

福建农林大学金山学院实验报告
系: 计算机系 专业: 计算机科学与技术 年级: 08
级
姓名: 学号: 实验室号 607 计算机号 A3
实验时间: 2010- 6-2 指导教师签字: 成绩:
实验五 (快速、堆、基数)排序算法的设计
一、 实验目的和要求
实验目的:
1.深刻理解排序的定义和各种排序方法的特点,并能灵活运用。
2.掌握常用的排序方法,并掌握用高级语言实现排序算法的方法。
3.了解各种方法的排序过程及其依据的原则,并掌握各种排序方法的性能的分析方法。
实验要求:
要求彻底弄懂排序的物理存储结构,并通过此试验为以后的现实使用打下基础。
二、 实验内容和原理
(1)实验内容:
设计快速排序,堆排序和基数排序的算法。
(2)实验原理:
快速排序:在待排序的 n 个数据中,任取一个数据为基准,经过一次排序后以基准数据
把全部数据分为两部分,所有数值比基准数小的都排在其前面,比它大的都排在其后,然
后对这两部分分别重复这样的过程,直到全部到为为止。堆排序:对待排序的 n 个数据,
依它们的值大小按堆的定义排成一个序列,从而输出堆顶的最小值数据(按最小值跟堆排
序),然后对剩余的数据再次建堆,便得到次小的,如此反复进行输出和建堆,直到全部
排成有序列。基数排序:LSD 法:先按最低关键字位 k1 对待排序数据中的 n 个值进行排序,
按 k1 值把待排序文件中的 n 个记录分配到具有不同 k1 值的若干个堆,然后按 k1 值从小到
大的次序收集在一起,下次再按高一位关键子位 k2 的值进行分配和收集,如此不断地按更
高一位关键字位进行分配和收集,直到用 kn 分配和收集之后,整个数据按多关键字位有序。
三、 实验环境
硬件:(1)学生用微机(2)多媒体教室或远程教学(3)局域网环境
软件:(1)Windows XP 中文操作系统 (2)Turbo C 3.0
四、 算法描述及实验步骤
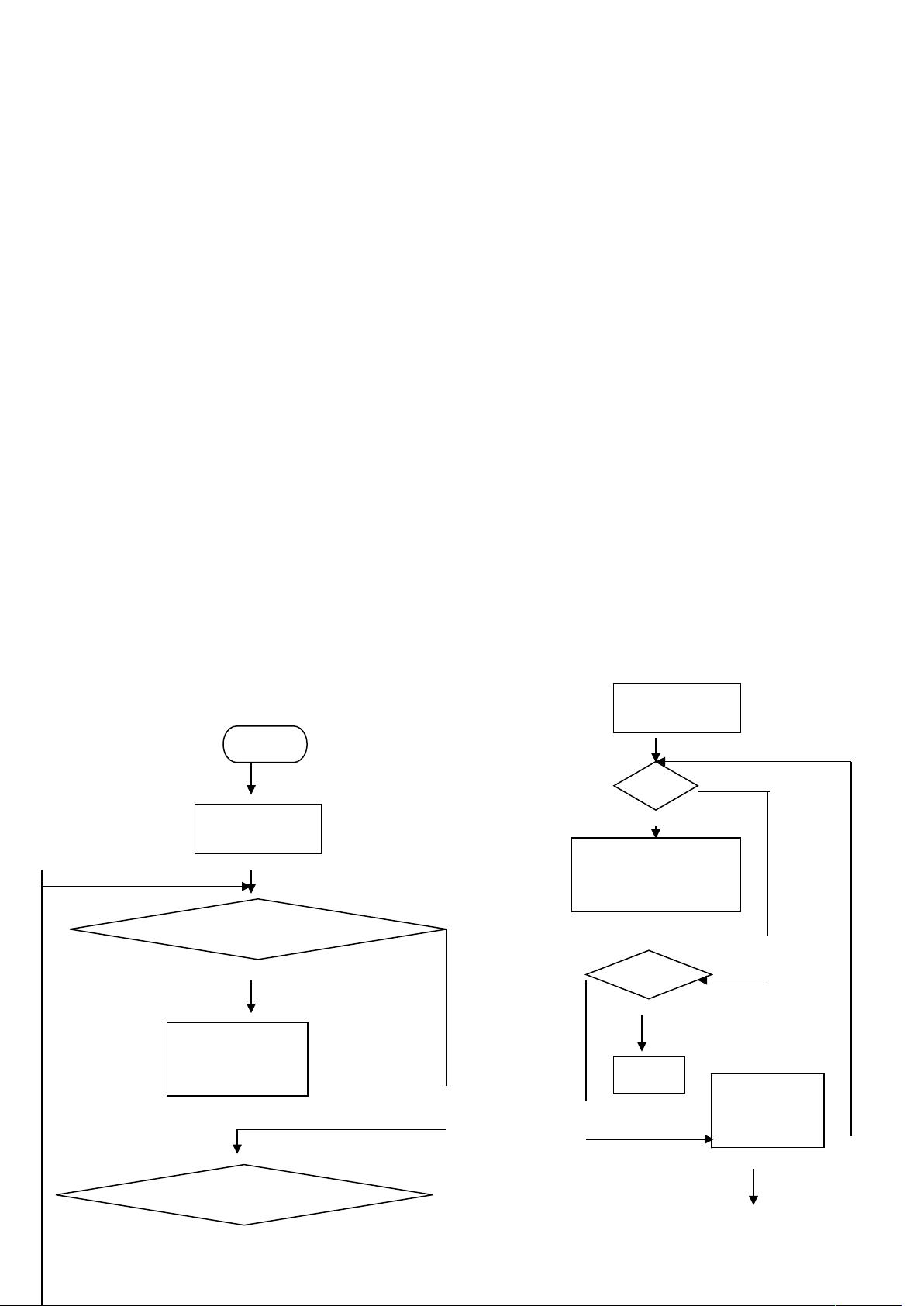
剩余10页未读,继续阅读
资源评论

 taoyi35132013-11-29里面有好几种算法,还有相应的算法流程图,比较详细
taoyi35132013-11-29里面有好几种算法,还有相应的算法流程图,比较详细
hgyyj
- 粉丝: 0
- 资源: 6









最新资源
- 3. Kafka入门-安装与基本命令
- java全大撒大撒大苏打
- pca20241222
- LabVIEW实现LoRa通信【LabVIEW物联网实战】
- CS-TY4-4WCN-转-公版-XP1-8B4WF-wifi8188
- 计算机网络期末复习资料(课后题答案+往年考试题+复习提纲+知识点总结)
- 从零学习自动驾驶Lattice规划算法(下) 轨迹采样 轨迹评估 碰撞检测 包含matlab代码实现和cpp代码实现,方便对照学习 cpp代码用vs2019编译 依赖qt5.15做可视化 更新:
- 风光储、风光储并网直流微电网simulink仿真模型 系统由光伏发电系统、风力发电系统、混合储能系统(可单独储能系统)、逆变器VSR+大电网构成 光伏系统采用扰动观察法实现mppt控
- (180014016)pycairo-1.18.2-cp35-cp35m-win32.whl.rar
- (180014046)pycairo-1.21.0-cp311-cp311-win32.whl.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


