

Rethinking Graph Transformers with Spectral
Attention
Devin Kreuzer
∗
McGill University, Mila
Montreal, Canada
devin.kreuzer@mail.mcgill.ca
Dominique Beaini
*
Valence Discovery
Montreal, Canada
dominique@valencediscovery.com
William L. Hamilton
McGill University, Mila
Montreal, Canada
wlh@cs.mcgill.ca
Vincent Létourneau
University of Ottawa
Ottawa, Canada
vletour2@uottawa.ca
Prudencio Tossou
Valence Discovery
Montreal, Canada
prudencio@valencediscovery.com
Abstract
In recent years, the Transformer architecture has proven to be very successful in
sequence processing, but its application to other data structures, such as graphs,
has remained limited due to the difficulty of properly defining positions. Here, we
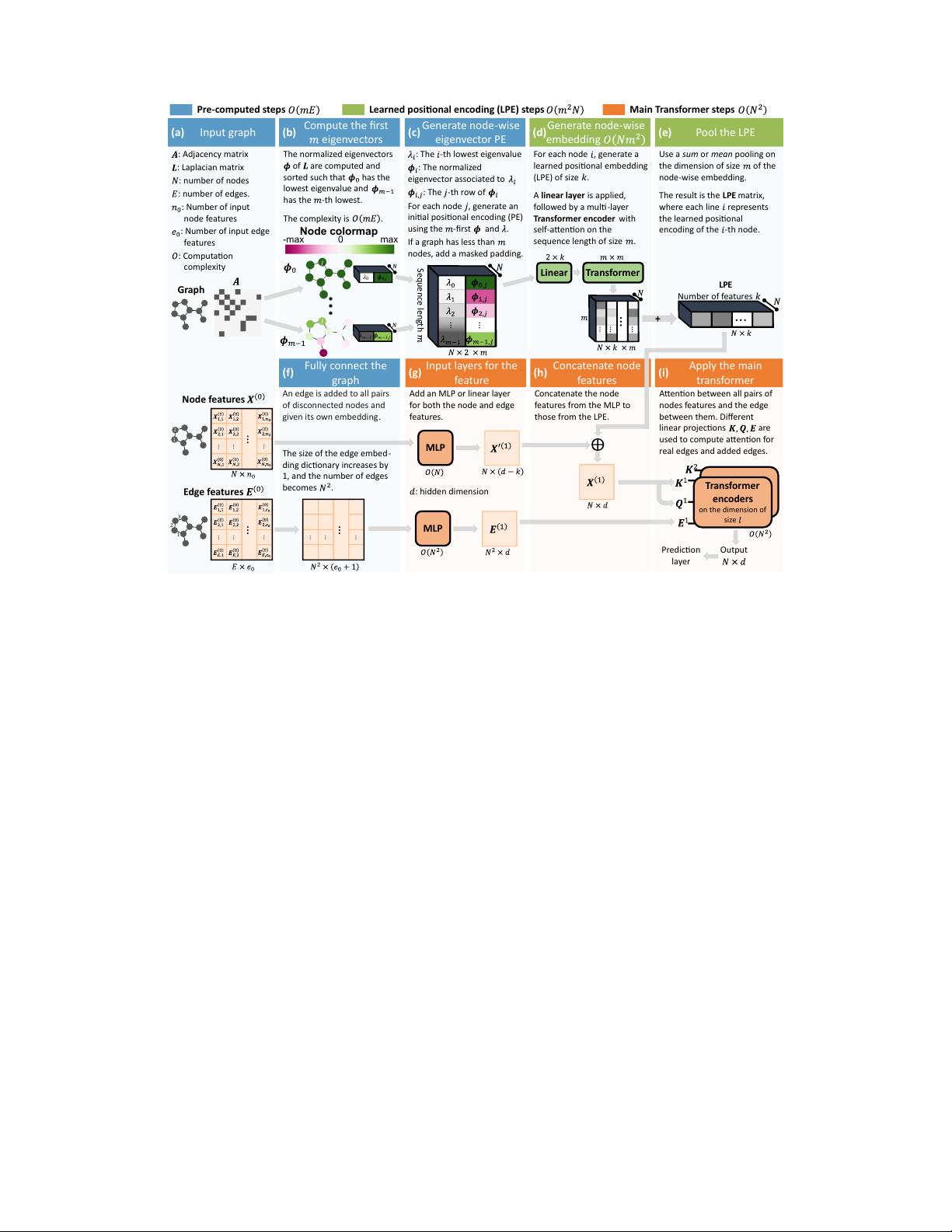
present the Spectral Attention Network (SAN), which uses a learned positional
encoding (LPE) that can take advantage of the full Laplacian spectrum to learn the
position of each node in a given graph. This LPE is then added to the node features
of the graph and passed to a fully-connected Transformer. By leveraging the full
spectrum of the Laplacian, our model is theoretically powerful in distinguishing
graphs, and can better detect similar sub-structures from their resonance. Further,
by fully connecting the graph, the Transformer does not suffer from over-squashing,
an information bottleneck of most GNNs, and enables better modeling of physical
phenomenons such as heat transfer and electric interaction. When tested empirically
on a set of 4 standard datasets, our model performs on par or better than state-of-the-
art GNNs, and outperforms any attention-based model by a wide margin, becoming
the first fully-connected architecture to perform well on graph benchmarks.
1 Introduction
The prevailing strategy for graph neural networks (GNNs) has been to directly encode graph structure
structure through a sparse message-passing process [
17
,
19
]. In this approach, vector messages
are iteratively passed between nodes that are connected in the graph. Multiple instantiations of
this message-passing paradigm have been proposed, differing in the architectural details of the
message-passing apparatus (see [19] for a review).
However, there is a growing recognition that the message-passing paradigm has inherent limitations.
The expressive power of message passing appears inexorably bounded by the Weisfeiler-Lehman iso-
morphism hierarchy [
29
,
30
,
39
]. Message-passing GNNs are known to suffer from pathologies, such
∗
Equal contribution.
35th Conference on Neural Information Processing Systems (NeurIPS 2021).
arXiv:2106.03893v3 [cs.LG] 27 Oct 2021

剩余17页未读,继续阅读
资源评论














