

设计并实现数据仓库 ETL 过程(IBM 讲座)
本文是关于计划、设计和实现基本数据仓库解决方案的系列文章的第 部分,
将设计和实现仓库 过程,并了解仓库的性能和安全问题。
简介
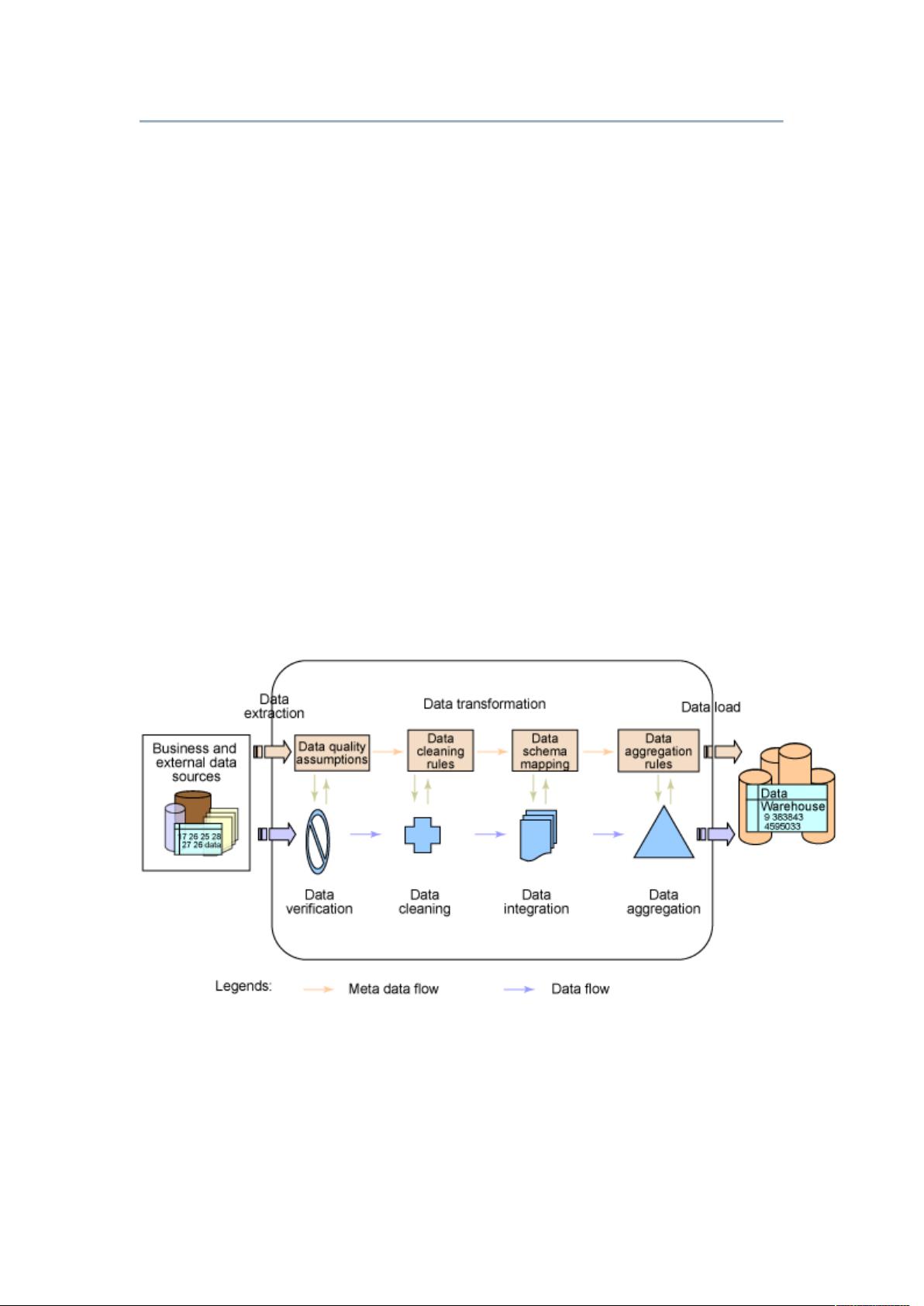
数据集成是数据仓库中的关键概念。(数据的提取、转换和加载)过程的
设计和实现是数据仓库解决方案中极其重要的一部分。过程用于从多个源
提取业务数据,清理数据,然后集成这些数据,并将它们装入数据仓库数据库
中,为数据分析做好准备。
过程设计
尽管实际的 设计和实现在很大程度上取决于为数据仓库项目选择的
工具,但是高级的系统化 设计将有助于构建高效灵活的 过程。
在深入研究数据仓库 过程的设计之前,请记住 的经验法则:“过
程不应修改数据,而应该优化数据。”如果您发现需要对业务数据进行修改,但
不确定这些修改是否会更改数据本身的含义,那么请在开始 过程之前咨询
您的客户。


剩余52页未读,继续阅读
资源评论


hillva2
- 粉丝: 0
- 资源: 6









最新资源
- 四川采矿场尾矿库安全管理规定.docx
- 四川采矿场提升运输系统管理规定.docx
- 四川采矿场消防管理规定.docx
- 基于 TensorFlow.js 的 YOLOv5 实时目标检测项目(源码+运行说明文档)
- 毕业设计-基于 TensorFlow.js 的 YOLOv5 实时目标检测项目(源码+运行说明文档)
- 基于yolov5实现目标检测+双目摄像头实现距离测量源码
- 毕业设计-基于yolov5实现目标检测+双目摄像头实现距离测量源码
- 网络工程 实验 SNMP本机测试
- 湿地检测14-YOLO(v5至v8)、COCO、CreateML、Darknet、Paligemma、VOC数据集合集.rar
- 【java毕业设计】智慧社区网服门户(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区服务网门(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区信息门户(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区门户平台(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区应用门户(源代码+论文+PPT模板).zip
- 【java毕业设计】智慧社区网端门户(源代码+论文+PPT模板).zip
- Java Swing + MyBatis框架实现的学生信息管理系统(源码+数据库)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


