
# 使用词嵌入计算文本相似性
## 简介
- 利用词嵌入实现文本之间的相似性计算等操作。
## 词嵌入
- 在自然语言处理中,对字符的研究往往没有对单词的研究来的有意义,因为在自然语言中语义的基本单位是词而不是字(绝大多数语言中语义的依赖基本单位是词),如何表示词就成了一个比较棘手的问题。
- 词的表示大体有两种,分别是one-hot encoding(独热编码)和word embedding(词嵌入),前者基于整个词表,文本中出现该词则该词对应位置置为1否则为0;后者有多种实现方式,但是一般分为基于频率和基于预测两种,word2vec是基于预测的词向量方法之一。
- 不同于one-hot的高维特点,词嵌入形成的向量往往维度较低且相似词的词向量是接近的。
- 本项目主要使用的是Google版本的Word2vec,事实上,这并不是一个深度模型,因为它只是一个词到词向量的查询表而已,它诞生于Google新闻的以句子上下文预测单词的训练网络中,是一个副产品。
## 预训练词嵌入查看文本相似性
- 步骤
- 确定词嵌入加载工具
- 使用预训练的词嵌入,使用gensim进行模型加载,gensim是一个常用的Python主题建模库(需要安装)。
- 下载预训练模型
- 各个平台都提供了不错的词嵌入预训练模型,这里使用Google新闻这个模型,它有300万个汽车人,并用大约1000亿个摘自Google新闻档案的单词训练过([下载地址](https://deeplearning4jblob.blob.core.windows.net/resources/wordvectors/GoogleNews-vectors-negative300.bin.gz)),模型大约5G,下载需要一定时间。
- 加载预训练模型
- 使用gensim加载模型
- ```python
model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
```
- 查看与给定单词最接近的单词
- ```python
model.most_similar(positive=['beijing'])
```
- 
- 结论
- 词嵌入以相似单词距离近的方式,将n维向量与词表中每个单词联系起来。寻找相似的单词使用的是基于距离的近邻搜索。word2vec是嵌入是通过训练神经网络从上下文中预测单词而得到的,因此,让网络预测在一系列片段中应该选择哪个词来填充上下文中缺少的单词,这样,那些可被插入相似模式的单词将会得到彼此靠近一些的向量(如地点类名词在一个语义的句子中可以替换填充)。不关心是的任务,只关心分配的权重,所说词嵌入是训练这个网络得到的一个副产品。
## Word2vec的数学特性
- 利用word2vec模型的语义特性,很容易回答“A与B的关系和C与谁的关系相似”的问题,例如king与son的关系与daughter与哪个单词的关系类比上很接近。
- 封装函数
- ```python
def A_is_to_B_as_C_is_to_which(a, b, c, topn=1, model=None):
a, b, c = map(lambda x:x if type(x) == list else [x], (a, b, c)) # 封装为list
res = model.most_similar(positive=b + c, negative=a, topn=topn)
if len(res):
if topn == 1:
return res[0][0]
else:
return [x[0] for x in res]
return None
```
- 测试结果
- 
- 结论
- 这并不难理解,词嵌入对词语的含义进行编码,它包含了词语之间的差异。取"son"的向量并减去"daughter"的向量,最终的差异可以理解为从"儿子到女儿"甚至"从男性到女性",在"king"上面加上这个差异,得到"queen"并没有太过出乎意料。
## 可视化词嵌入
- 可视化一个300维的空间时非常困难的,比较不是(x,y)这样的二维空间,幸运的是通过t分布随机邻域嵌入(t-SNE)算法可以把更高维度的空间折叠成更容易理解的低维空间。
- 假设初始化三类词语,获得所有词的词嵌入。利用tsne降低维度空间,使用二维平面绘制三点得到可视化结果。
- 代码
- ```python
beverages = ['espresso', 'beer', 'vodka', 'wine', 'cola', 'tea']
countries = ['Italy', 'Germany', 'Russia', 'France', 'USA', 'India']
sports = ['soccer', 'handball', 'hockey', 'cycling', 'basketball', 'cricket']
items = beverages + countries + sports
item_vectors = [(item, model[item]) for item in items if item in model]
vectors = np.asarray([x[1] for x in item_vectors])
lengths = np.linalg.norm(vectors, axis=1)
norm_vectors = (vectors.T / lengths).T
tsne = TSNE(n_components=2, perplexity=10, verbose=2).fit_transform(norm_vectors)
x=tsne[:,0]
