You Only Cache Once: Decoder-Decoder Architectures for Language
需积分: 0 18 浏览量
2024-05-23
18:00:08
上传
评论
收藏 928KB PDF 举报


You Only Cache Once:
Decoder-Decoder Architectures for Language Models
Yutao Sun
∗ †‡
Li Dong
∗ †
Yi Zhu
†
Shaohan Huang
†
Wenhui Wang
†
Shuming Ma
†
Quanlu Zhang
†
Jianyong Wang
‡
Furu Wei
†⋄
†
Microsoft Research
‡
Tsinghua University
https://aka.ms/GeneralAI
Abstract
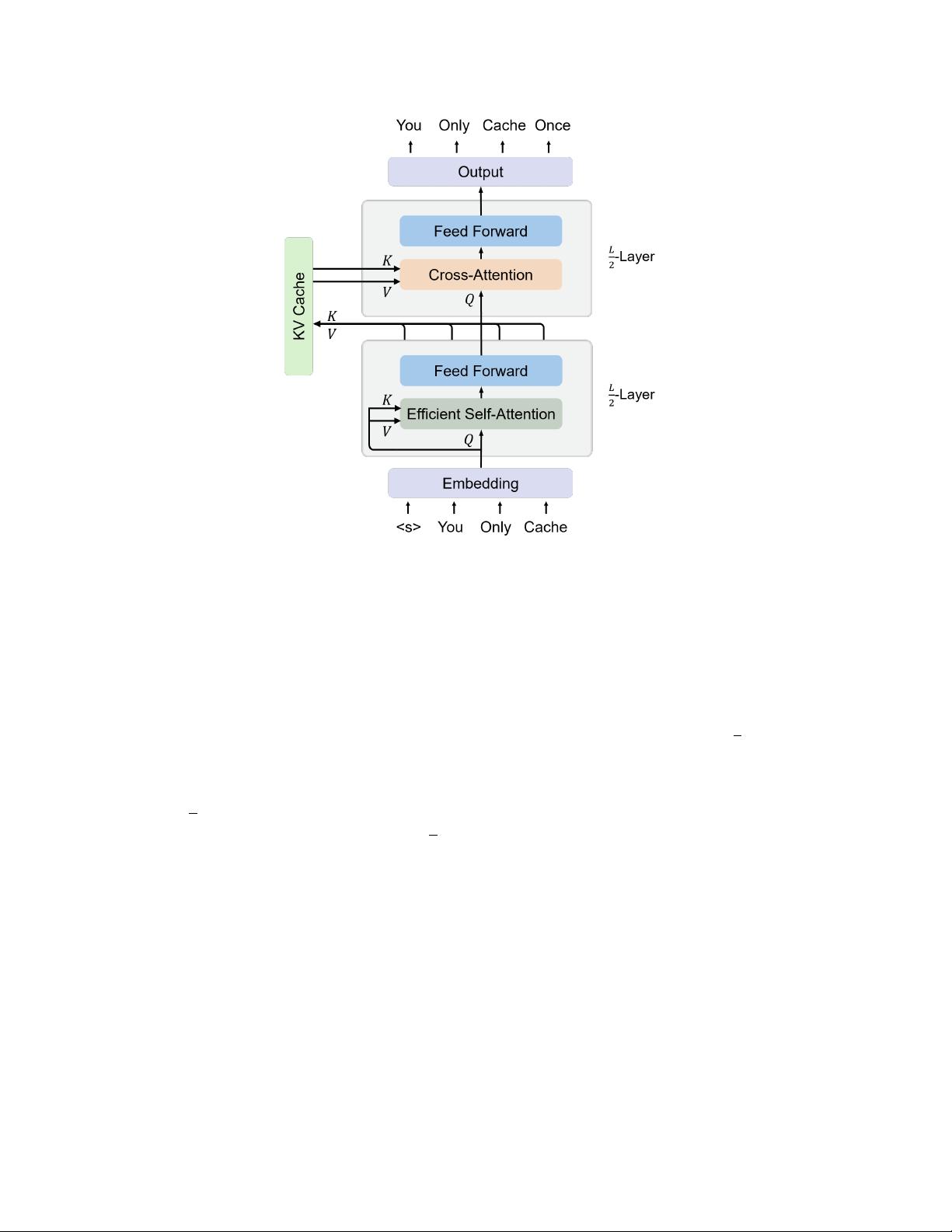
We introduce a decoder-decoder architecture, YOCO, for large language models,
which only caches key-value pairs once. It consists of two components, i.e., a cross-
decoder stacked upon a self-decoder. The self-decoder efficiently encodes global
key-value (KV) caches that are reused by the cross-decoder via cross-attention.
The overall model behaves like a decoder-only Transformer, although YOCO
only caches once. The design substantially reduces GPU memory demands, yet
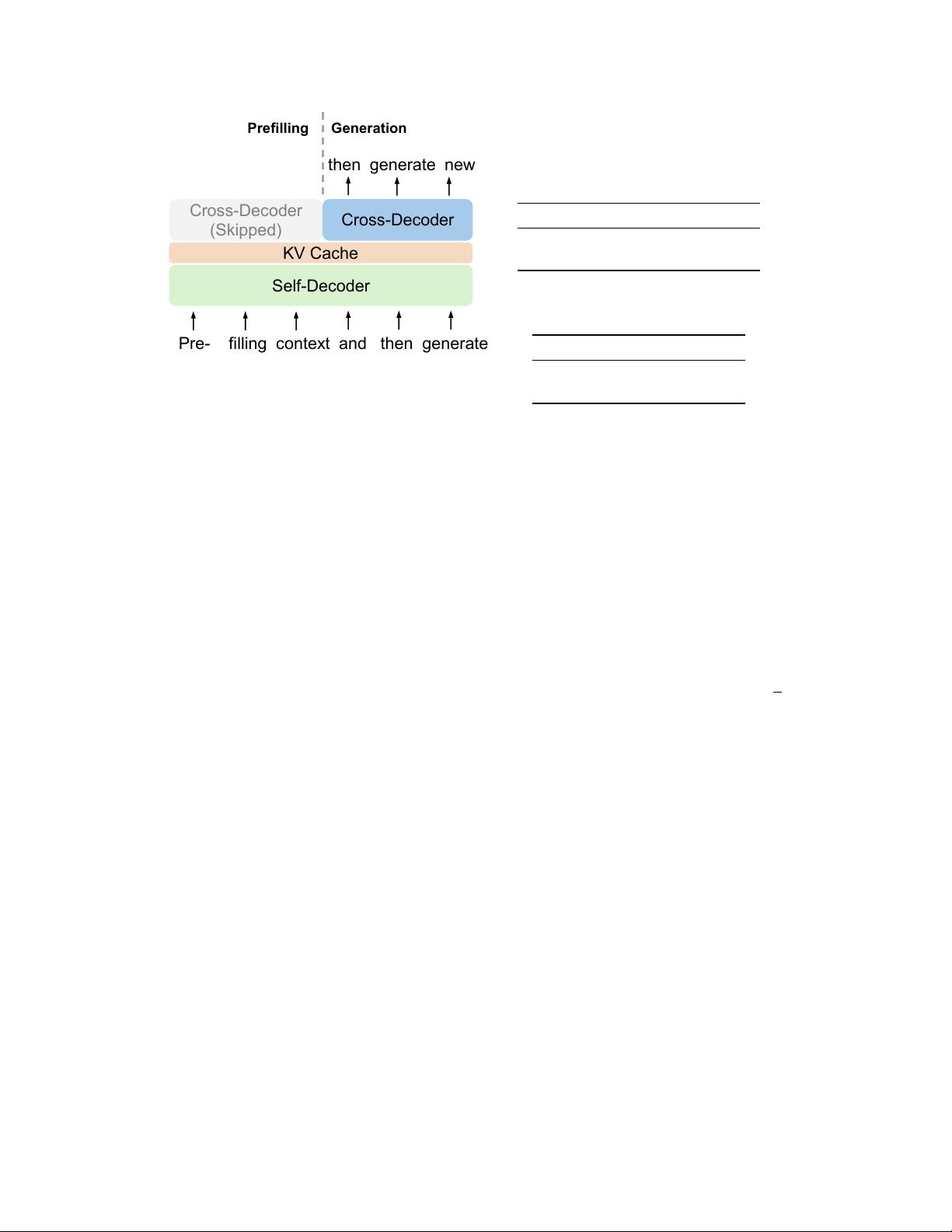
retains global attention capability. Additionally, the computation flow enables
prefilling to early exit without changing the final output, thereby significantly
speeding up the prefill stage. Experimental results demonstrate that YOCO achieves
favorable performance compared to Transformer in various settings of scaling
up model size and number of training tokens. We also extend YOCO to 1M
context length with near-perfect needle retrieval accuracy. The profiling results
