中文分词系统

ICTCLAS
ICTCLAS
ICTCLAS
ICTCLAS
分词系统研究(一)
收藏
ICTClAS 分词系统是由中科院计算所的张华平 、 刘群所开发的一套获得广泛好评的分词系统
,
难能可贵的是该版的 Free 版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是 , 该源代码没有配套的文档 , 阅读起来可能有一定的障碍 , 尤其是对 C/C++
不熟的人来说 . 本人就一直用 Java/VB 作为主要的开发语言 ,C/C++ 上大学时倒是学过 , 不过工作之
后一直没有再使用过 , 语法什么的忘的几
乎一干二净了 . 但语言这东西 , 基本的东西
都相通的 , 况且 Java 也是在 C/C++ 的基
础上形成的 , 有一定的相似处 . 阅读一遍源
代码 , 主要的语法都应该不成问题了 .
虽然在 ICTCLAS 的系统中没有完整
的文档说明 , 但是我们可以通过查阅张华
平和刘群发表的一些相关论文资料 , 还是
可以窥探出主要的思路 .
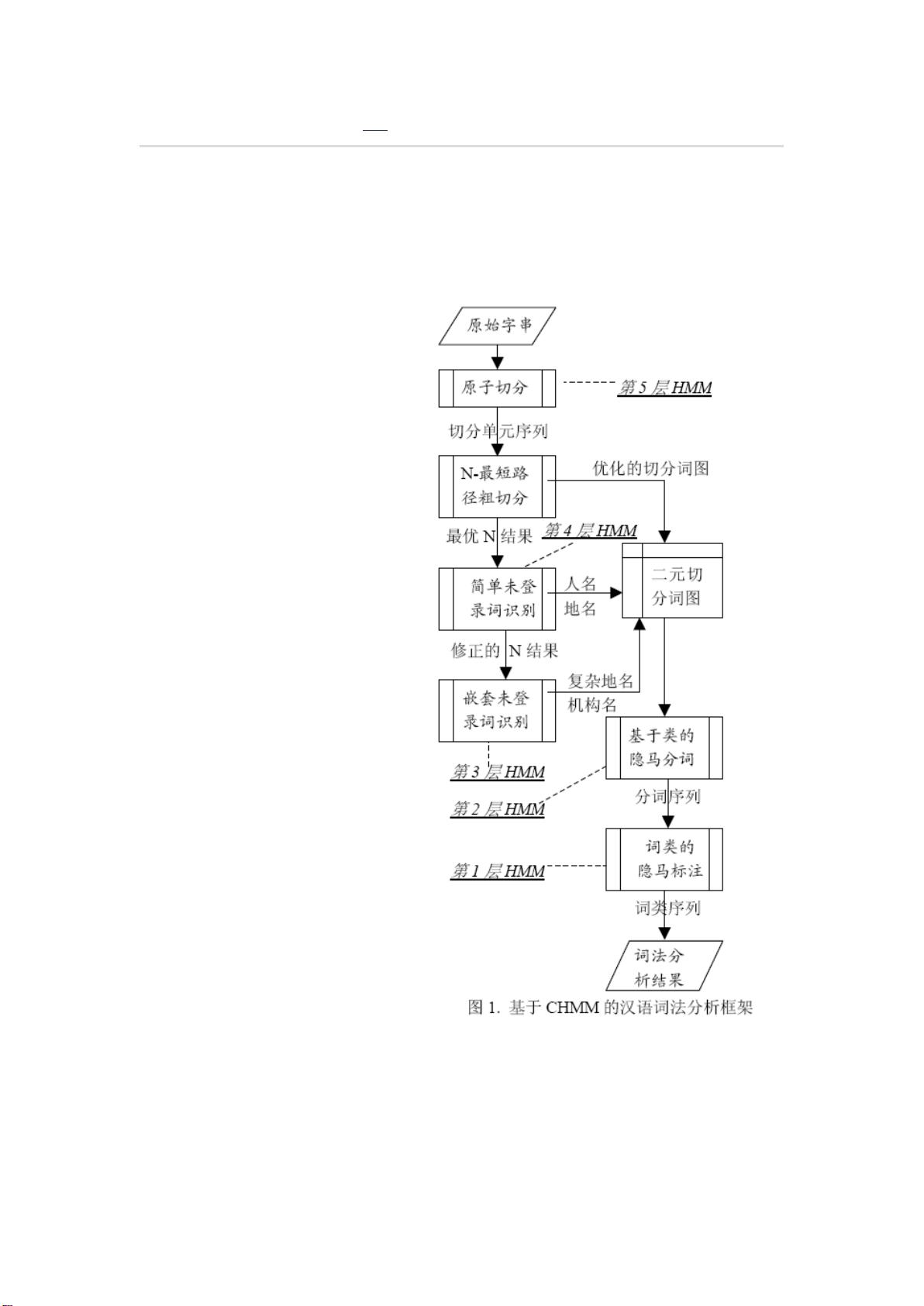
该分词系统的主要是思想是先通 过
CHMM( 层叠形马尔可夫模型 ) 进行分词 ,
通过分层 , 既增加了分词的准确性 , 又保证
了分词的效率 . 共分五层 , 如下图一所示 :
基本思路 : 先进行原子切分 , 然后在此基础
上进 行 N- 最短路径粗切分 , 找出 前 N 个最
符合的切分结果 , 生成二元分词表 , 然后生
成分词结果 , 接着进行词性标注并完成主
要分词步骤 .
下面是对源代码的主要内容的研究:
1 . 首先, ICTCLAS 分词程序首先调 用
CICTCLAS_WinDlg::OnBtnRun() 开
始程序的执行 . 并且可以从看出它的处理
方法是把源字符串分段处理 。 并且在分词
前,完成词典的加载过程,即生 成
m_ICTCLAS 对象时调用构造函数完成
词典库的加载。关于词典结构的分析,请参加分词系统研究(二)。
void CICTCLAS_WinDlg::OnBtnRun()
{
......




剩余50页未读,继续阅读
资源评论

 枯凡2014-05-03资料很深奥,要好好研究。
枯凡2014-05-03资料很深奥,要好好研究。

fang852049105
- 粉丝: 0
- 资源: 8









最新资源
- HBR740语音识别协处理芯片开发工具包(硬件参考设计原理图+PCB+51单片机软件驱动源码DEMO例程+文档资料).zip
- 人寿保险抢单协议v0.1.exe
- 数据库管理工具:dbeaver-ce-23.0.1-macos-aarch64.dmg
- M25P20, M25P40, M25P80, M25P16, M25P32, M25P64存储 SPI FLASH C语言驱动
- Matlab基于PCA算法的简单图像人脸识别.zip
- 免费的画图工具drawio,可以代替visio,版本24.5.3,适用于windows
- 瑞昱RTL8723DS-WiFi-linux- android 驱动 内含详细移植说明,支持android4.4
- AMSR/ADEOS-II L1A Raw Observation Counts, Version 3用户手册
- zaopingshujufenxi.zip
- 六级作文模板万能句型pdf.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


