

1
A Survey on Concept Drift Adaptation
JO
˜
AO GAMA, University of Porto, Portugal
INDR
˙
E
ˇ
ZLIOBAIT
˙
E, Aalto University, Finland
ALBERT BIFET, Yahoo! Research Barcelona, Spain
MYKOLA PECHENIZKIY, Eindhoven University of Technology, the Netherlands
ABDELHAMID BOUCHACHIA, Bournemouth University, UK
Concept drift primarily refers to an online supervised learning scenario when the relation between the in-
put data and the target variable changes over time. Assuming a general knowledge of supervised learning
in this paper we characterize adaptive learning process, categorize existing strategies for handling concept
drift, discuss the most representative, distinct and popular techniques and algorithms, discuss evaluation
methodology of adaptive algorithms, and present a set of illustrative applications. This introduction to the
concept drift adaptation presents the state of the art techniques and a collection of benchmarks for re-
searchers, industry analysts and practitioners. The survey aims at covering the different facets of concept
drift in an integrated way to reflect on the existing scattered state-of-the-art.
Categories and Subject Descriptors: I.2.6 [Artificial Intelligence]: Learning
General Terms: Design, Algorithms, Performance
Additional Key Words and Phrases: concept drift, change detection, adaptive learning
ACM Reference Format:
Gama, J.,
ˇ
Zliobait
˙
e, I., Bifet, A., Pechenizkiy, M., and Bouchachia, A. 2013. A Survey on Concept Drift Adap-
tation. ACM Comput. Surv. 1, 1, Article 1 (January 2013), 35 pages.
DOI = 10.1145/0000000.0000000 http://doi.acm.org/10.1145/0000000.0000000
1. INTRODUCTION
Our digital universe is rapidly growing. The volume of data generated in 2012 has
been estimated to surpass 2.8 zetabytes (2.8 trillion gigabytes) as reported in the IDC
survey [Gantz and Reinsel 2012]. Efficient and effective tools and analysis methods for
dealing with the ever-growing amount of data in different applications and fields are of
paramount need. Very often data comes in the form of streams rendering its analysis
and processing even more resource demanding.
Traditionally in data mining data is first collected and then processed in an offline
mode. For instance, predictive models are trained using historical data given as a set
of pairs (input, output). Models trained in such a way can be afterwards applied for
predicting the output for new unseen input data. However, streaming data can not be
processed similarly because data comes continuously over time and possibly is never-
ending. Accommodating such data in the machine’s main memory is impractical and
often infeasible. Hence, only an online processing is suitable. In this case, predictive
models can be trained either incrementally by continuous update or by retraining us-
ing recent batches of data.
In dynamically changing and non-stationary environments, the data distribution
can change over time yielding the phenomenon of concept drift [Schlimmer and
Granger 1986; Widmer and Kubat 1996]. The real concept drift
1
refers to changes in
the conditional distribution of the output (i.e., target variable) given the input (input
features), while the distribution of the input may stay unchanged. A typical example
of the real concept drift is a change in user’s interests when following an online news
stream. Whilst the distribution of the incoming news documents often remains the
same, the conditional distribution of the interesting (and thus not interesting) news
1
The term real refers to one particular type of concept drift. It doesn’t mean that other types of drift are not
concept drifts.
ACM Computing Surveys, Vol. 1, No. 1, Article 1, Publication date: January 2013.



