基本原理:
第一部分:目前 Hadoop1.0 架构的问题
单点故障
•如果 NameNode 或者 JobTraker 关掉,那么整个集群瘫痪。
•对于 7×24 生产环境,是具有极大的风险。
第二部分:常见的 HA 方案
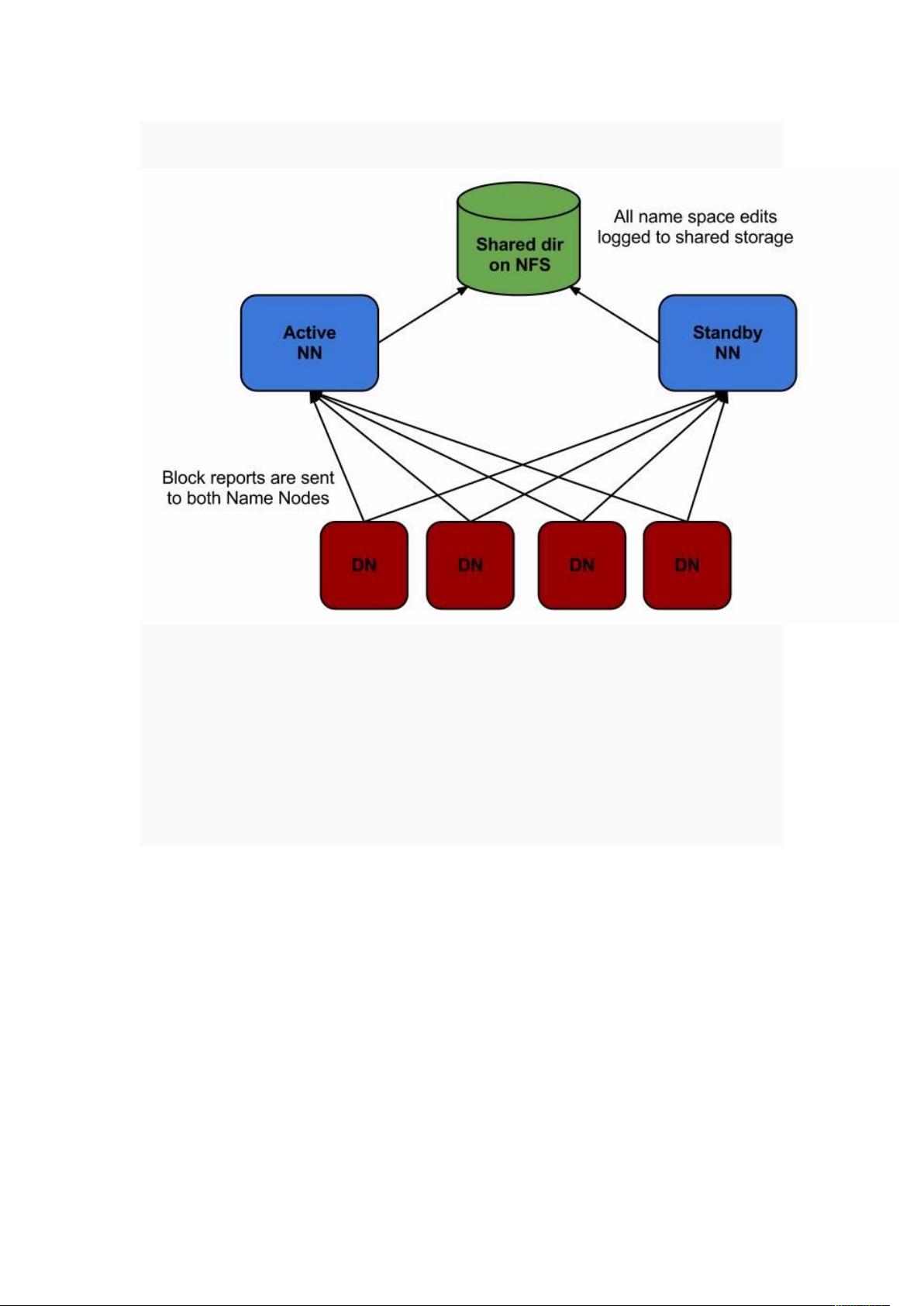
•第一种是可以设置一个 NFS 的目录,存储 fsimage 和 editlog,存储的是实时数据,这样当
namenode 挂掉后能够通过 fsimage 和 editlog 进行完全恢复。
•第二种是设置 Secondary Namenode。
•问题:不能迅速的切换,需要花费一定时间恢复。
FaceBook 的方案
•不改变 namenode 和 datanode 整体逻辑的基础上,在其上层开发出 AvaterNode,AvatarNode 的
意思就是支持互相切换。
•提供一个 Primary Avatar 和一个 Standby Avatar,通过 virual IP 来设置 IP 地址。
•Primary Avatar 对外提供服务,设置了 NFS 目录,将 FSImage 和 EditLog 远程存储。Standby
Avatar 将 NFS 目录中的 FSImage 和 EditLog 读取过来进行同步,并且设置 Standby Avatar 一直处于
safemode 状态,不影响正常操作。这样 Standby Avatar 相当于一个热拷贝,获得了所有的实时数据。















- 1
- 2
前往页