

1545-5971 (c) 2019 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TDSC.2019.2954088, IEEE
Transactions on Dependable and Secure Computing
1
Software Vulnerability Discovery via Learning
Multi-domain Knowledge Bases
Guanjun Lin, Jun Zhang*, Senior Member, IEEE, Wei Luo, Lei Pan, Member, IEEE,
Olivier De Vel, Paul Montague, and Yang Xiang Senior Member, IEEE
Abstract—Machine learning (ML) has great potential in automated code vulnerability discovery. However, automated discovery
application driven by off-the-shelf machine learning tools often performs poorly due to the shortage of high-quality training data. The
scarceness of vulnerability data is almost always a problem for any developing software project during its early stages, which is referred
to as the cold-start problem. This paper proposes a framework that utilizes transferable knowledge from pre-existing data sources. In
order to improve the detection performance, multiple vulnerability-relevant data sources were selected to form a broader base for
learning transferable knowledge. The selected vulnerability-relevant data sources are cross-domain, including historical vulnerability
data from different software projects and data from the Software Assurance Reference Database (SARD) consisting of synthetic
vulnerability examples and proof-of-concept test cases. To extract the information applicable in vulnerability detection from the
cross-domain data sets, we designed a deep-learning-based framework with Long-short Term Memory (LSTM) cells. Our framework
combines the heterogeneous data sources to learn unified representations of the patterns of the vulnerable source codes. Empirical
studies showed that the unified representations generated by the proposed deep learning networks are feasible and effective, and are
transferable for real-world vulnerability detection. Our experiments demonstrated that by leveraging two heterogeneous data sources,
the performance of our vulnerability detection outperformed the static vulnerability discovery tool Flawfinder. The findings of this paper
may stimulate further research in ML-based vulnerability detection using heterogeneous data sources.
Index Terms—Vulnerability detection, Representation Learning, Deep learning.
F
1 INTRODUCTION
Many cybersecurity incidents and data breaches are caused
by exploitable vulnerabilities in software [21, 41]. Discov-
ering and detecting software vulnerabilities has been an
important research direction. Automated techniques such as
rules-based analysis [9, 47], symbolic execution [4], and fuzz
testing [42] have been proposed to enhance the vulnerability
search. However, these techniques are inefficient when used
on a large code base in practice [48]. To improve efficiency,
machine learning (ML) techniques were applied to automate
the detection of software vulnerabilities and to accelerate the
code inspection process.
ML algorithms are capable of learning latent patterns
indicative of vulnerable/defective code, potentially outper-
forming the rules derived from experience, with a signifi-
cantly improved level of generalization. Nevertheless, the
application of traditional ML techniques to vulnerability
detection still requires human experts to define features,
which largely relies on human experience, level of expertise
and depth of domain knowledge [18]. With deep learning,
code fragments can be directly used for learning without
the need for manual feature extraction and thus relieving
Jun Zhang is the corresponding author.
Guanjun Lin, Jun Zhang, and Yang Xiang are with School of Software and
Electrical Engineering, Swinburne University of Technology, Melbourne, VIC
3122, Australia (e-mail: {glin, junzhang, yxiang}@swin.edu.au)
Wei Luo and Lei Pan are with School of Information Technology,
Deakin University, Geelong, VIC 3216, Australia (e-mail: {wei.luo,
l.pan}@deakin.edu.au).
Olivier De Vel and Paul Montague are with the Defence Science & Technology
Group (DSTG), Department of Defence, Australia (e-mail:{Olivier.DeVel,
Paul.Montague}@dst.defence.gov.au)
experts from the time-consuming and possibly error-prone
feature engineering tasks. Recent studies have utilized neu-
ral networks for automated learning of semantic feature [45]
and high-level representations [18, 20] that could indicate
potential vulnerabilities in Java and C/C++ source code.
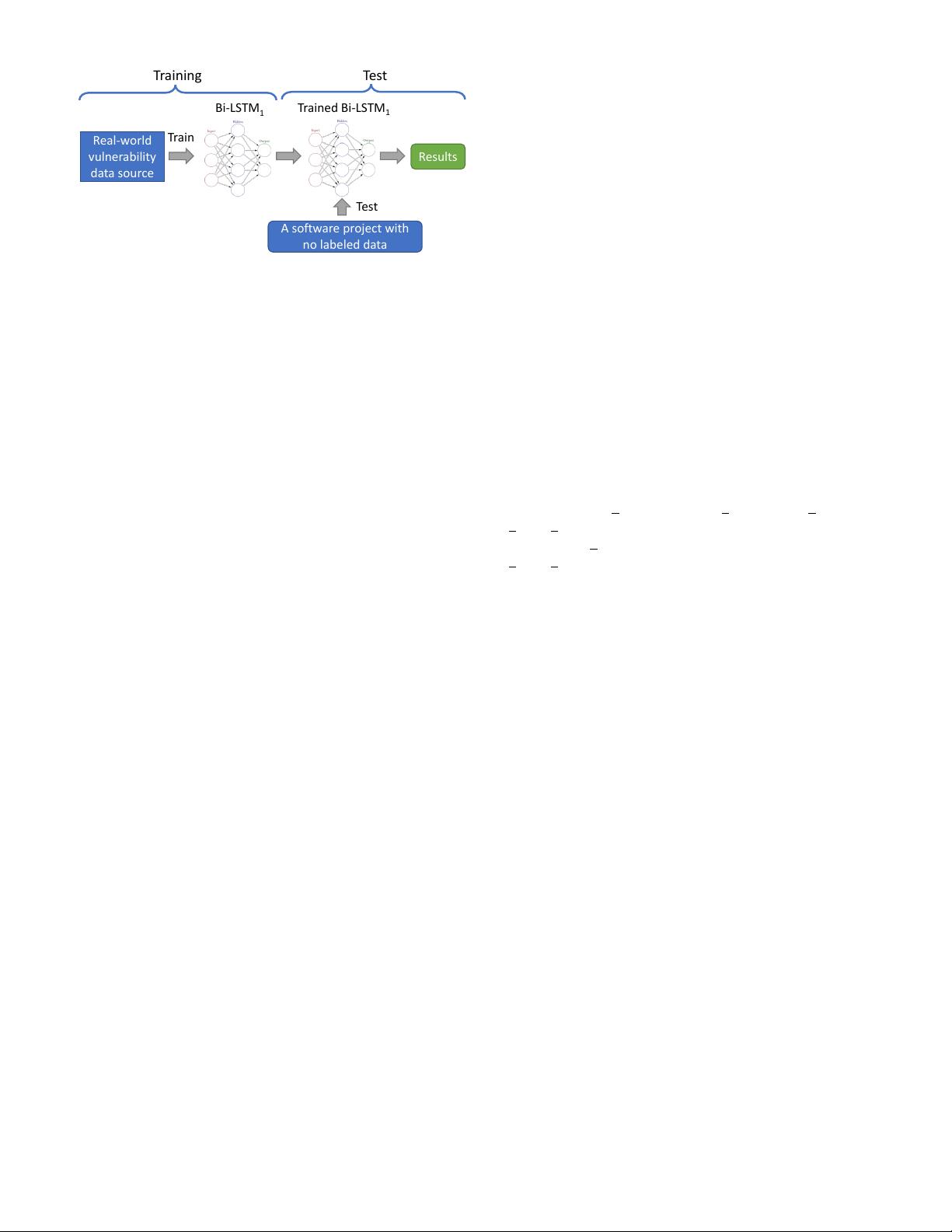
However, the existing ML-based vulnerability/defect
detection approaches, such as [18, 45, 53], have been con-
structed based on the assumption of the availability of suf-
ficient labeled training data from the homogeneous sources.
Unfortunately, this assumption is not always valid. There
are no known publicly available software vulnerability
repositories that provide real-world vulnerability data with
code and label pairs [18, 20]. The relative scarcity of real-
world vulnerability data exacerbates the shortcomings of
the existing ML-based solutions on real-world software
projects, especially for the software projects with a few
historical instances of the detected vulnerabilities. Due to
the expensive process of manual software vulnerability col-
lection, the lack of training data causes the supervised ML-
based vulnerability detection approaches to be challenging
to apply. Hence, in practice, manual efforts are still required
for the vulnerability discovery task [44].
To enhance the automation of software vulnerability
discovery, we propose a deep learning based framework
with the capability of leveraging multiple heterogeneous
vulnerability-relevant data sources for effectively and auto-
matically learning latent vulnerable programming patterns.
On the one hand, the automated learning of vulnerable
programming patterns can relieve human experts of the
tedious and error-prone feature engineering tasks. On the
other hand, the learned latent representations of the vul-

