





摘要
传统卷积具备平移不变性,这使得其在应对分类等任务时可以更好的学习本质特征。但是,当需要感知
位置信息时,传统卷积就有点力不从心了。为了使得卷积能够感知空间信息,作者在输入feature map
后面增加了两个coordinate通道,分别表示原始输入的x和y坐标,然后再进行传统卷积,从而使得卷积
过程可以感知feature map的空间信息,该方法称之为CoordConv。使用了CoordConv之后,能够使得
网络可以根据不同任务需求学习平移不变性或者一定程度的平移依赖性。
论文链接:https://arxiv.org/pdf/1807.03247.pdf
GitHub:https://github.com/uber-research/CoordConv
CoordConv的构造如下图所示:
与传统卷积相比,CoordConv就是在输入的feature map后面增加了两个通道,一个表示x坐标,一个表
示y坐标,后面就是与正常卷积过程一样了。
传统卷积具备三个特性:参数少、计算高效、平移不变性。而CoordConv则仅继承了其前两个特性,但
运行网络自己根据学习情况去保持或丢弃平移不变性。看似这会损害模型的归纳能力,但其实拿出一部
分网络容限能力去建模非平移不变性,实际上会提升模型的泛化能力。
事实上,如果CoordConv的坐标通道没有学习到任何信息,那么CoordConv此时就等价于传统卷积,具
备了传统卷积完全的平移不变性;而如果坐标通道学习到了 一定的信息,那么此时CoordConv就具备了
一定的平移依赖性。可见,CoordConv的平移不变性和平移依赖性是可以根据不同任务进行动态调整
的。就像残差连接那样,即可以进行恒等映射,又可以多学习一部分内容。因此,我们完全可以在需要
感知空间信息的时候使用CoordConv,一方面增加不了多少计算量,另一方面对平移不变性也没有完全
消除,而是让网络根据任务的不同学习不同程度的平移不变性和平移依赖性。
本文将CoordConv加入到YoloV8中,我们一起看看效果如何?
Yolov8官方结果
YOLOv8l summary (fused): 268 layers, 43631280 parameters, 0 gradients, 165.0
GFLOPs
Class Images Instances Box(P R mAP50
mAP50-95): 100%|██████████| 29/29 [
all 230 1412 0.922 0.957 0.986
0.737
c17 230 131 0.973 0.992 0.995
0.825
c5 230 68 0.945 1 0.995
0.836
helicopter 230 43 0.96 0.907 0.951
0.607
c130 230 85 0.984 1 0.995
0.655
f16 230 57 0.955 0.965 0.985
0.669
b2 230 2 0.704 1 0.995
0.722
other 230 86 0.903 0.942 0.963
0.534
b52 230 70 0.96 0.971 0.978
0.831