y=tsne[:,1]
plt.figure(figsize=(16, 8))
fig, ax = plt.subplots()
ax.scatter(x, y)
for item, x1, y1 in zip(item_vectors, x, y):
ax.annotate(item[0], (x1, y1), size=14)
plt.show()
```
- 演示结果
- 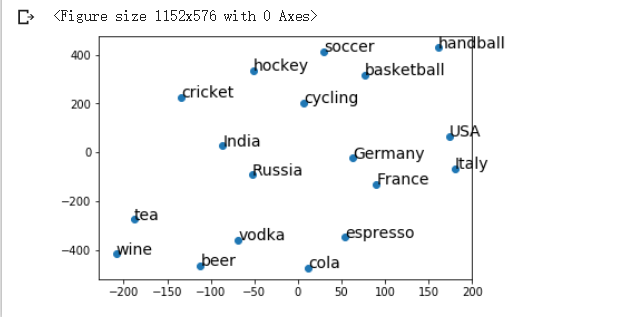
- 结论
- 这进一步说明词嵌入描述的单词之间是有“远近”这一含义的。
- t-SNE是一个只智能算法,你给他一组高维空间的向量,它反复迭代直到找到低维空间的最优投影,在低维空间尽可能保持各个向量之间的距离,非常适合于可视化词嵌入这样的高维空间。
## 词嵌入中发现实体类
- 通常,在高维空间中有一些只包含一类实体的子空间,很难寻找到。例如搜索德国类似的事物,得到下图答案。结果中有部分国家但也有部分“德国人”和德国城市的名词 ,有一个思路就是将部分国家的向量加起来得到一个“国家”的概念向量,这种思路就很离谱了,在词嵌入的空间里,“国家”显然不是一个向量,而是包含很多向量的高维空间,因此需要的其实是一个分类器。事实证明SVM(支持向量机)对这类任务效果不错,在确定模型后构建数据集放入部分正例和反例即可(正例从csv文件读取单词后得到词向量负例从词表随机抽取单词)。
- 
- 代码
- ```python
from sklearn import svm
TRAINING_FRACTION = 0.3
cut_off = int(TRAINING_FRACTION * len(labelled))
clf = svm.SVC(kernel='linear')
clf.fit(X[:cut_off], y[:cut_off])
```
- 结论
- 尽管模型的预测有一些疏漏,但是大部分还是识别正确了。
- 在词嵌入这样的高维空间中寻找类簇时,SVM是个有效的工具,通过寻找正例负例划分开的超平面工作。
## 类内部语义距离
- 当通过一些方法获得一个类簇如国家,有时希望计算得到同一个类内部每个词的语义距离并排序。
- 代码
- ```python
def rank_countries(term, topn=10, field='name'):
if not term in model:
return []
vec = model[term]
dists = np.dot(country_vecs, vec)
return [(countries[idx][field], float(dists[idx]))
for idx in reversed(np.argsort(dists)[-topn:])]
```
- 演示结果
- 
- 结论
- 由于训练语料来自Google新闻,整体而言,距离最近的单词还是合理的。
## 可视化国家数据
- GeoPandas是一个地图可视化数值数据的不错工具,利用其可以方便的可视化地图数据。
- 代码
- ```python
import matplotlib.pyplot as plt
from IPython.core.pylabtools import figsize
%matplotlib inline
figsize(12, 8)
def map_term(term):
d = {k.upper(): v for k, v in rank_countries(term, topn=0, field='cc3')}
world[term] = world['iso_a3'].map(d)
world[term] /= world[term].max()
world.dropna().plot(term, cmap='OrRd')
map_term('coffee')
```
- 演示结果
- 
- 结论
- 语义接近给定语义的单词的国家被高亮显示。
 深度学习实战项目:使用词嵌入对文本相似性进行检测(含源码、数据集、说明文档).zip (3个子文件)
深度学习实战项目:使用词嵌入对文本相似性进行检测(含源码、数据集、说明文档).zip (3个子文件)  source TextSimilarity data
source TextSimilarity data  countries.csv 3KB TextSimilarity.ipynb 121KB README.md 8KB
countries.csv 3KB TextSimilarity.ipynb 121KB README.md 8KB资源评论


一只会写程序的猫
- 粉丝: 1w+
- 资源: 866









最新资源
- (源码)基于Spring Boot和Vue的高性能售票系统.zip
- (源码)基于Windows API的USB设备通信系统.zip
- (源码)基于Spring Boot框架的进销存管理系统.zip
- (源码)基于Java和JavaFX的学生管理系统.zip
- (源码)基于C语言和Easyx库的内存分配模拟系统.zip
- (源码)基于WPF和EdgeTTS的桌宠插件系统.zip
- (源码)基于PonyText的文本排版与预处理系统.zip
- joi_240913_8.8.0_73327_share-2EM46K.apk
- Library-rl78g15-fpb-1.2.1.zip
- llvm-17.0.1.202406-rl78-elf.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


