


HTK 中文手册
纠错邮箱:jianglonghu@163.com
内部资料,请务外传

HTK BOOK V3.2
第一章 HTK 基础
HTK是建立隐马尔可夫模型(HMM)的工具包,HMM能用于模拟任何时间序列,而
HTK内核对类似过程是通用的。不过HTK主要用于设计构造基于HMM的语音处理工具,
特别是识别器。因此,HTK中的一些基础组件专门用于这一任务。如上图所示,它主要有
两个处理阶段。首先,HTK训练工具使用训练语料和相应的标注文件来估计HMM模型集的
参数;第二阶段,使用HTK识别工具来识别未知语音。
这本书主体的大部分内容都和这两个处理过程的机制相关。然而,在开始更细致的介
绍之前我们需要了解HMM的基本原理,这将有利于我们对HTK工具有个整体把握,对HTK
如何组织训练和识别过程也有一定的认识。
本书第一部分提供简要介绍了HMM的基本原理,作为HTK的使用指南。这一章介绍了
HMM的基本思想和在语音中的应用。后面一章简要介绍了HTK,而且对老版本的使用者还
指出了2.0版及后续版本的主要不同之处。在本书的指南部分的最后一章,第三章,描述
了一个简单的小词汇连续语音识别系统,以此为例介绍如何使用HTK构造一个基于HMM的
语音识别系统。
这本书的第二部分对第一部分进行了详细的讲解。这部分可以结合第三部分和最后一
个部分(HTK的参考手册)来阅读。这个部分包括:每个工具的描述、配置HTK的各个参
数和产生错误时的错误信息列表。
最后需要指出的是这本书仅仅把HTK当成一个工具包,并没有提供使用HTK库作为编
程环境的相关信息。
第 页
1

