

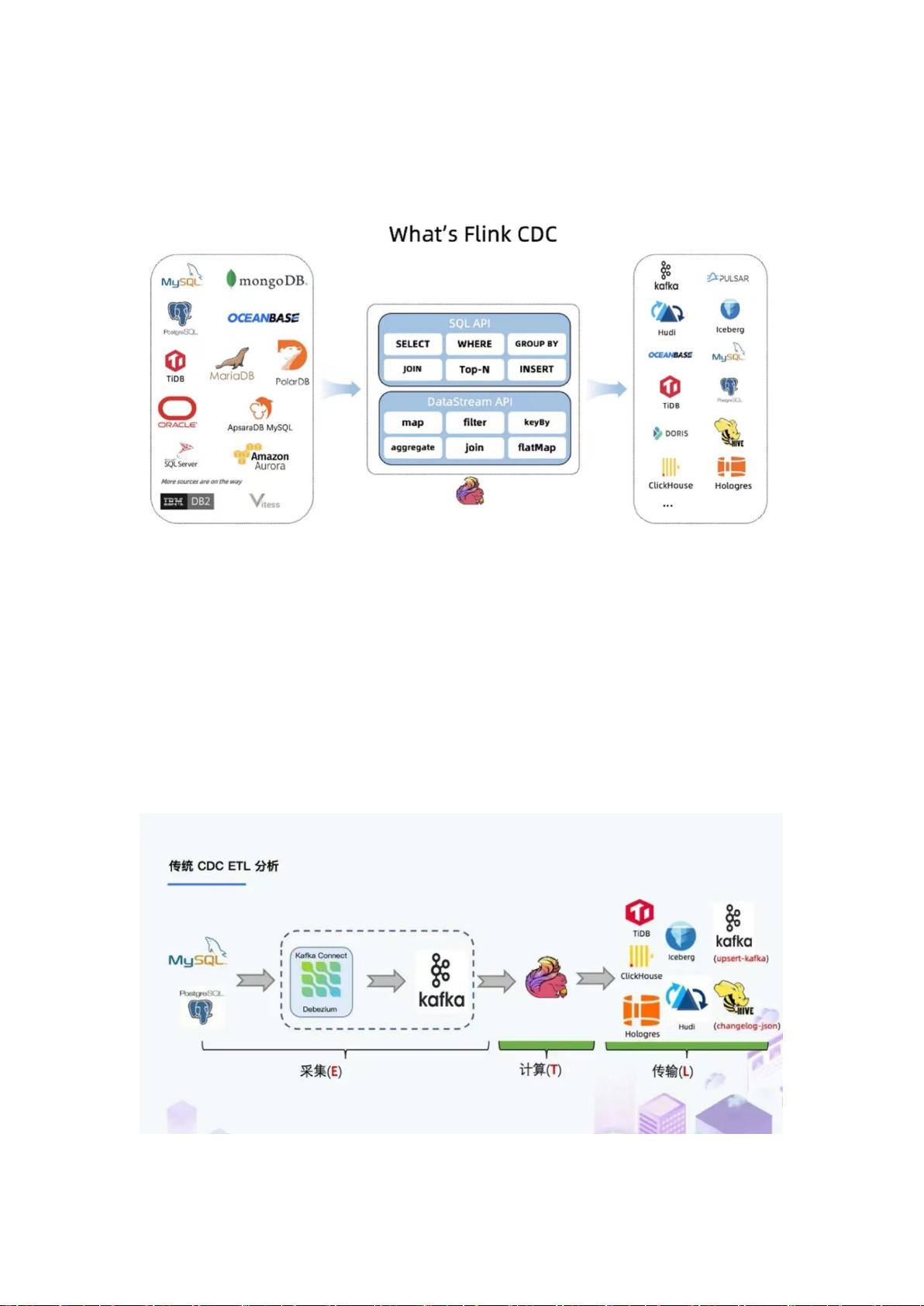
1、 cdc 是 什 么 ? 都 有 哪 些 选 型 ?
CDC 是(Change Data Capture 变更数据获取)的简称,监测并捕获数据库的数据变更。主要有基于查询
的 CDC 技术,如 dataX、kettle 等,基于日志的 CDC 技术,如 Debezium、Canal、Flink-cdc 等这两大类
。
2、 为 什 么 要 用 ? 用 在 什 么 场 景 ?
随 着 当 下 场 景 对 实 时 性 要 求 越 来 越 高 ,基 于 日 志 的 cdc 技 术 能 够 实 时 消 费 数 据 库 的 日 志 ,流 式
处 理 的 模 式 可 以 保 障 数 据 的 一 致 性 ,提供实时的数据,可 以 满 足 当 下 很 多 对 实 时 性 有 要 求 的 业
务 需 求 。 而 kettle、 dataX 这 种 基 于 查 询 的 cdc 技 术 , 则 更 多 用 在 数 据 采 集 、 抽 取 、 转 换 作 业
以 及 同 步 历 史 数 据 等 场 景 。
3、 选 择 哪 种 cdc 技 术 方 案 , 为 什 么 ?
:综 合 上 图 可 以 看 出 , flink-cdc 在 增 量 同 步 、 断 点 续 传 、 全 量 同 步 都 非 常 不 错 , 而 其 他 开 源 方
案 无 法 支 持 全 增 量 一 体 化 同 步 。 同 时 flink-cdc 是 分 布 式 架 构 , 可 以 满 足 海 量 数 据 的 业 务 场 景 。
而 canal 和 Debezium 是 单 体 架 构 , 在 大 数 据 场 景 下 容 易 面 临 性 能 瓶 颈 的 问 题 。
剩余12页未读,继续阅读













- 1
- 2
前往页