
yolov5yolov3训练⾃⼰的数据集(超详细,细的有点烦)
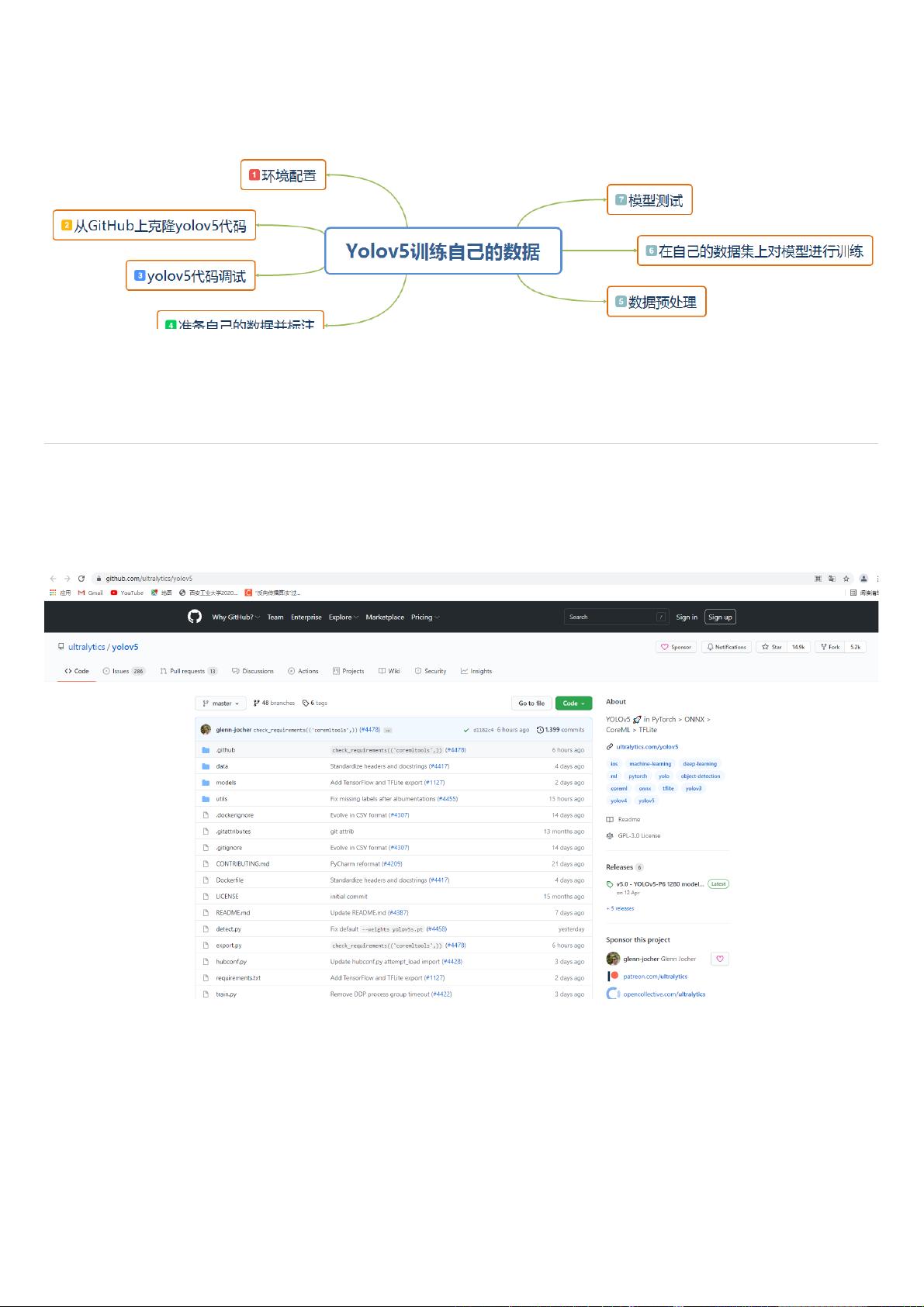
YOLO系列是⾮常优秀的物体检测框架,⽬前总共有V1-V5五个版本。本博客的⽬的在于教⼤家如何使⽤YOLOv5训练⾃⼰的数据,重点
在于应⽤。有关原理我会在后⾯的博客中详细介绍。使⽤YOLOv5训练⾃⼰的数据往往要经过以下⼏个步骤:
⼀、环境配置
在环境配置⽅⾯,我安装的是tensorflow-gpu2.3.0、cuda10.1、cudnn7.6.4、torch1.9.0、anaconda我选择的是python3.8版本。
有关详细的安装过程⼤家可以参考我的另⼀篇博客《Tensorflow-gpu2.1.0+cuda+cudnn+torch安装教程(超详细)》博客地址:
⼆、克隆源代码
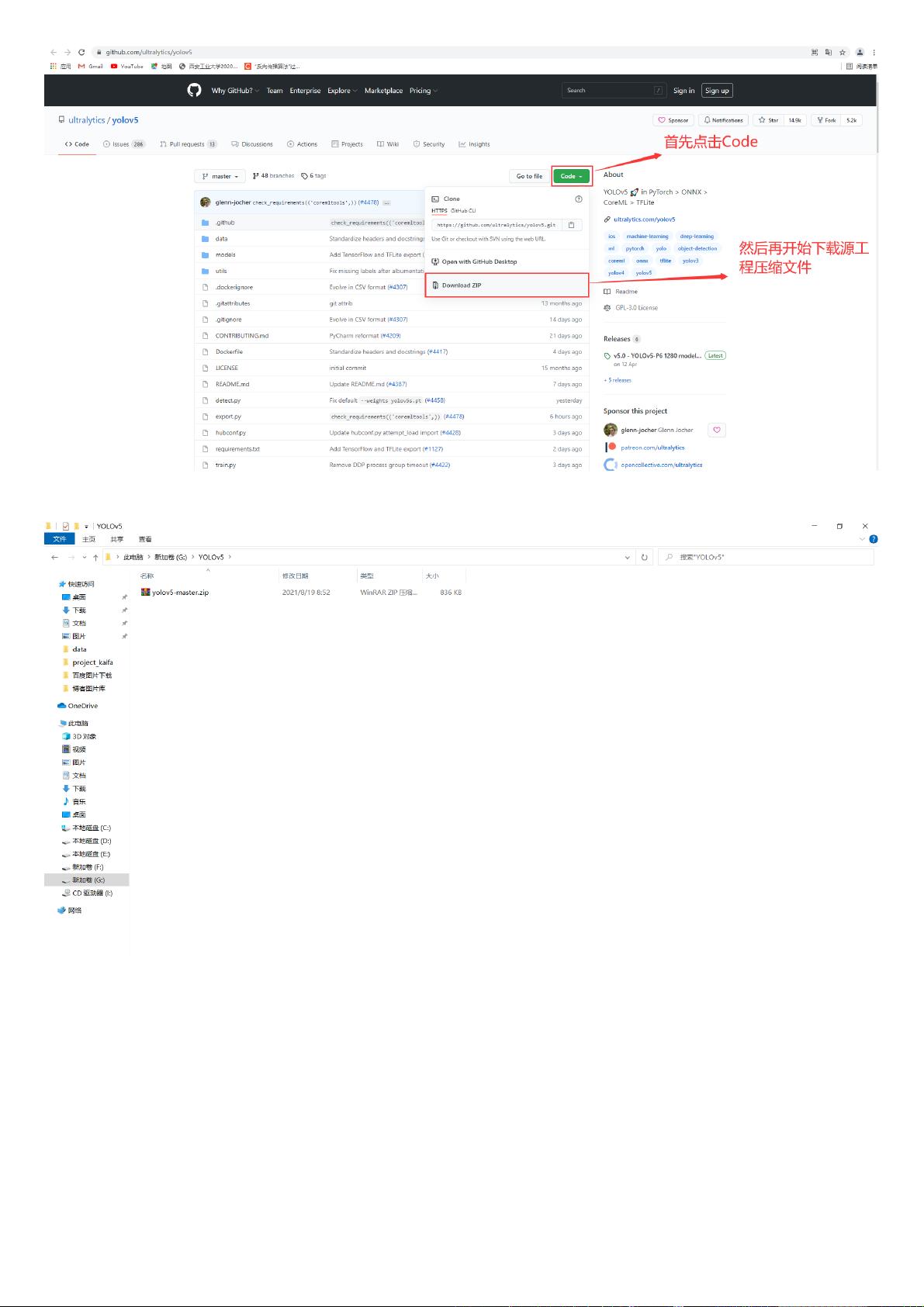
