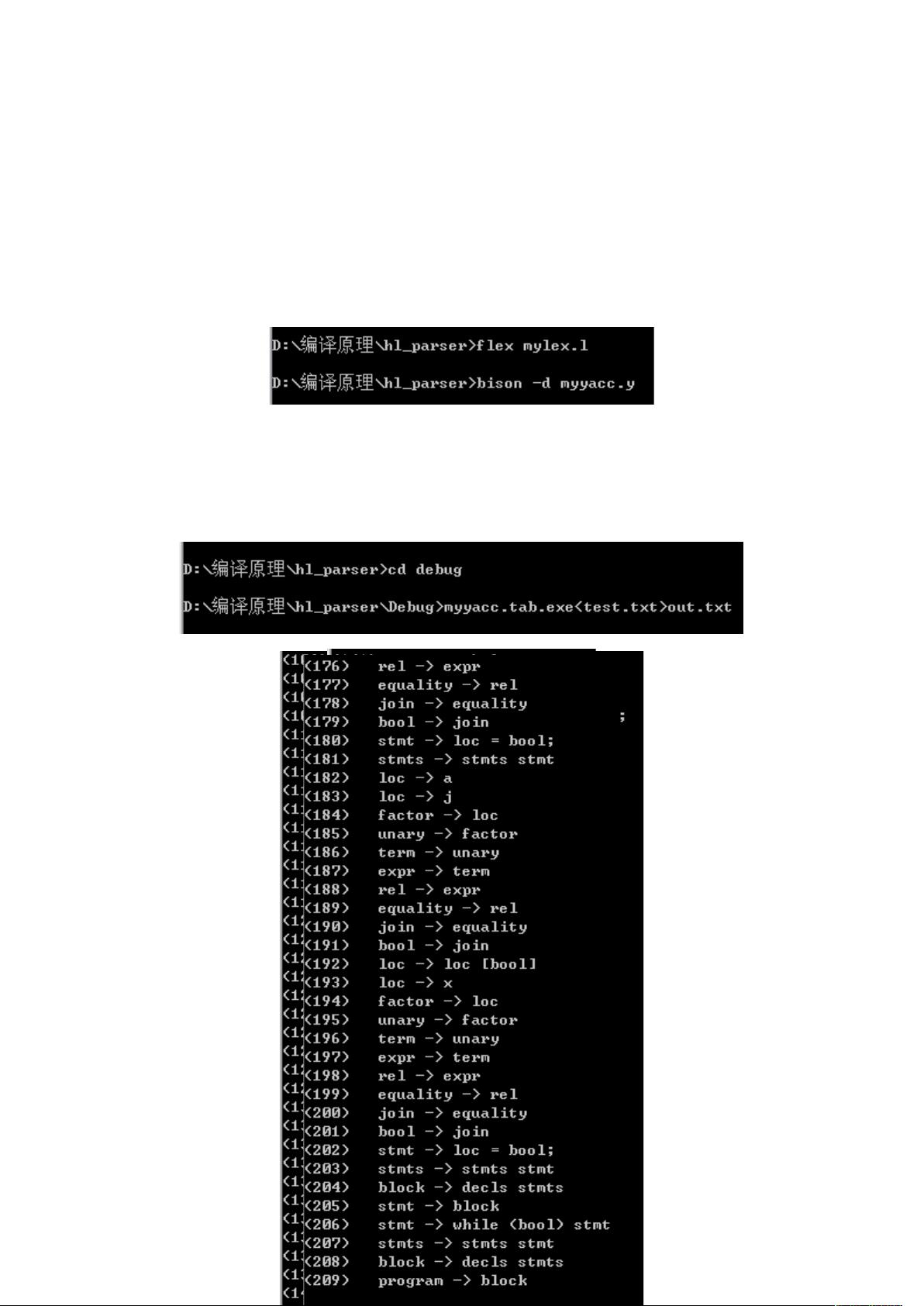
2.实验报告中给出采用测试源代码片断,及其对应的最右推导过程(形式可
以自行考虑,如依次给出推导使用的产生式)。
例如,程序片断