C 文件复制算法
文件复制算法
1. 任务
在 E 盘建立一个临时的目录,将 D 盘所有文件复制到这个临时文件夹里
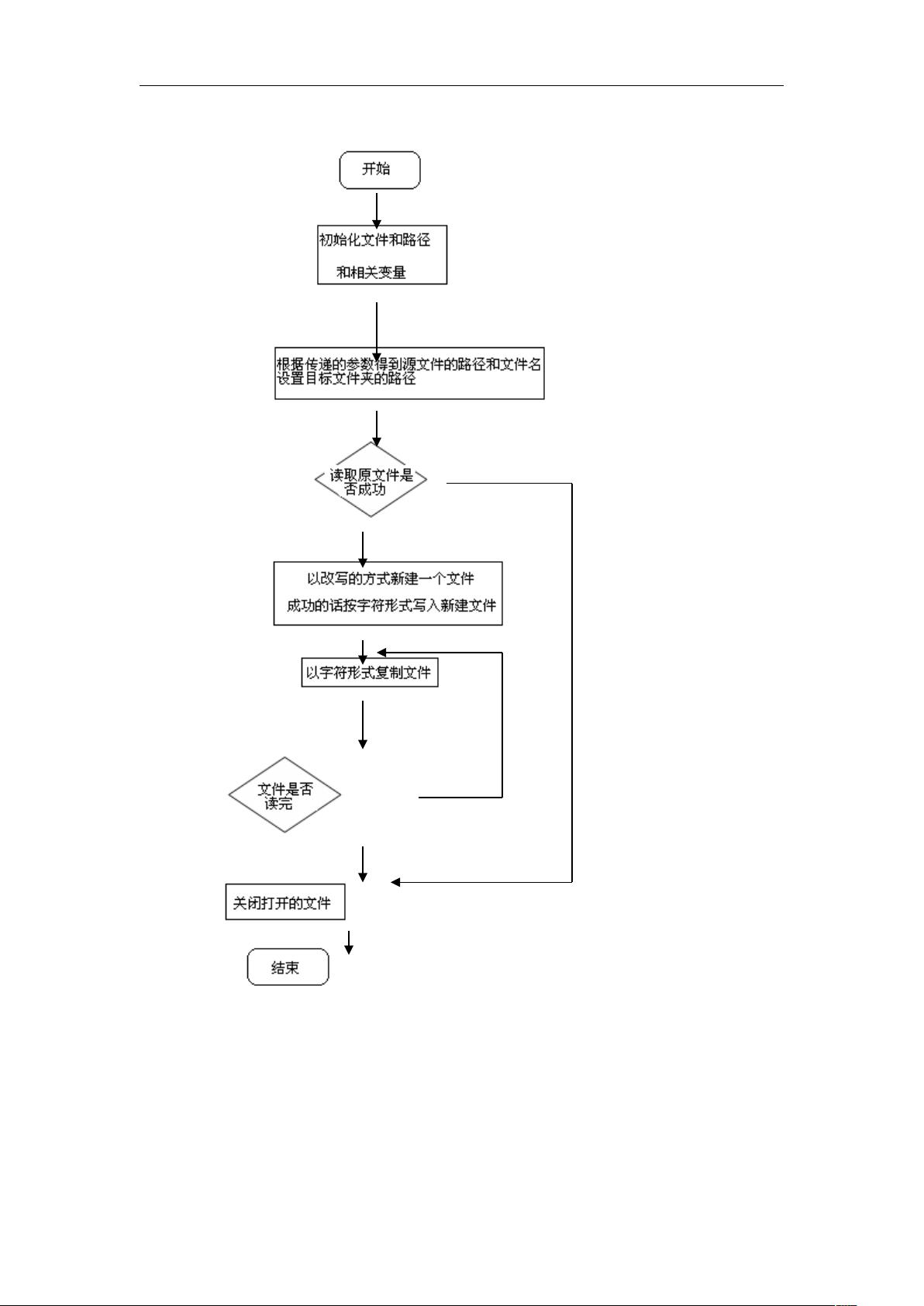
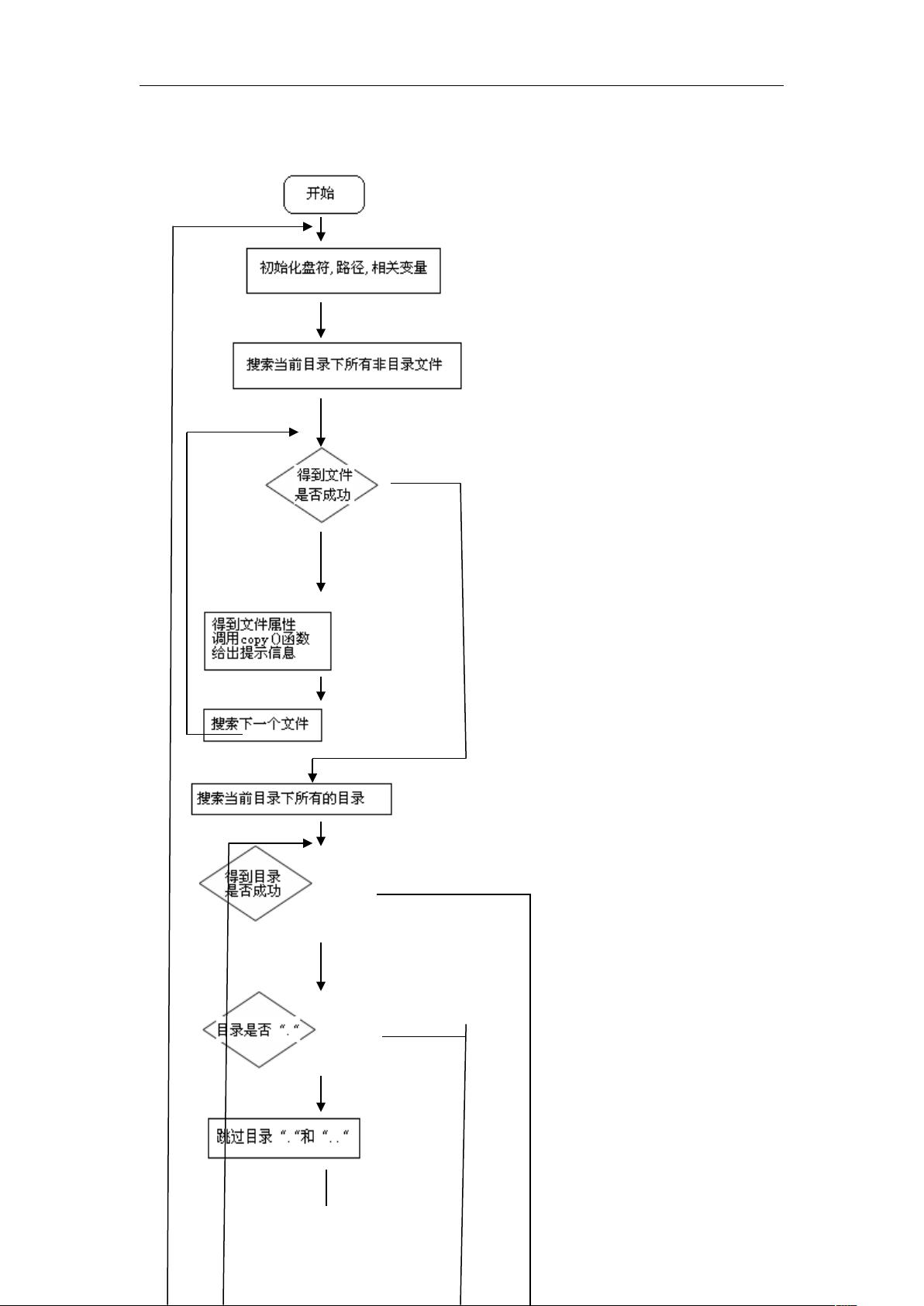
2. 实现原理
