




An Efficient Data Mining Framework on Hadoop using Java Persistence API
Yang Lai
The Key Laboratory of Intelligent Information Process-
ing, Institute of Computing Technology, Chinese
Academy of Sciences, Beijing, 100190, China.
Graduate University of Chinese Academy of Sciences,
Beijing 100039, China.
e-mail: yanglai@ics.ict.ac.cn
Shi ZhongZhi
The Key Laboratory of Intelligent Information Process-
ing, Institute of Computing Technology, Chinese
Academy of Sciences, Beijing, 100190, China.
e-mail: shizz@ics.ict.ac.cn
Abstract—Data indexing is common in data mining when working
with high-dimensional, large-scale data sets. Hadoop, a cloud
computing project using the MapReduce framework in Java, has
become of significant interest in distributed data mining. A feasi-
ble distributed data indexing algorithm is proposed for Hadoop
data mining, based on ZSCORE binning and inverted indexing and
on the Hadoop SequenceFile format. A data mining framework on
Hadoop using the Java Persistence API (JPA) and MySQL Cluster
is proposed. The framework is elaborated in the implementation of
a decision tree algorithm on Hadoop. We compare the data index-
ing algorithm with Hadoop MapFile indexing, which performs a
binary search, in a modest cloud environment. The results show
the algorithm is more efficient than naïve MapFile indexing. We
compare the JDBC and JPA implementations of the data mining
framework. The performance shows the framework is efficient for
data mining on Hadoop.
Keywords—Data Mining, Distributed applications, JPA,
ORM, Distributed file systems, Cloud computing
I. INTRODUCTION
Many approaches have been proposed for handling
high-dimensional and large-scale data, in which query proc-
essing is the bottleneck. “Algorithms for knowledge discov-
ery tasks are often based on range searches or nearest
neighbor search in multidimensional feature spaces” [1].
Business intelligence and data warehouses can hold a
Terabyte or more of data. Cloud computing has emerged for
the subsequently increasing demands of data mining. Ma-
pReduce is a programming framework and an associated
implementation designed for large data sets. The details of
partitioning, scheduling, failure handling and communica-
tion are hidden by MapReduce. Users simply define map
functions to create intermediate <key, value> tuples, and
then reduce functions to merge the tuples for special proc-
essing [2].
A concise indexing Hadoop implementation of MapRe-
duce is presented in McCreadie’s work [3]. Ralf proposes a
basic program skeleton to underlie MapReduce computa-
tions [4]. Moretti presents an abstraction for scalable data
mining, in which data and computation are distributed in a
computing cloud with minimal user efforts [5]. Gillick uses
Hadoop to implement query-based learning [6].
Most data mining algorithms are based on object
-oriented programming, which runs in memory. Han elabo-
rates many of these methods [7]. A link-based structure, like
X-tree [8], may be suitable for indexing high-dimensional
data sets.
However, the following features in the MapReduce
framework are unsuitable for data mining. First, in globality,
map tasks are irrelevant to each other, as are reducing tasks.
Data mining requires that all of the training data be con-
verted into a global model, such as a decision tree or clus-
tering tree. The tasks in the MapReduce framework only
handle its partition of the entire data set and output its results
into the Hadoop distributed file system (HDFS). Second,
random-write operations are disallowed by the HDFS, thus
disabling link-based data models in Hadoop, such as
linked-lists, trees, and graphs. Finally, the duration of both
map and reduce tasks are based on scanning processing, and
will end when the partitioning of the training dataset is fin-
ished. Data mining requires a persistent model for following
testing processing.
A database is an ideal persistent repository for objects
generated by data mining using Hadoop tasks. To mine
high-dimensional and large-scale data on Hadoop, we em-
ploy Object-Relation Mapping (ORM), which stores objects
whose size may surpass memory limits in a relational data-
base. The Java Persistence API (JPA) provides a persistence
model for ORM [9]. It can store all the objects generated
from data mining models in a relational database. A distrib-
uted database is a suitable solution to ensure robustness in
distributed handling. MySQL Cluster is designed to with-
stand any single point of failure [10], which is consistent
with Hadoop.
We performed the same work that McCreadie’s per-
formed [3] and now propose a novel indexing Hadoop im-
plementation for continuous values. Using JPA and MySQL
Cluster on Hadoop, we propose an efficient data mining
framework, which is elaborated by a decision tree imple-
mentation. The distributed computing in Hadoop and cen-
tralized data collection using JPA are combined together
organically. We also employ the naïve JDBC implementa-
tion in comparison with our JPA implementation on Ha-
doop.