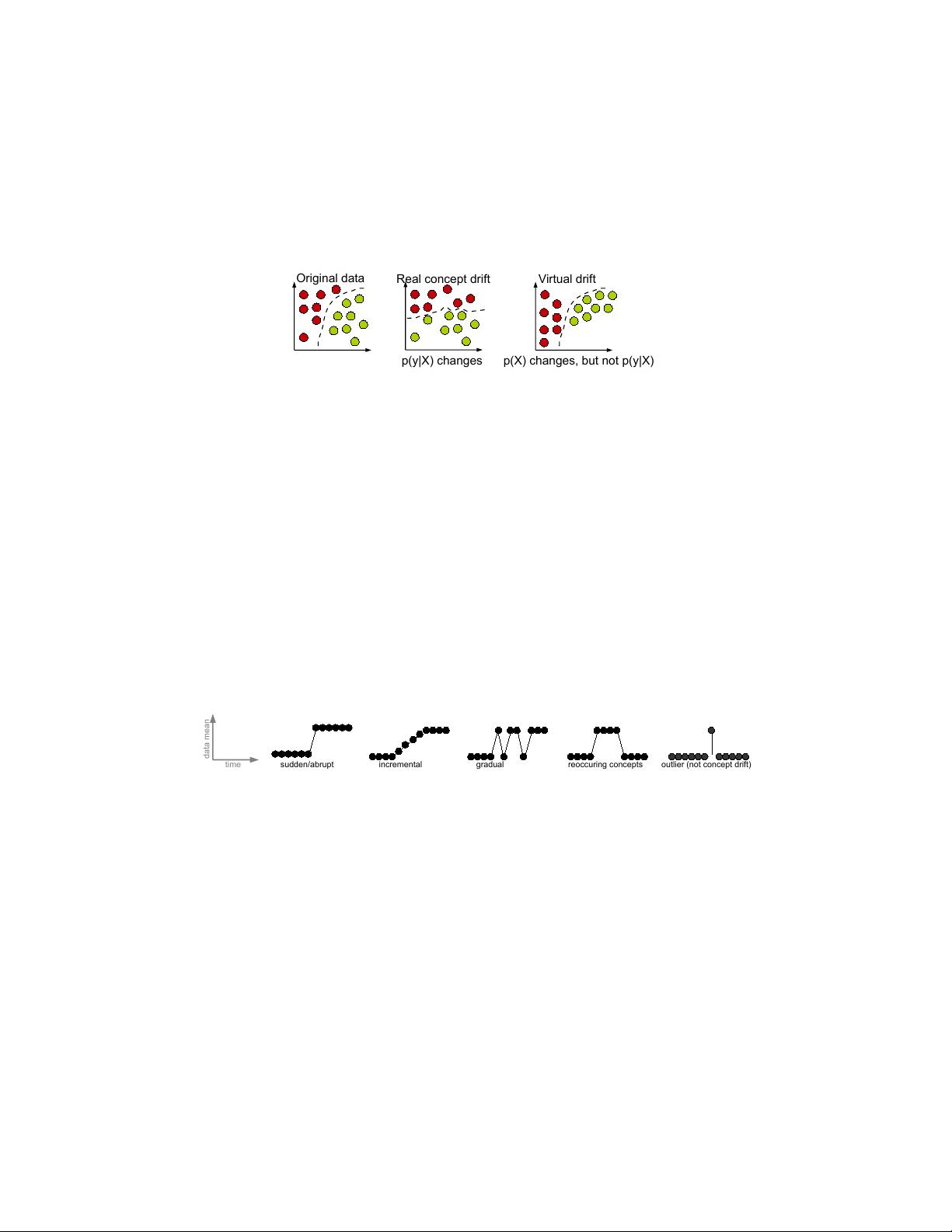
剩余43页未读,继续阅读
资源评论


hywcxq
- 粉丝: 0
- 资源: 33









最新资源
- 英语四级考试综合训练与听力阅读翻译解析
- 三相异步电机转子磁场定向矢量控制技术及其与弱磁控制的协同优化策略,三相异步电机转子磁场定向矢量控制与弱磁控制策略探究,三相异步电机转子磁场定向矢量控制与弱磁控制 ,三相异步电机; 转子磁场定向矢量控制
- 【java毕业设计】SpringBoot+Vue自习室预约管理系统(高级版) 源码+sql脚本+论文 完整版
- 字节面试题,包括一面和二面,vue和react
- 技术博客基于MATLAB Simulink的移相变压器仿真模型,模拟实现可调移相角度的变压器副边36脉波不控整流,MATLAB Simulink仿真模型实现可设置移相角度的变压器副边36脉波不控整
- 利用Bigemap Pro缓冲区工具实现地图发光效果
- 2025 Data+AI:智能数据架构与应用最佳实践合集.pdf
- Vue生命周期详解:从初始化到销毁的关键环节与应用
- 2018 蓝桥杯C语言b组国赛真题
- 软件测试实验三1111111111111111
- 直接复制,然后粘贴到assert下面
- 基于Springboot敬老院管理系统源码+22张表+100%可以运行使用+三端19个菜单/业务功能+vue前后分离使用Maven、Spingboot等技术
- PEM电解槽仿真模型分析,基于Comsol仿真的质子交换膜电解槽多物理场耦合模型:传热、多孔介质流动与极化性能分析,质子交膜(PEM)电解槽comsol仿真模型,耦合电解槽,传热,多孔介质流动物理场
- 欧姆龙CP1H与三菱E700变频器通讯程序:实现三台变频器频率设定与读取,稳定可靠扩展功能强大,欧姆龙CP1H与三菱E700变频器通讯程序:实现三台变频器频率设定与读取,稳定可靠扩展应用,欧姆龙CP1
- COMSOL仿真研究:斜入射圆偏振高斯光与金纳米线在衬底上的相互作用-模型构建与应用,Comsol模拟研究斜入射圆偏振高斯光在金纳米线与衬底结构上的作用:应用其模型解析交互机制 ,comsol仿真斜
- 高等数学教育中几何画板课件制作的实例指导与微课教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