文件的复制,主要考虑到对目录的搜索,首先要找到 D 盘的所有文件,用到上一个算法的搜索子函
数,然后每搜索到一个文件,就在指定的临时文件夹下,创建一个新的这个文件的副本。
3. 涉及的相关函数
文件操作函数
fopen , fclose
文件搜索所涉及的目录操作函数
findfirst , findnext 还有 getcwd,setdisk 等
结构体 struct ffblk
字符操作函数 strcmp strcat
还有对文件属性的设置函数
chmode , _chmode
有关的操作请参考相关资料
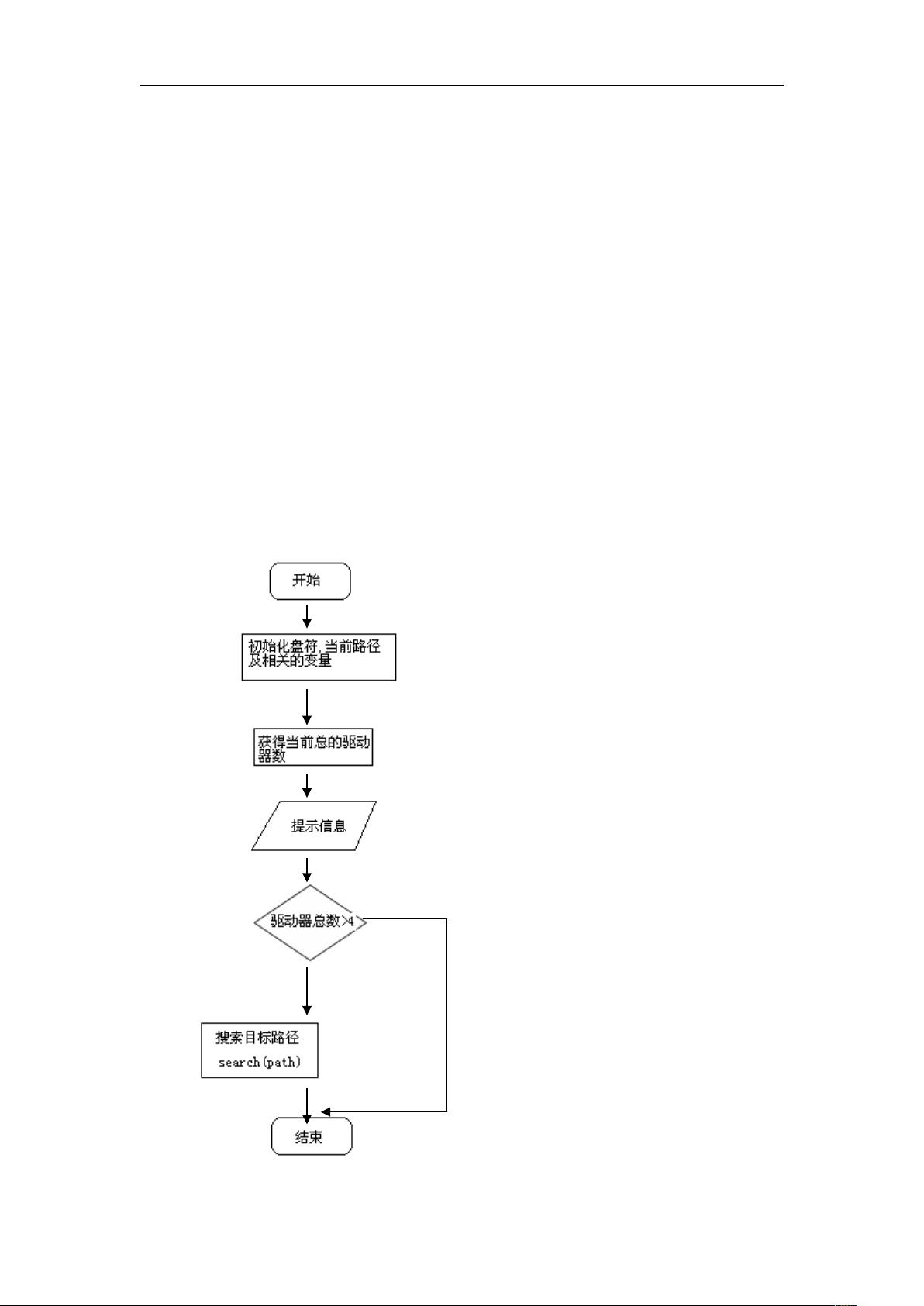
4. 程序的主流程图
Main()函数
true false
1