The rest of the paper is organized as follows. In Section
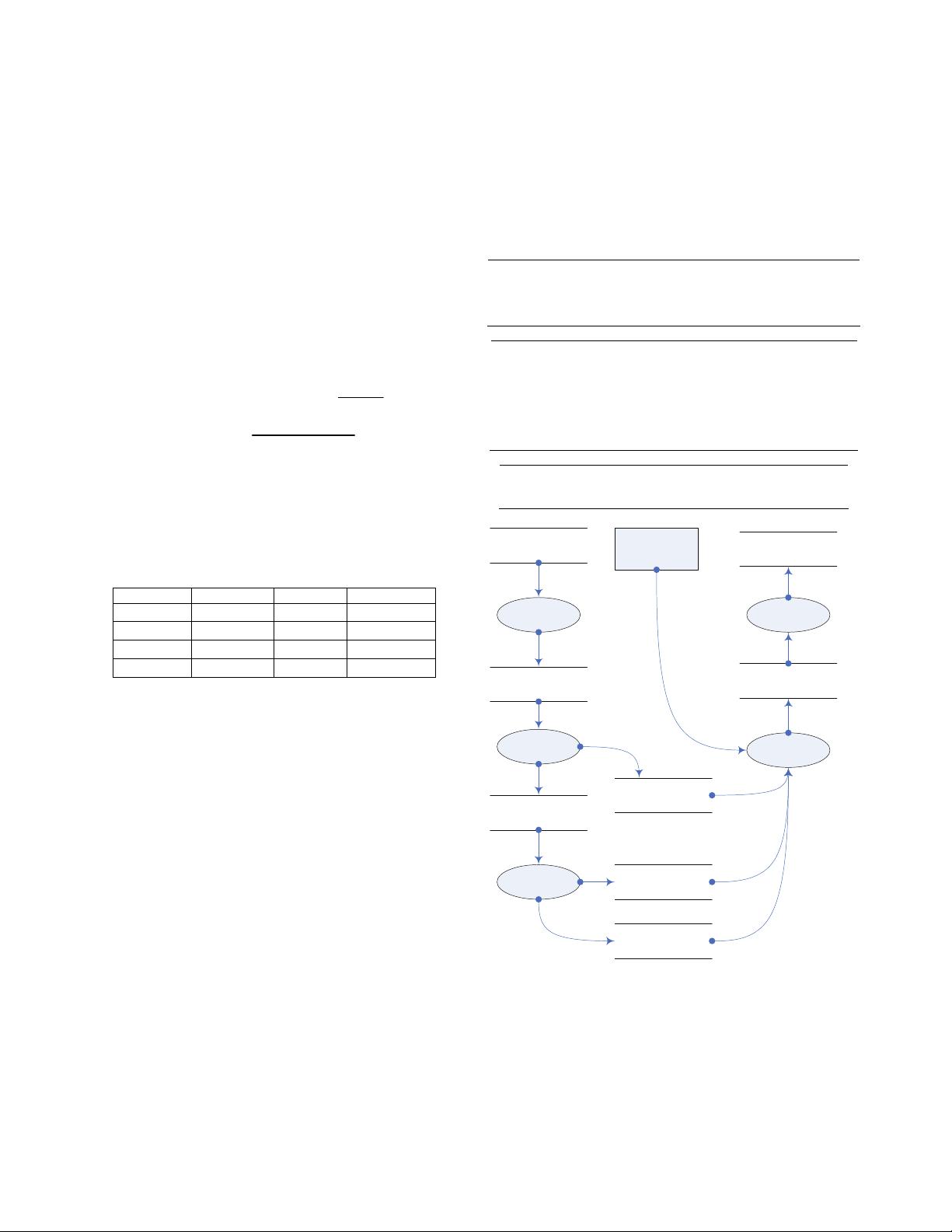
2 we explain the index structures, flowchart and algorithms,
and propose the data mining framework. Section 3 provides
descriptions of our experimental setting and results. In Sec-
tion 4, we offer conclusions and suggest possible directions
for future work.
978-0-7695-4108-2/10 $26.00 © 2010 IEEE
DOI 10.1109/CIT.2010.71
203
2010 10th IEEE International Conference on Computer and Information Technology (CIT 2010)
978-0-7695-4108-2/10 $26.00 © 2010 IEEE
DOI 10.1109/CIT.2010.71
203
2010 10th IEEE International Conference on Computer and Information Technology (CIT 2010)
978-0-7695-4108-2/10 $26.00 © 2010 IEEE
DOI 10.1109/CIT.2010.71
203














- 1
- 2
前往页