show that YOCO improves inference memory, prefill latency, and throughput by
orders of magnitude across context lengths and model sizes. Code is available at
https://aka.ms/YOCO.
0
20
40
60
0
20
40
0
60
120
180
GPU Memory ↓
(GB)
Throughput ↑
(wps)
Prefilling Latency ↓
(s)
6.4X
30.3X
9.6X
Inference Cost (@512k)
Decoder-Decoder LLM
YOCOTransformer
Cross-Decoder
<s> You Only Cache
You Only Cache Once
Self-Decoder
KV Cache
Figure 1: We propose a decoder-decoder architecture, YOCO, for large language model, which only
caches key/value once. YOCO markedly reduces the KV cache memory and the prefilling time, while
being scalable in terms of training tokens, model size, and context length. The inference cost is
reported to be 512K as the context length, and Figures 7–10 present more results for different lengths.
∗
Equal contribution. ⋄ Corresponding author.
arXiv:2405.05254v2 [cs.CL] 9 May 2024

剩余19页未读,继续阅读
资源评论


Hefin_H
- 粉丝: 170
- 资源: 3









最新资源
- dirent.h,Windows下,标准库没有提供
- 年长者便捷上网中心源码
- 是一个简单的Python脚本示例,使用Pillow库来展示基本的图像处理操作,包括打开图像、显示图像、转换图像大小、旋转图像以及
- Hbulider制作的华为云物联网APP
- 车辆检测的视频,视频来自YouTube,Los Angeles Freeway I-101 HD 30fps traffic
- [初学者必看]JavaScript 简单实际案例练习,锻炼代码逻辑思维
- 高分项目,PID-电机类-PID电机调速控制源码+参考资料+PID测速
- grafana-enterprise-11.0.0.windows-amd64.msi
- 一个简单的Go程序示例,实现了上传并读取Excel文件的功能:
- ubuntu: jdk1.8安装包(免费)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


