

KMP 字符串模式匹配详解
来自 CSDN A_B_C_ABC 网友
KMP 字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高
效算法。简单匹配算法的时间复杂度为 O(m*n);KMP 匹配算法。可以证明它的
时间复杂度为 O(m+n).。
一. 简单匹配算法
先来看一个简单匹配算法的函数:
int Index_BF ( char S [ ], char T [ ], int pos )
{
/*若串 S 中从第 pos(S 的下标0≤pos<StrLength(S))个字符
起存在和串 T 相同的子串,则称匹配成功,返回第一个
这样的子串在串 S 中的下标,否则返回 -1 */
int i = pos, j = 0;
while ( S[i+j] != '�'&& T[j] != '�')
if ( S[i+j] == T[j] )
j ++; //继续比较后一字符
else
{
i ++; j = 0;//重新开始新的一轮匹配
}
if ( T[j] == '�')
return i; //匹配成功 返回下标
else
return -1;//串 S 中(第 pos 个字符起)不存在和串 T 相同的子串
}// Index_BF
此算法的思想是直截了当的:将主串 S 中某个位置 i 起始的子串和模式串 T
相比较。即从 j=0起比较 S[i+j]与 T[j],若相等,则在主串 S 中存在以 i 为起
始位置匹配成功的可能性,继续往后比较( j 逐步增1 ),直至与 T 串中最后一个
字符相等为止,否则改从 S 串的下一个字符起重新开始进行下一轮的"匹配",即
将串 T 向后滑动一位,即 i 增1,而 j 退回至0,重新开始新一轮的匹配。
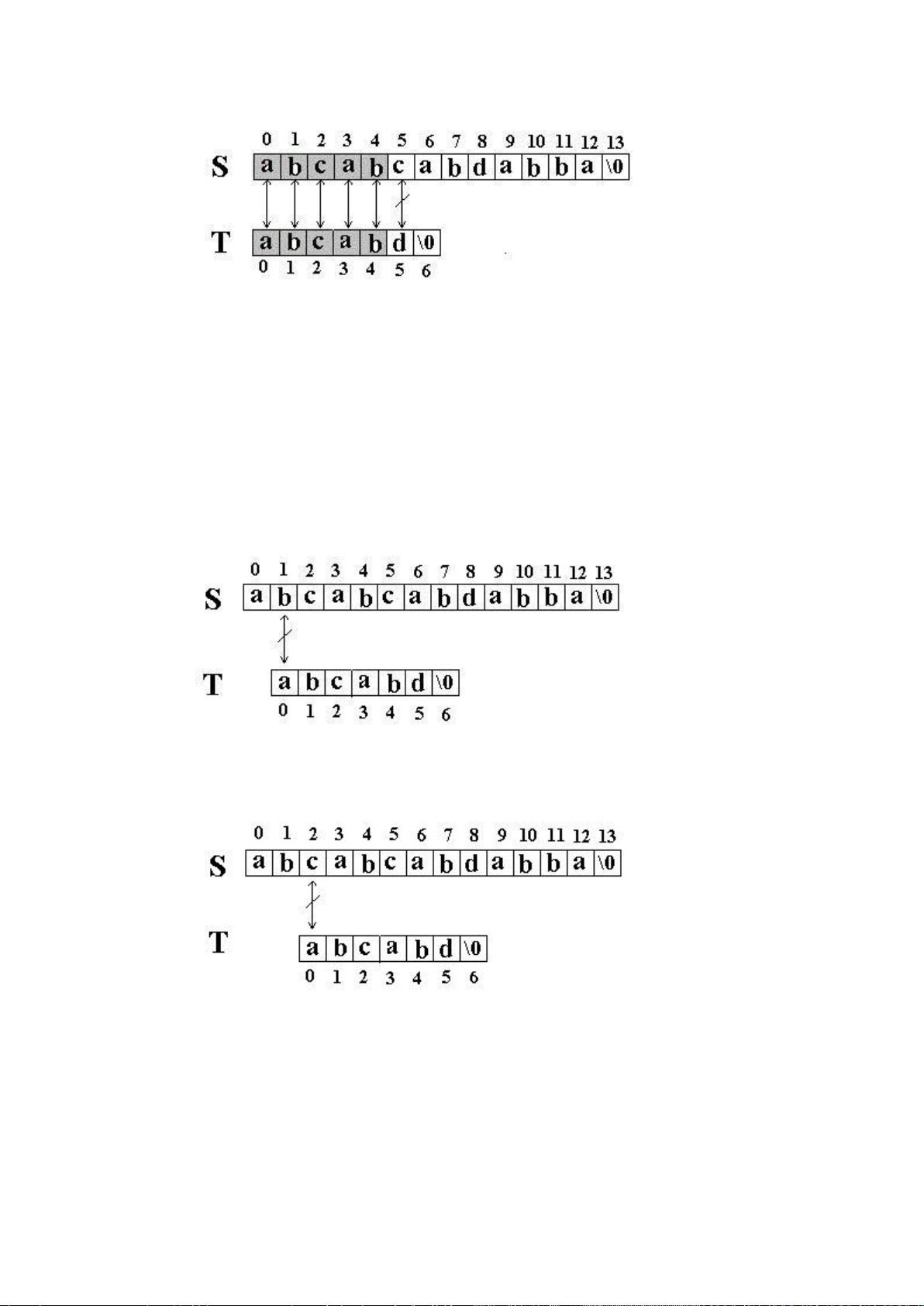
例如:在串 S=”abcabcabdabba”中查找 T=” abcabd”(我们
可以假设从下标0开始):先是比较 S[0]和 T[0]是否相等,然后比较 S[1]和 T[1]
是否相等…我们发现一直比较到 S[5]和 T[5]才不等。如图:
剩余11页未读,继续阅读
资源评论

 aierkei2014-10-21好用,有收获
aierkei2014-10-21好用,有收获
f379972052
- 粉丝: 0
- 资源: 1









最新资源
- 基于matlab的视频镜头检测、视频关键帧提取源代码+实验报告PPT
- 中国法研杯法律智能源码+设计文档.zip
- 智能循迹避障小车-基于树莓派图像识别(含源码+项目说明+硬件设计).zip
- 中文短文本实体链指技术-CCKS2019比赛技术创新奖解决方案(基于Python,含源码+项目说明).zip
- 智慧医疗在线挂号小程序(前后端分离,支持疫苗预约等模块,含源码+项目说明).zip
- 智能门禁系统-基于STM32的多模态身份验证(含人脸识别+蓝牙APP+RFID+密码锁,最新开发).zip
- 智能教室管理系统-基于龙芯2K1000处理器(含源码+项目说明+硬件设计).zip
- 智能售货系统-基于Qt的饮料售卖机(含源码+项目说明+硬件设计).zip
- 知识图谱医疗诊断问答系统python源码+项目说明(2024毕设).zip
- 指标体系管理系统-基于Java实现(含源码+项目说明+课设报告).zip
- Java 代码辅助开发工具
- 智慧路灯管理系统-基于MQTT协议+物联网云平台(含源码+项目说明+部署指南).zip
- 掌静脉识别系统-手势识别与特征提取(含源码+项目说明+GUI界面设计).zip
- 智慧养老系统-基于情感分析(实训项目,含源码+项目说明+设计文档).zip
- 证券交易系统开发(含源码+项目说明+设计文档).zip
- 征信系统-基于Hyperledger Fabric技术打造可靠信用评价体系(含源码及设计文档).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


