
一,为什么要冗余数据
互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。
水平切分会有一个 patition key,通过 patition key 的查询能够直接定位到库,但是非 patition key 上的查询可
能就需要扫描多个库了。
此时常见的架构设计方案,是使用数据冗余这种反范式设计来满足分库后不同维度的查询需求。
例如:订单业务,对用户和商家都有订单查询需求:
Order(oid, info_detail);
T(buyer_id, seller_id, oid);
如果用 buyer_id 来分库,seller_id 的查询就需要扫描多库。
如果用 seller_id 来分库,buyer_id 的查询就需要扫描多库。
此时可以使用数据冗余来分别满足 buyer_id 和 seller_id 上的查询需求:
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以 buyer_id 来分库,满足买家的查询需求;一份以 seller_id 来分库,满足卖家的
查询需求。
如何实施数据的冗余,是今天将要讨论的内容。
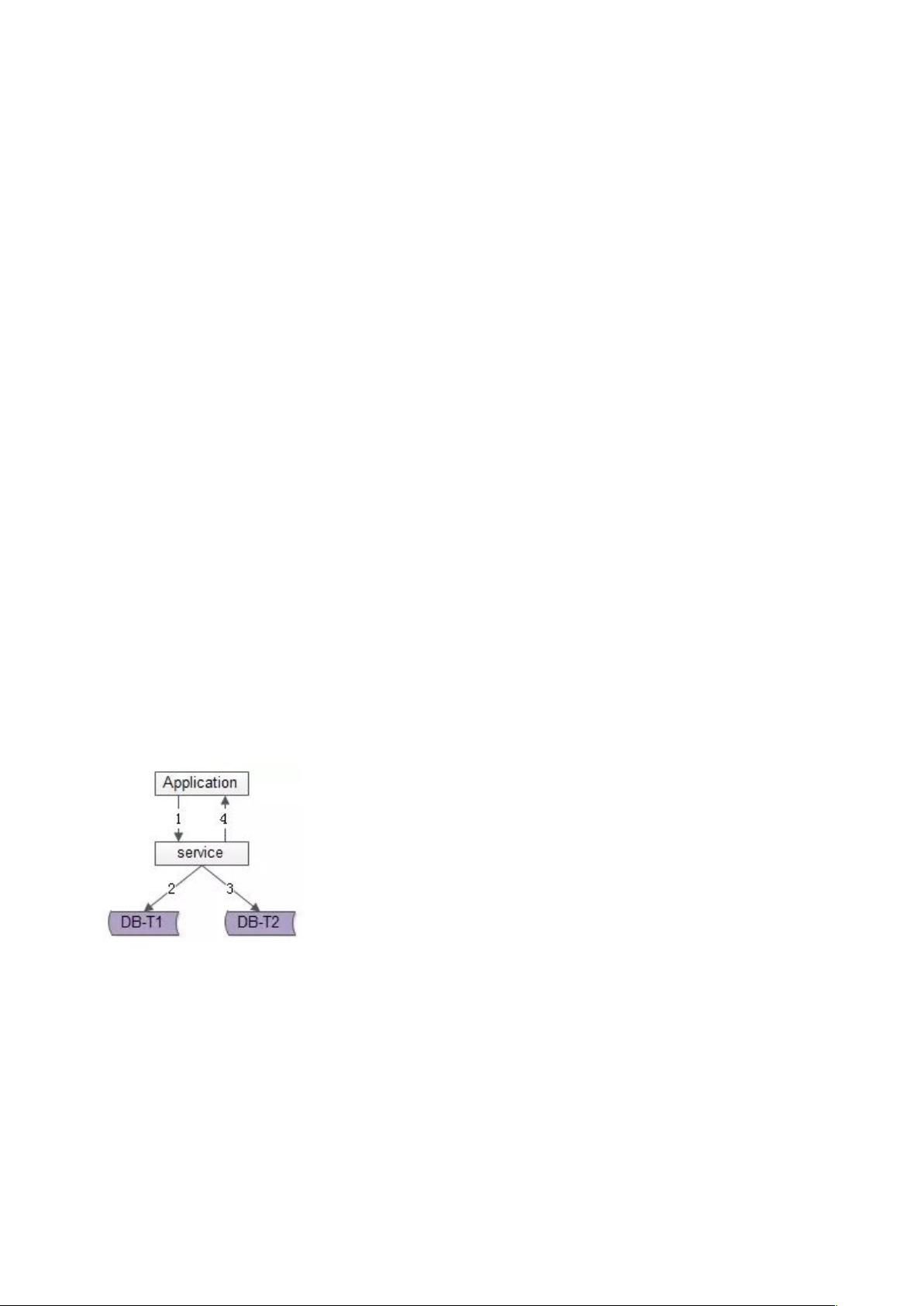
二,服务同步双写
顾名思义,由服务层同步写冗余数据,如上图 1-4 流程:
业务方调用服务,新增数据
服务先插入 T1 数据
服务再插入 T2 数据
服务返回业务方新增数据成功
优点:
不复杂,服务层由单次写,变两次写
数据一致性相对较高(因为双写成功才返回)
资源评论


hyy80688
- 粉丝: 10
- 资源: 202









最新资源
- 冒泡法排序c语言程序-day-3.26.rar
- 明清名医全书大成(陆懋修医学全书 ).pdf
- H5引流及后台调度系统
- 操作系统中银行家算法防止死锁定的资源管理机制
- 明清名医全书大成(沈金鳌医学全书 ).pdf
- 明清名医全书大成(唐容川医学全书 ).pdf
- 明清名医全书大成(汪昂医学全书 ).pdf
- 明清名医全书大成(汪石山医学全书 ).pdf
- 明清名医全书大成(万密斋医学全书 ).pdf
- java项目资源-atguigu-day16.rar
- 计算机科学中的经典排序算法-冒泡排序详解
- 明清名医全书大成(吴鞠通医学全书 ).pdf
- 明清名医全书大成(王孟英医学全书 ).pdf
- 明清名医全书大成(徐灵胎医学全书 ).pdf
- 明清名医全书大成(吴昆医学全书 ).pdf
- 明清名医全书大成(武之望医学全书 ).pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


