Pandas Cheat Sheet

需积分: 0 132 浏览量
更新于2017-04-01
收藏 669KB PDF 举报
### Pandas Cheat Sheet详解
#### 一、简介
Pandas 是 Python 中用于数据分析的一个非常强大的库,它提供了高性能且易用的数据结构与数据分析工具。Pandas 的核心数据结构包括 `Series` 和 `DataFrame`,它们使得处理数据变得更加简单高效。
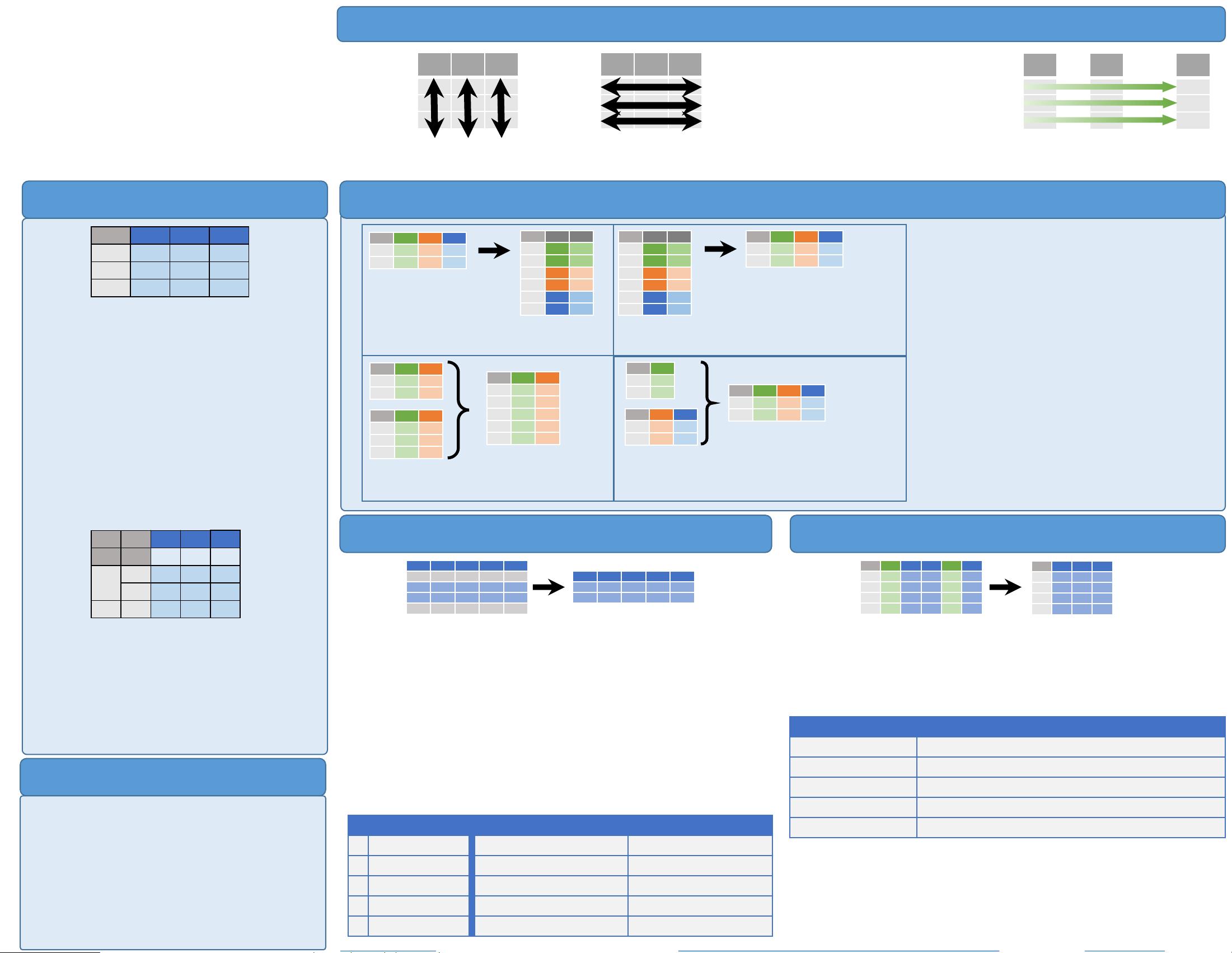
#### 二、创建 DataFrame
在 Pandas 中创建 DataFrame 的方式有很多种:
1. **指定每列的值**:
```python
df = pd.DataFrame({"a": [4, 5, 6], "b": [7, 8, 9], "c": [10, 11, 12]}, index=[1, 2, 3])
```
这种方式直接指定了每列的值,并且可以自定义索引。
2. **指定每行的值**:
```python
df = pd.DataFrame([[4, 7, 10], [5, 8, 11], [6, 9, 12]], index=[1, 2, 3], columns=['a', 'b', 'c'])
```
此方式通过列表的形式指定每行的值,并同样可以自定义索引和列名。
3. **创建具有 MultiIndex 的 DataFrame**:
```python
df = pd.DataFrame({"a": [4, 5, 6], "b": [7, 8, 9], "c": [10, 11, 12]},
index=pd.MultiIndex.from_tuples([('d', 1), ('d', 2), ('e', 2)], names=['n', 'v']))
```
MultiIndex 可以让 DataFrame 具有多层索引,适合处理具有多维层次的数据。
#### 三、数据整理(Tidy Data)
Tidy data 是一种数据格式,其基本原则是:
- 每个变量都保存在自己的列中。
- 每个观测值都保存在自己的行中。
这样的格式非常适合使用 Pandas 进行数据操作,因为 Pandas 支持向量化运算,能够自动保持观测值不变,而仅对变量进行操作。这种数据格式可以极大地提高数据处理的效率。
#### 四、重塑数据(Reshaping Data)
在 Pandas 中,重塑数据是指改变数据集的布局或形状。常见的操作包括:
- **收集列到行**:
```python
pd.melt(df)
```
此方法将多列转换为单列,并将剩余的列作为标识符。
- **展开行到列**:
```python
df.pivot(columns='var', values='val')
```
此方法将特定列的值作为新的列名,并将其他列的值填充到新列中。
- **追加 DataFrame 的行**:
```python
pd.concat([df1, df2])
```
将两个 DataFrame 的行进行拼接。
- **追加 DataFrame 的列**:
```python
pd.concat([df1, df2], axis=1)
```
将两个 DataFrame 的列进行拼接。
#### 五、排序和重命名
- **按列排序**:
```python
df = df.sort_values('mpg')
df = df.sort_values('mpg', ascending=False)
