

Reversible Recurrent Neural Networks
Matthew MacKay, Paul Vicol, Jimmy Ba, Roger Grosse
University of Toronto
Vector Institute
{mmackay, pvicol, jba, rgrosse}@cs.toronto.edu
Abstract
Recurrent neural networks (RNNs) provide state-of-the-art performance in pro-
cessing sequential data but are memory intensive to train, limiting the flexibility
of RNN models which can be trained. Reversible RNNs—RNNs for which the
hidden-to-hidden transition can be reversed—offer a path to reduce the memory
requirements of training, as hidden states need not be stored and instead can be
recomputed during backpropagation. We first show that perfectly reversible RNNs,
which require no storage of the hidden activations, are fundamentally limited be-
cause they cannot forget information from their hidden state. We then provide a
scheme for storing a small number of bits in order to allow perfect reversal with
forgetting. Our method achieves comparable performance to traditional models
while reducing the activation memory cost by a factor of 10–15. We extend our
technique to attention-based sequence-to-sequence models, where it maintains
performance while reducing activation memory cost by a factor of 5–10 in the
encoder, and a factor of 10–15 in the decoder.
1 Introduction
Recurrent neural networks (RNNs) have attained state-of-the-art performance on a variety of tasks,
including speech recognition [
1
], language modeling [
2
,
3
], and machine translation [
4
,
5
]. However,
RNNs are memory intensive to train. The standard training algorithm is truncated backpropagation
through time (TBPTT) [
6
,
7
]. In this algorithm, the input sequence is divided into subsequences of
smaller length, say
T
. Each of these subsequences is processed and the gradient is backpropagated.
If H is the size of our model’s hidden state, the memory required for TBPTT is O(T H).
Decreasing the memory requirements of the TBPTT algorithm would allow us to increase the length
T
of our truncated sequences, capturing dependencies over longer time scales. Alternatively, we could
increase the size
H
of our hidden state or use deeper input-to-hidden, hidden-to-hidden, or hidden-to-
output transitions, granting our model greater expressivity. Increasing the depth of these transitions
has been shown to increase performance in polyphonic music prediction, language modeling, and
neural machine translation (NMT) [8, 9, 10].
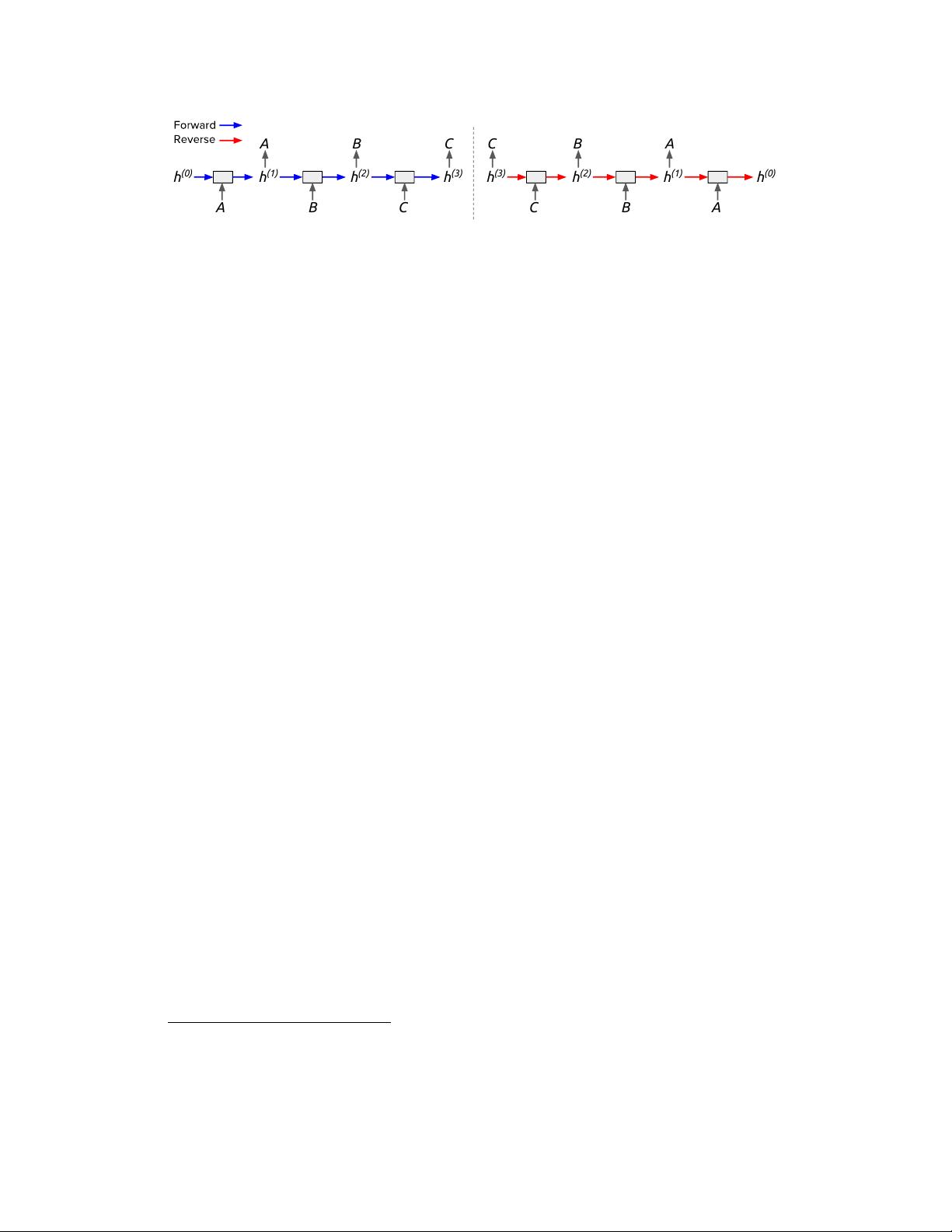
Reversible recurrent network architectures present an enticing way to reduce the memory requirements
of TBPTT. Reversible architectures enable the reconstruction of the hidden state at the current timestep
given the next hidden state and the current input, which would enable us to perform TBPTT without
storing the hidden states at each timestep. In exchange, we pay an increased computational cost to
reconstruct the hidden states during backpropagation.
We first present reversible analogues of the widely used Gated Recurrent Unit (GRU) [
11
] and Long
Short-Term Memory (LSTM) [
12
] architectures. We then show that any perfectly reversible RNN
requiring no storage of hidden activations will fail on a simple one-step prediction task. This task is
trivial to solve even for vanilla RNNs, but perfectly reversible models fail since they need to memorize
the input sequence in order to solve the task. In light of this finding, we extend the memory-efficient
32nd Conference on Neural Information Processing Systems (NIPS 2018), Montréal, Canada.
arXiv:1810.10999v1 [cs.LG] 25 Oct 2018



剩余30页未读,继续阅读
资源评论













