提升C语义用于数据流优化_Lifting C Semantics for Dataflow Optimization.pdf
版权申诉
150 浏览量
2022-01-04
23:29:43
上传
评论
收藏 1.32MB PDF 举报


Lifting C Semantics for Dataow Optimization
Alexandru Calotoiu
acalotoiu@inf.ethz.ch
ETH Zurich, Switzerland
Tal Ben-Nun
talbn@inf.ethz.ch
ETH Zurich, Switzerland
Grzegorz Kwasniewski
gkwasnie@inf.ethz.ch
ETH Zurich, Switzerland
Johannes de Fine Licht
definelj@inf.ethz.ch
ETH Zurich, Switzerland
Timo Schneider
timo.schneider@inf.ethz.ch
ETH Zurich, Switzerland
Philipp Schaad
philipp.schaad@inf.ethz.ch
ETH Zurich, Switzerland
Torsten Hoeer
torsten.hoefler@inf.ethz.ch
ETH Zurich, Switzerland
Abstract
C is the lingua franca of programming and almost any device
can be programmed using C. However, programming mod-
ern heterogeneous architectures such as multi-core CPUs
and GPUs requires explicitly expressing parallelism as well
as device-specic properties such as memory hierarchies.
The resulting code is often hard to understand, debug, and
modify for dierent architectures. We propose to lift C pro-
grams to a parametric dataow representation that lends
itself to static data-centric analysis and enables automatic
high-performance code generation. We separate writing code
from optimizing for dierent hardware: simple, portable C
source code is used to generate ecient specialized versions
with a click of a button. Our approach can identify parallelism
when no other compiler can, and outperforms a bespoke par-
allelized version of a scientic proxy application by up to
21%.
Keywords:
parallelism, dataow analysis, automatic paral-
lelization
1 Introduction
Many performance critical applications are written in C, as
its machine model is usually closest to hardware and allows
for bare-metal tuning to achieve highest performance. Ac-
cording to the TIOBE index [
45
] in 2020, C was the most
popular language in Internet searches. High-performance
computing centers state that 25% of their users primarily use
C [
17
]. Since Kernighan’s and Ritchie’s original inception of
the C language, systems have changed dramatically. Most
architectures need specialized instructions, compiler direc-
tives, or libraries to be used eciently. This usually leads
to C programs where more lines of code are implementing
optimizations tailored to the architecture than solving the
actual problem.
Targeted optimization is tightly coupled to hardware ar-
chitectures. A code written for GPUs using CUDA, a code
written to exploit shared memory using OpenMP, and a code
written for large supercomputers using the message passing
interface (MPI) can be nominally written in C, but will vary
widely even if they solve the same problem. The only aspect