```
对 DataFrame 按照某列的值进行升序或降序排序。
- **重命名列**:
```python
df = df.rename(columns={'y': 'year'})
```
重命名 DataFrame 中的列名。
- **排序索引**:
```python
df = df.sort_index()
```
对 DataFrame 的索引进行排序。
- **重置索引**:
```python
df = df.reset_index()
```
重置 DataFrame 的索引,将原有的索引移到列中,并使用默认的整数索引。
- **删除列**:
```python
df = df.drop(['Length', 'Height'], axis=1)
```
删除 DataFrame 中的指定列。
#### 六、子集选择
- **子集观测值(行)**:
```python
df[df.Length > 7]
```
提取满足逻辑条件的行。
- **子集变量(列)**:
```python
df[['a', 'b']]
```
提取 DataFrame 中的指定列。
#### 七、逻辑操作
Pandas 中支持多种逻辑操作,例如:
- `<`: 小于
- `!=`: 不等于
- `>`: 大于
这些逻辑操作可以用于筛选数据。
#### 八、方法链式调用
Pandas 的方法通常会返回一个新的 DataFrame,这意味着可以在一次表达式中连续调用多个方法,提高代码的可读性。例如:
```python
df = (pd.melt(df)
.rename(columns={'variable': 'var', 'value': 'val'})
.query('val >= 200')
)
```
#### 九、去除重复值
- **去除重复行**:
```python
df.drop_duplicates()
```
去除 DataFrame 中重复的行,默认情况下只考虑列值。
#### 十、获取数据片段
- **选取前 n 行**:
```python
df.head(n)
```
获取 DataFrame 的前 n 行。
- **选取后 n 行**:
```python
df.tail(n)
```
获取 DataFrame 的后 n 行。
Pandas Cheat Sheet 总结了 Pandas 库中的一些常用功能和操作,对于初学者来说是非常有用的参考资料。掌握了这些基本操作之后,就可以更加高效地处理和分析数据了。
F M A
Data Wrangling
with pandas
Cheat Sheet
http://pandas.pydata.org
Syntax – Creating DataFrames
Tidy Data – A foundation for wrangling in pandas
In a tidy
data set:
F M A
Each variable is saved
in its own column
&
Each observation is
saved in its own row
Tidy data complements pandas’s vectorized
operations. pandas will automatically preserve
observations as you manipulate variables. No
other format works as intuitively with pandas.