kc10 230 62 0.999 0.984 0.99
0.847
command 230 40 0.97 1 0.995
0.811
f15 230 123 0.891 1 0.992
0.701
kc135 230 91 0.971 0.989 0.986
0.712
a10 230 27 1 0.555 0.899
0.456
b1 230 20 0.972 1 0.995
0.793
aew 230 25 0.945 1 0.99
0.784
f22 230 17 0.913 1 0.995
0.725
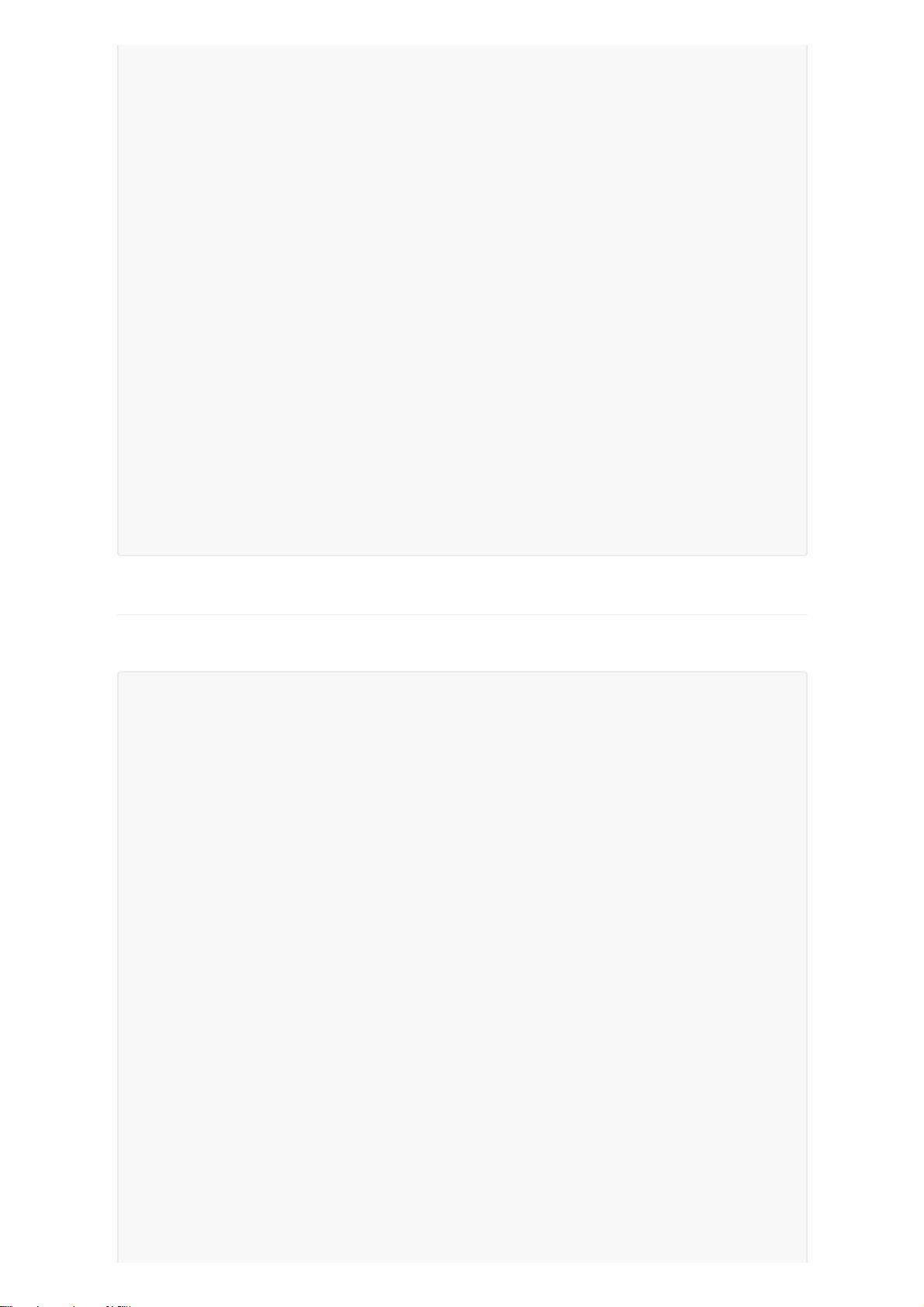
CoordConv(pytorch)代码
代码如下:
p3 230 105 0.99 1 0.995
0.801
p8 230 1 0.637 1 0.995
0.597
f35 230 32 0.939 0.938 0.978
0.574
f18 230 125 0.985 0.992 0.987
0.817
v22 230 41 0.983 1 0.995
0.69
su-27 230 31 0.925 1 0.995
0.859
il-38 230 27 0.972 1 0.995
0.811
tu-134 230 1 0.663 1 0.995
0.895
su-33 230 2 1 0.611 0.995
0.796
an-70 230 2 0.766 1 0.995
0.73
tu-22 230 98 0.984 1 0.995
0.831
Speed: 0.2ms preprocess, 3.8ms inference, 0.0ms loss, 0.8ms postprocess per
image
class AddCoords(nn.Module):
def __init__(self, with_r=False):
super().__init__()
self.with_r = with_r
def forward(self, input_tensor):
"""
Args:
input_tensor: shape(batch, channel, x_dim, y_dim)
"""
batch_size, _, x_dim, y_dim = input_tensor.size()
xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)
yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2)
xx_channel = xx_channel.float() / (x_dim - 1)
yy_channel = yy_channel.float() / (y_dim - 1)
xx_channel = xx_channel * 2 - 1
yy_channel = yy_channel * 2 - 1
xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
ret = torch.cat([
input_tensor,