they are likely to have in common is the sequential algo-
rithm each variant is based on. We argue that specializing
the programs to an architecture treats the symptoms, but
cannot eliminate the root cause: precisely because C was not
designed for performance portability, optimizing C programs
is both challenging and time consuming.
A powerful alternative to specialization is using tools
provided by modern compilers such as polyhedral analy-
sis [
10
,
22
] to optimize and parallelize sequential C code, with
results rivaling and even surpassing hand-tuned versions of
the code. However, these are limited to static control parts
(SCOPs) within functions [
22
]. SCOPs impose constraints
on what type of source code can be analyzed: indirect array
accesses such as
𝑥 [𝑐𝑜𝑙𝑢𝑚𝑛_𝑖𝑛𝑑𝑒𝑥 [𝑗]]
are typically not per-
mitted. The limitation is apparent in the following example
(sparse matrix vector multiplication), as no optimization is
possible due to the data-dependent indirect array accesses.
for (i = 0; i < N; i ++)
for (j = row _p tr [ i ]; j < row_ pt r [ i + 1]; j ++)
y[ i ] += A [ c ol_ id x [ j ]] * x[j ];
In search of a more general solution, we observe that data
movement is the most expensive part of most program exe-
cutions when considering both energy and time [
26
]. Data-
centric programming and leveraging dataow graphs is al-
ready widely performed in compiler analysis [
30
,
31
,
49
], and
recently emerging in graph analytics [
48
], high performance
computing [
6
,
42
], and machine learning [
3
]. Data-centric
models are both productive and portable, as parallelism is in-
herently expressed as data-independent sections, regardless
of the target hardware.
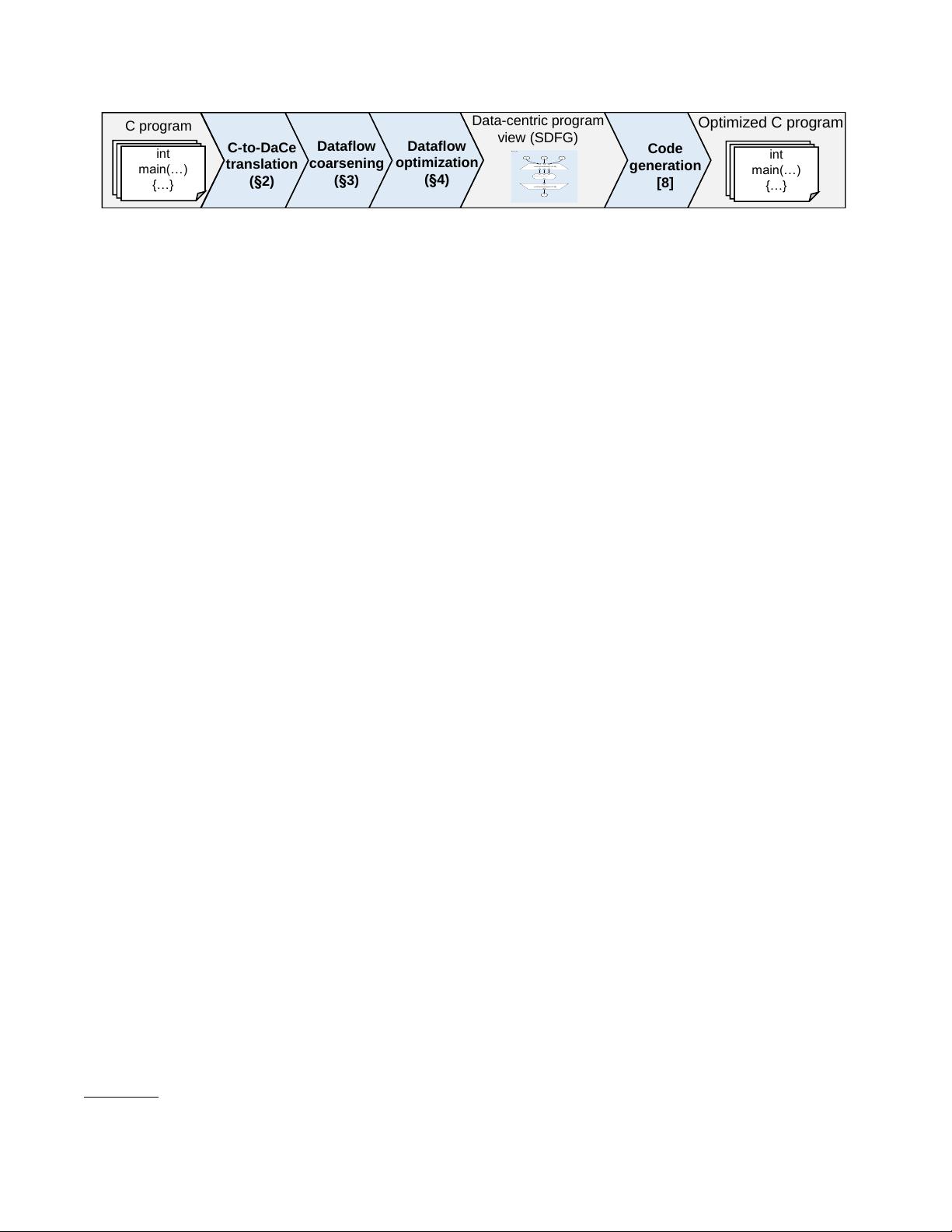
Our goal is to generate optimized, parallel code for dif-
ferent platforms by minimizing data movement. To achieve
it, we extract the data movement semantics from most C pro-
grams into a parametric dataow representation, where data
movement can be better analyzed and transformed. While
one cannot statically analyze the dataow of all C programs,
as can be shown by the Halting problem or Rice’s theorem,
we observe that high performance C codes, a subset of C
1
arXiv:2112.11879v2 [cs.PL] 30 Dec 2021

剩余11页未读,继续阅读
资源评论



易小侠
- 粉丝: 6508
- 资源: 9万+









最新资源
- 以下是一些适用于英语六级作文的万能句型模板,涵盖了引言、正文和结论部分的各类表达方式.docx
- MATLAB中的非线性规划
- 进行C语言面试资格确认是招聘过程中一个重要的步骤,目的是确保候选人具备足够的C语言编程能力和知识.docx
- Java 轻量级的集群负载均衡设计
- 纹身师个人网站模板.jpg
- 在C语言中,连接两个字符串(即将一个字符串附加到另一个字符串的末尾)通常可以使用标准库中的 `strcat` 函数.docx
- 数据库管理工具:dbeaver-ce-23.1.1-stable.x86-64.rpm
- 以下是几个具体竞赛题目的详细解答,包括建模思路、方法和步骤 .docx
- 一份关于全国大学生建模大赛的相关教程!!
- 以下是关于计算机网络和现代通信组网的详细教程、案例和相关项目的推荐.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