⽬前GitHub上有⾮常多的YOLOv5代码,其中YOLOv5论⽂的源代码地址为:
,建议⼤家尽量去下载“官⽅代码”。具体如下图所⽰:
然后点击Code会弹出下载选项,具体如下图所⽰:

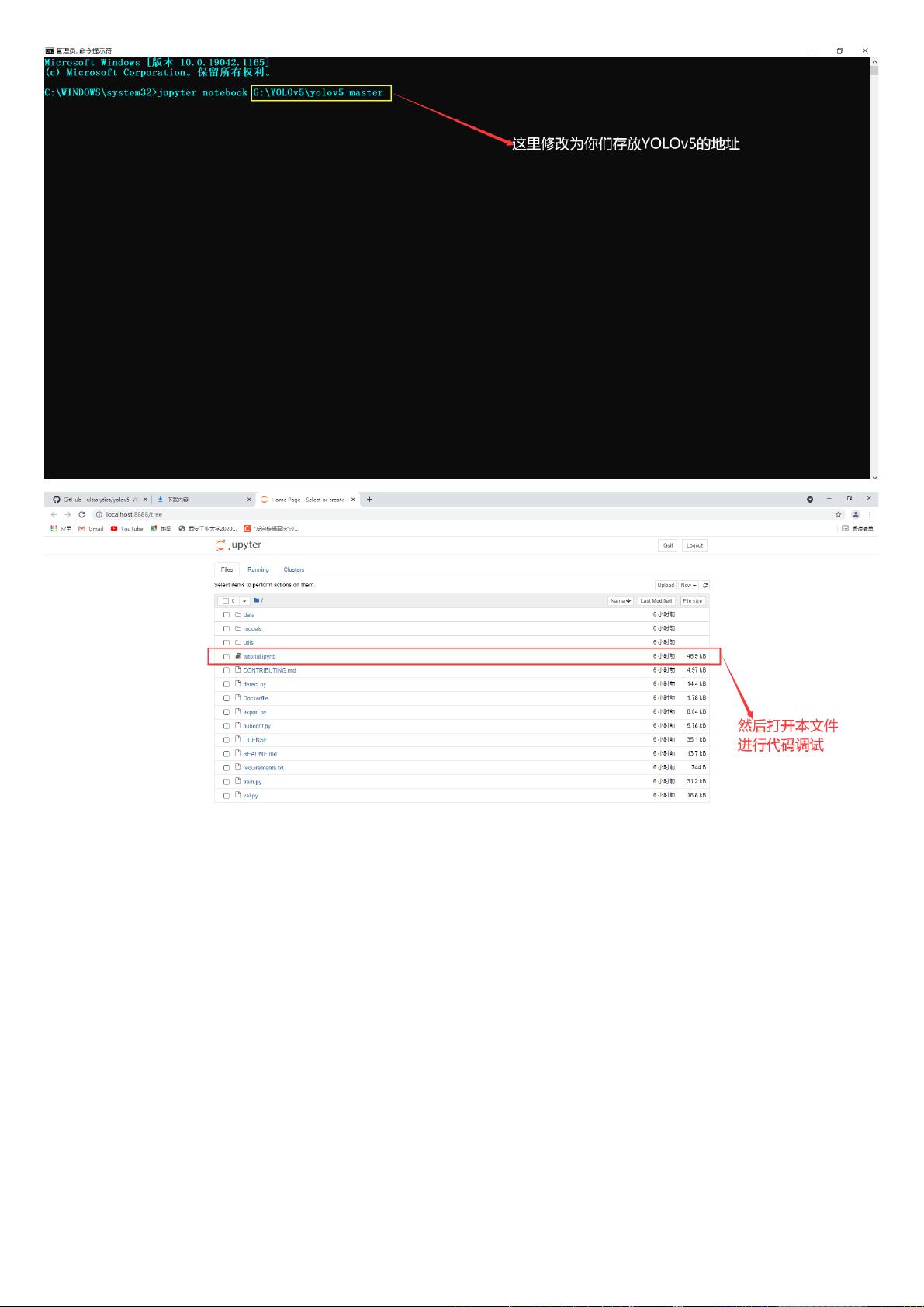
剩余24页未读,继续阅读
资源评论



emma20080101
- 粉丝: 1081
- 资源: 5280









最新资源
- COMSOL模拟热流固耦合作用下的二氧化碳驱替甲烷研究:探索煤层变形、孔渗变化及气体产量动态分析(含讲解视频),COMSOL模拟热流固耦合作用下的二氧化碳驱替甲烷过程:研究煤层变形、孔渗变化及气体产量
- 电子胸花.zip
- 基于Vue框架的地铁问答系统设计源码
- 多变流水灯控制电路.zip
- XMSinaSwift-Swift资源
- MATLAB课程作业-Matlab资源
- 基于Vue框架的青光眼诊断系统前端设计源码
- SpireCV-机器人开发资源
- Carsim Simulink联合仿真下的递推最小二乘法估计轮胎侧偏刚度模型详解:文档详实,代码规范实践,基于Carsim和Simulink联合仿真的递推最小二乘法估计轮胎侧偏刚度模型详解,Cars
- MXImagePicker-Kotlin资源
- nexfly-AI人工智能资源
- 宿迁市乡镇边界,shp格式
- minio-rsc-Rust资源
- 基于Maxwell模型的三相调速永磁同步电动机设计研究与实践-冲片设计与仿真案例,三相调速永磁同步电动机的Maxwell模型:高效能效、多极可调的电机设计方案与实践,三相调速永磁同步电动机maxwe
- 基于Flask框架的JavaScript驱动的web项目设计源码
- 湖州市乡镇边界,shp格式
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


