
Eurographics Symposium on Rendering (2004)
H. W. Jensen, A. Keller (Editors)
A Self-Shadow Algorithm for Dynamic Hair
using Density Clustering
Tom Mertens
†
Jan Kautz
‡
Philippe Bekaert
†
Frank Van Reeth
†
Expertise Centre for Digital Media
Limburgs Universitair Centrum
†
Universitaire Campus, 3590 Diepenbeek, Belgium
CSAIL
Massachusetts Institute of Technology
‡
Cambridge, MA
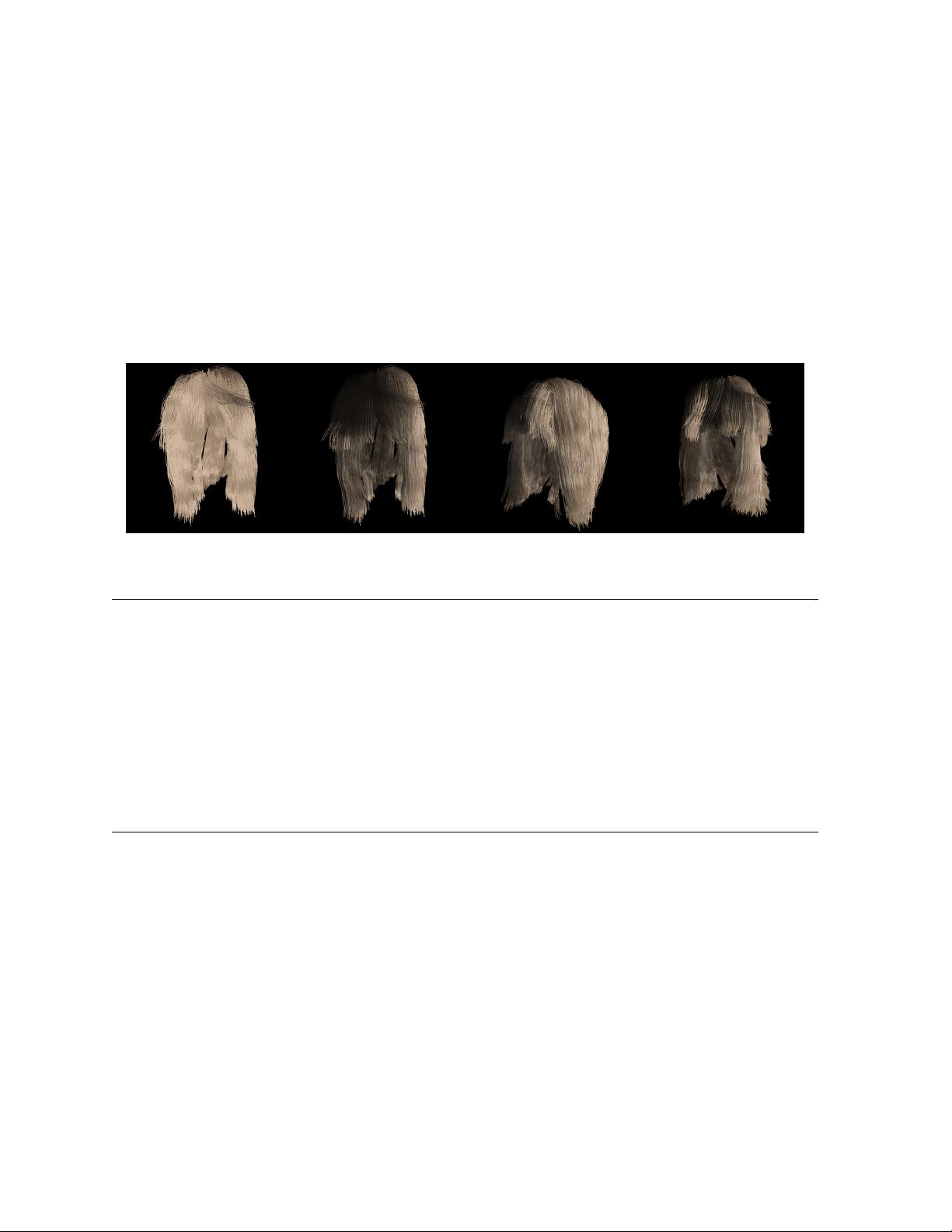
Figure 1: Frames taken from an interactive animation (6Hz) of a hair model consisting of 100K line segments. Left: image without
self-shadows. Others: images rendered with our algorithm.
Abstract
Self-shadowing is an important factor in the appearance of hair and fur. In this paper we present a new rendering
algorithm to accurately compute shadowed hair at interactive rates using graphics hardware. No constraint is
imposed on the hair style, and its geometry can be dynamic.
Similar to previously presented methods, a 1D visibility function is constructed for each line of sight of the light
source view. Our approach differs from other work by treating the hair geometry as a 3D density field, which
is sampled on the fly using simple rasterization. The rasterized fragments are clustered, effectively estimating
the density of hair along a ray. Based hereon, the visibility function is constructed. We show that realistic self-
shadowing of thousands of individual dynamic hair strands can be rendered at interactive rates using consumer
graphics hardware.
Categories and Subject Descriptors (according to ACM CCS): I.3.7 [Computer Graphics]: Color, shading, shadow-
ing, and texture
1. Introduction
Rendering hair, smoke and other semi-transparent objects is
challenging, because self-shadowing has to be handled cor-
rectly. Various algorithms exist, but are either geared towards
offline rendering [LV00, Sta94, KH84] or not quite interac-
tive yet [KN01]. We present a method that allows interactive
rendering of dynamic hair with dynamic lighting. While we
focus on the rendering of hair in this paper, rendering other
semi-transparent primitives can be handled with the same
technique. In Figure 1, an example rendering using our tech-
nique is demonstrated.
Similar to deep shadow maps [LV00], we do not store a
single depth at each pixel of a shadow map, but rather a frac-
tional visibility function (or simply visibility function) that
records the approximate amount of light that passes through
the pixel and penetrates to each depth. This visibility func-
tion takes into account the opacities (cf. coverage) of hair
strands. The partial attenuation of light passing through an
object can be accurately modelled with the help of this func-
tion.
The novelty of our algorithm lies in the way the visi-
bility function is constructed. In contrast to deep shadow
c
The Eurographics Association 2004.
资源评论

 flymagic012012-11-19对理解渲染毛发的方法比较有参考价值~
flymagic012012-11-19对理解渲染毛发的方法比较有参考价值~ 聊逍2012-10-1704年的头发渲染的一篇文献,用自阴影算法动态生成的...不值8分
聊逍2012-10-1704年的头发渲染的一篇文献,用自阴影算法动态生成的...不值8分