Reshaping Data – Change the layout of a data set
M A F
*
M A
*
pd.melt(df)
Gather columns into rows.
df.pivot(columns='var', values='val')
Spread rows into columns.
pd.concat([df1,df2])
Append rows of DataFrames
pd.concat([df1,df2], axis=1)
Append columns of DataFrames
df=df.sort_values('mpg')
Order rows by values of a column (low to high).
df=df.sort_values('mpg',ascending=False)
Order rows by values of a column (high to low).
df=df.rename(columns = {'y':'year'})
Rename the columns of a DataFrame
df=df.sort_index()
Sort the index of a DataFrame
df=df.reset_index()
Reset index of DataFrame to row numbers, moving
index to columns.
df=df.drop(['Length','Height'], axis=1)
Drop columns from DataFrame
Subset Observations (Rows) Subset Variables (Columns)
a
b
c
1
4
7
10
2
5
8
11
3
6
9
12
df = pd.DataFrame(
{"a" : [4 ,5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = [1, 2, 3])
Specify values for each column.
df = pd.DataFrame(
[[4, 7, 10],
[5, 8, 11],
[6, 9, 12]],
index=[1, 2, 3],
columns=['a', 'b', 'c'])
Specify values for each row.
a
b
c
n
v
d
1
4
7
10
2
5
8
11
e
2
6
9
12
df = pd.DataFrame(
{"a" : [4 ,5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = pd.MultiIndex.from_tuples(
[('d',1),('d',2),('e',2)],
names=['n','v'])))
Create DataFrame with a MultiIndex
Method Chaining
Most pandas methods return a DataFrame so that
another pandas method can be applied to the
result. This improves readability of code.
df = (pd.melt(df)
.rename(columns={
'variable' : 'var',
'value' : 'val'})
.query('val >= 200')
)
df[df.Length > 7]
Extract rows that meet logical
criteria.
df.drop_duplicates()
Remove duplicate rows (only
considers columns).
df.head(n)
Select first n rows.
df.tail(n)
Select last n rows.
Logic in Python (and pandas)
<
Less than
!=
Not equal to
>
Greater than
df.column.isin
(values)
Group membership
==
Equals
pd.isnull
(obj)
Is
NaN
<=
Less than or equals
pd.notnull
(obj)
Is not
NaN
>=
Greater than or equals
&,|,~,^,
df.any(),df.all()
Logical
and, or, not, xor, any, all
http://pandas.pydata.org/ This cheat sheet inspired by Rstudio Data Wrangling Cheatsheet (https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf) Written by Irv Lustig, Princeton Consultants
df[['width','length','species']]
Select multiple columns with specific names.
df['width'] or df.width
Select single column with specific name.
df.filter(regex='regex')
Select columns whose name matches regular expression regex.
df.loc[:,'x2':'x4']
Select all columns between x2 and x4 (inclusive).
df.iloc[:,[1,2,5]]
Select columns in positions 1, 2 and 5 (first column is 0).
df.loc[df['a'] > 10, ['a','c']]
Select rows meeting logical condition, and only the specific columns .
regex (Regular Expressions) Examples
'
\.'
Matches strings containing
a period '.'
'Length$'
Matches strings ending with word 'Length'
'^Sepal'
Matches strings beginning with the word 'Sepal'
'^x[1
-5]$'
Matches strings beginning with 'x' and ending with 1,2,3,4,5
''^(?!Species$).*'
Matches strings except
the string 'Species'
df.sample(frac=0.5)
Randomly select fraction of rows.
df.sample(n=10)
Randomly select n rows.
df.iloc[10:20]
Select rows by position.
df.nlargest(n, 'value')
Select and order top n entries.
df.nsmallest(n, 'value')
Select and order bottom n entries.
下载后可阅读完整内容,剩余1页未读,立即下载
167 浏览量
2018-07-26 上传
173 浏览量
131 浏览量
2019-08-28 上传
2019-09-25 上传
110 浏览量
168 浏览量
151 浏览量
2017-11-28 上传
2017-11-21 上传
2025-02-02 上传
111 浏览量
124 浏览量
2025-02-08 上传
167 浏览量
2025-01-29 上传
资源评论


侯沂伯
- 粉丝: 33
- 资源: 66









最新资源
- 基于SSM商城系统.zip
- 毕业生离校管理系统.zip
- 博客系统毕业设计.zip
- 超市管理系统高级版v2.zip
- 房屋租赁管理信息系统v2.zip
- 进销存或库存管理系统.zip
- 智能桌面宠物完整资料.zip
- IEEE标准节点仿真模型系列:涵盖多种配置,潮流计算已调试完毕,适用于短路仿真与电能质量研究,IEEE标准节点仿真模型系列:潮流计算及扩展应用,IEEE标准节点仿真模型 1、IEEE2机5节点 2、
- 计算机毕业设计源码:基于Java的小说中敏感词识别系统设计与实现.zip关注博主
- 《无线通信》 AndreaGoldsmith、杨鸿文等译
- 三种版本的redis软件包
- report547769026951657921.pdf
- 基于 DeepSeek-Coder 代码漏洞检测与修复的 Python 源码
- 语音转文字模型测试demo(linux)
- 面向能源系统的深度强化学习算法性能比较及最优调度策略代码实践,能源系统深度强化学习算法性能比较及最优调度策略代码实践,面向能源系统深度强化学习算法的性能比较 最优调度(代码) ,面向能源系统;深度强化
- spider for learning (died)