HTK BOOK V3.2
1.1 HMM 的一般原理
语音识别系统通常假设语音信号是编码成一个或多个符号序列的信息实体(如图
1.1)。为了实现反向操作,即识别出给定说话人的语音的符号序列, 首先将连续语音波形
转换成一个等长的离散参数向量序列。假设这个参数向量序列是语音波形的一个精确表示,
在一个向量对应的时间段内(代表性的有10ms等等),语音信号可看成是平稳的。虽然
这一假设并不严格,但是这是合理的近似。典型的参数表示法常用的是平滑谱或线性预测
系数以及由此衍生的各种其它的表示法。
识别器的任务是在语音向量序列和隐藏的符号序列间实现一个映射。有两个问题使得
完成这一任务非常困难,第一,因为不同的隐藏符号能有相似的发音,所以符号到语音的
映射不是一一对应的,而且,发音人不同的心情和环境等因素会导致语音波形产生非常多
的变化。第二,从语音波形中不能准确地识别出各符号间的边界,因此,不能将语音波形
当做一个静态样本连接的序列。
限制识别任务为孤立词识别就可以避免第二个问题中不知道单词边界位置的问题。如
图1.2所示,这里的各段语音波形对应了固定词典中的一个简单符号(比如一个单词)。
尽管我们对这一问题的简化有点理想化,然而它却有广泛的实际应用。此外,在处理更为
复杂的连续语音之前介绍上述方法,为掌握基于HMM识别模型的基本思想打下了很好的基
础。因此,我们首先将介绍使用HMMs的孤立词识别模型。
1.2 孤立词识别模型
令每个发音单词用语音向量序列或观察向量 O 表示,定义为:
(1.1)
其中 表示在 时刻观察到的语音向量。就可以认为孤立词识别问题是在计算:
(1.2)
其中 表示第 个词典词。这个概率不是直接计算的,而是由贝叶斯公式给出:
(1.3)
因此,给定先验概率 ,最可能的发音单词就仅仅取决于概率 。给定观察序
第 页
2
HTK BOOK V3.2
列 的维数,从发音单词的样本直接计算联合条件概率 是很难实现的。
然而,如果一个单词的参数模型假设是马尔可夫模型,当估计条件观察值密度 的
问题被估计马尔可夫参数的简单问题代替,由观察向量计算 就可以实现
了。
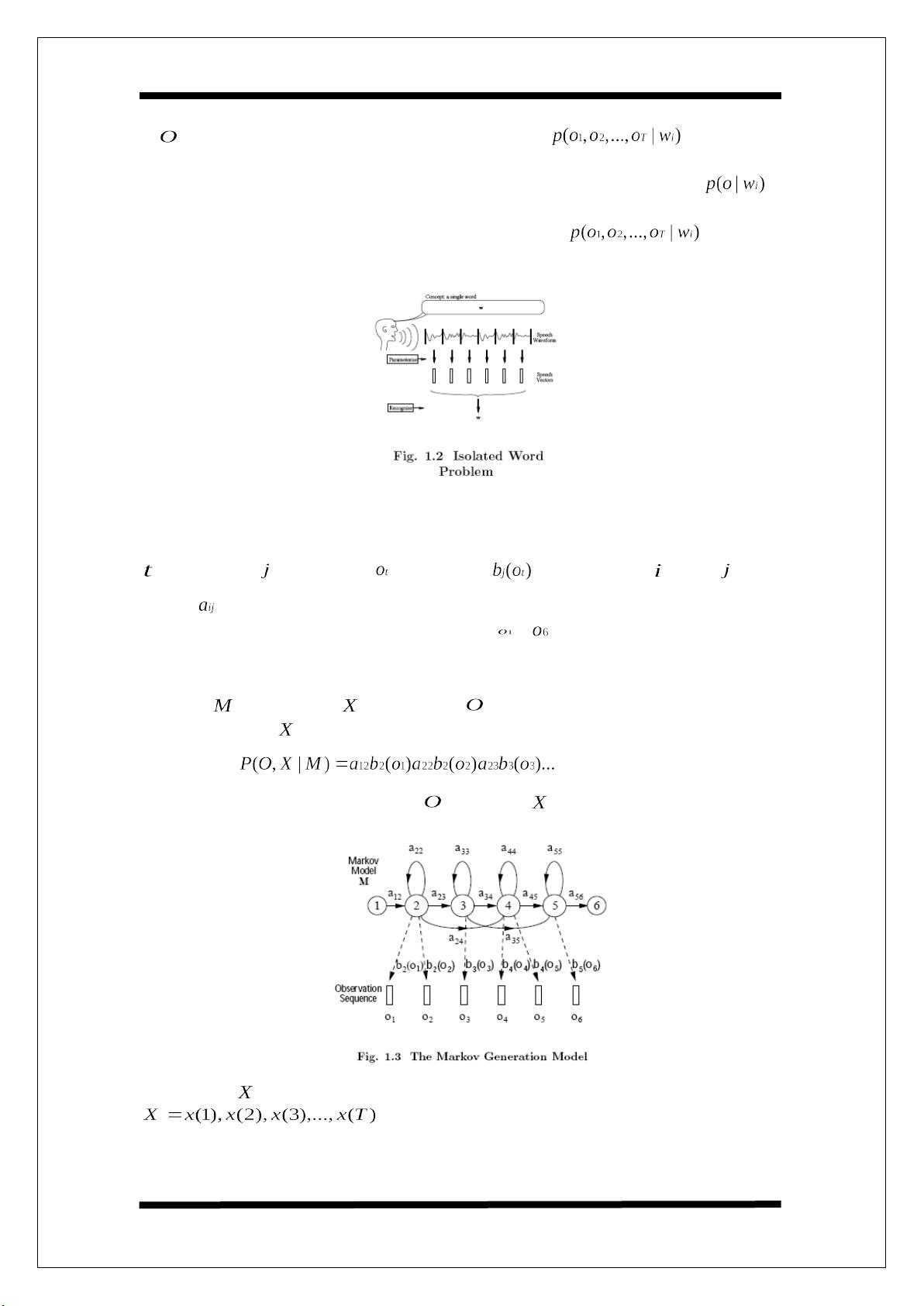
在基于HMM的语音识别中,假设观察到的语音向量序列对应由马尔可夫模型产生的
单词,如图1.3所示。马尔可夫模型是一个有限状态机,它每隔一定时间改变一次状态,在
时刻进入状态 输出语音向量 的概率密度为 ,此外,从状态 到状态 的转移
概 率 为 。 图 1.3 所 示 的 是 这 一 过 程 的 一 个 例 子 , 其 中 六 个 状 态 模 型 按 状 态 序 列
X=1,2,2,3,4,4,5,6 依次转移,产生了从 到 的输出序列。需要注意的是,在
HTK中一个HMM的入口状态和出口状态是non-emitting的,在后文中我们将对整个模型的
构建作更为详细地说明。
模型 通过状态序列 产生观察序列 的联合概率由转移概率和输出概率决定。
对图1.3的状态序列 有:
(1.4)
然而,实际情况下仅仅只知道观察序列 ,状态序列 是被隐藏的,这就是为什么称该
模型为隐马尔可夫模型了。
由 于 是 未 知 的 , 我 们 就 要 把 所 有 可 能 的 状 态 序 列
考虑进去,则:
第 页
3