剩余16页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2874
- 资源: 4045









最新资源
- 小伊工具箱小程序源码/趣味工具微信小程序源码
- 网络安全领域中关于防范钓鱼邮件导致的病毒入侵与应对措施探讨
- Build a Large Language Model - 2025
- 郑州升达大学2024-2025第一学期计算机视觉课程期末试卷,
- ztsc_109339.apk
- boost电路电压闭环仿真 有pi控制和零极点补偿器两种 仿真误差0.00705,仿真波形如图二所示 所搭建的模型输入电压5V,输出电压24伏
- COMSOL模拟动水条件联系裂隙注浆扩散,考虑粘度时变
- 学生信息管理系统,该程序用于管理学生的基本信息,包括姓名、年龄、性别和成绩 用户可以添加、删除、修改和查询学生信息
- XC7V2000T+TMS320C6678设计文件,包含原理图,PCB等文件,已验证,可直接生产
- 简易图书管理系统,该程序用于管理图书的基本信息,包括书名、作者、出版年份和库存数量 用户可以添加、删除、修改和查询图书信息
- 简易日程提醒系统, 该程序用于管理用户的日程提醒,包括事件名称、日期、时间和描述 用户可以添加、删除、修改和查询日程提醒
- 无线充电仿真 simulink 磁耦合谐振 无线电能传输 MCR WPT lcc ss llc拓扑补偿 基于matlab 一共四套模型: 1.llc谐振器实现12 24V恒压输出 带调频闭环控制 附
- 直流无刷电机,直径38mm,径向长23.8mm,转速25000rpm,功率200W,可用于磨头加工
- 47191 Python语言程序设计(第2版)(含视频教学)-课后习题答案.zip
- 信息系统管理师试题分享
- FreeRTOS学习之系统移植
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


