
一、缘起
《100 亿数据 1 万属性数据架构设计》文章发布后,不少朋友对 58 同城自研搜索引擎 E-search 比较感兴趣,故
专门撰文体系化的聊聊搜索引擎,从宏观到细节,希望把逻辑关系讲清楚,内容比较多,分上下两期。
主要内容如下,本篇(上)会重点介绍前三章:
(1)全网搜索引擎架构与流程
(2)站内搜索引擎架构与流程
(3)搜索原理、流程与核心数据结构
(4)流量数据量由小到大,搜索方案与架构变迁
(5)数据量、并发量、策略扩展性及架构方案
(6)实时搜索引擎核心技术
可能 99%的同学不实施搜索引擎,但本文一定对你有帮助。
二、全网搜索引擎架构与流程
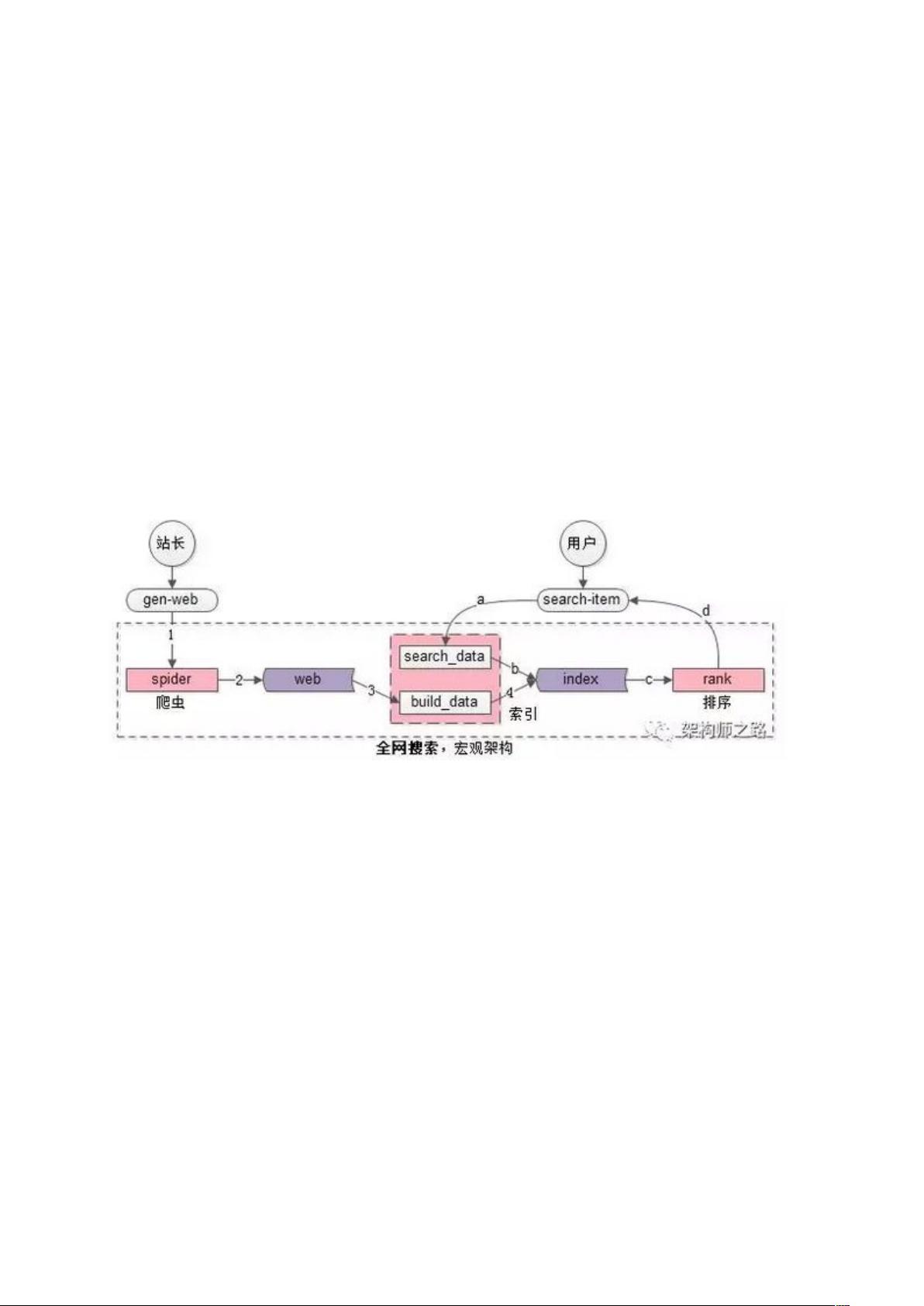
全网搜索的宏观架构长啥样?
全网搜索的宏观流程是怎么样的?
全网搜索引擎的宏观架构如上图,核心子系统主要分为三部分(粉色部分):
(1)spider 爬虫系统
(2)search&index 建立索引与查询索引系统,这个系统又主要分为两部分:
一部分用于生成索引数据 build_index
一部分用于查询索引数据 search_index
(3)rank 打分排序系统
核心数据主要分为两部分(紫色部分):
(1)web 网页库
(2)index 索引数据
全网搜索引擎的业务特点决定了,这是一个“写入”和“检索”完全分离的系统:
【写入】
系统组成:由 spider 与 search&index 两个系统完成
输入:站长们生成的互联网网页
输出:正排倒排索引数据
流程:如架构图中的 1,2,3,4
(1)spider 把互联网网页抓过来
(2)spider 把互联网网页存储到网页库中(这个对存储的要求很高,要存储几乎整个“万维网”的镜像)
(3)build_index 从网页库中读取数据,完成分词
资源评论













