

Lucene 简介
索引和搜索
Lucene 软件包分析
一个简单的搜索应用程序
建立索引
实战 Lucene,第 1 部分: 初识 Lucene
级别: 初级
朋 周登 (mailto:zhoudengpeng@yahoo.com.cn?subject=初识 Lucene), 软件工程师
2006 年 4 月 20 日
本文首先介绍了 Lucene 的一些基本概念,然后开发了一个应用程序演示了利用 Lucene 建
立索引并在该索引上进行搜索的过程。
Lucene 简介
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为
你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。
也是目前最为流行的基于 Java 开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于 Lucene 的,比如 Eclipse 的帮助系统的搜索功
能。Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的
文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文
档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化
后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根
据用户输入的查询条件在索引文件上进行查询。不指定要索引的文档的格式也使 Lucene 能
够几乎适用于所有的搜索应用程序。
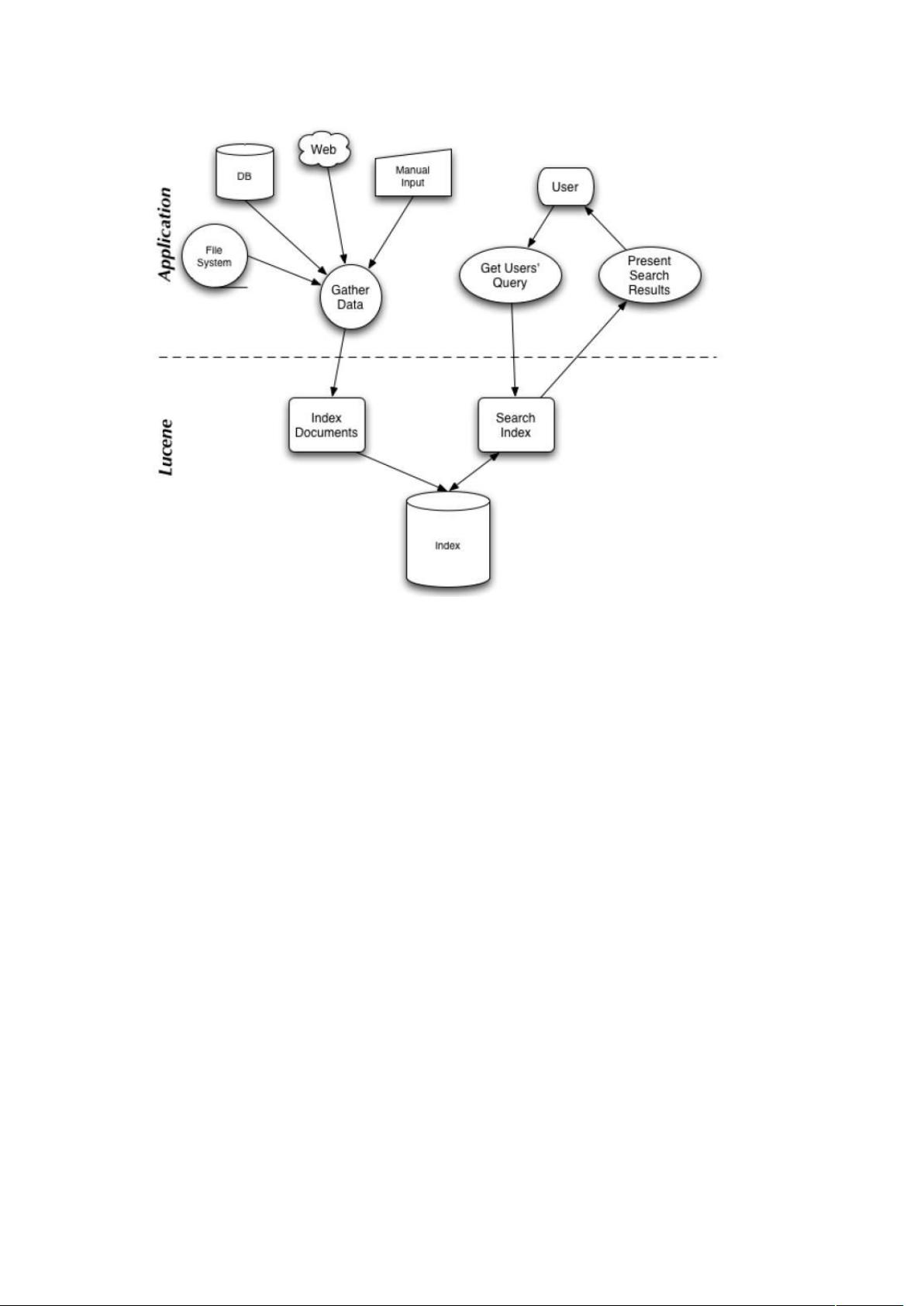
图 1 表示了搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序
的流程:
图 1. 搜索应用程序和 Lucene 之间的关系
剩余6页未读,继续阅读
资源评论













