机器学习技术在达观数据的实现
需积分: 10 71 浏览量
2015-12-22
00:56:01
上传
评论 1
收藏 8.01MB DOCX 举报


机器学习技术在达观数据的实践
大数据时代里,互联网用户每天都会直接或间接使用到大数据技术的成果,
直接面向用户的比如搜索引擎的排序结果,间接影响用户的比如网络游戏的流
失用户预测、支付平台的欺诈交易监测等等。达观数据技术团队长期以来一直
致力于钻研和积累各种大数据技术,曾获得 cikm2014 数据挖掘竞赛冠军,也
开发过智能文本内容审核系统、作弊监测系统、用户建模系统等多个基于大数
据技术的应用系统。机器学习是大数据挖掘的一大基础,本文以机器学习为切
入点,将达观在大数据技术实践时的一些经验与大家分享(达观数据联合创始
人 纪传俊)
CIKM 数据挖掘竞赛获得冠军后领奖
机器学习——海量数据挖掘解决方案
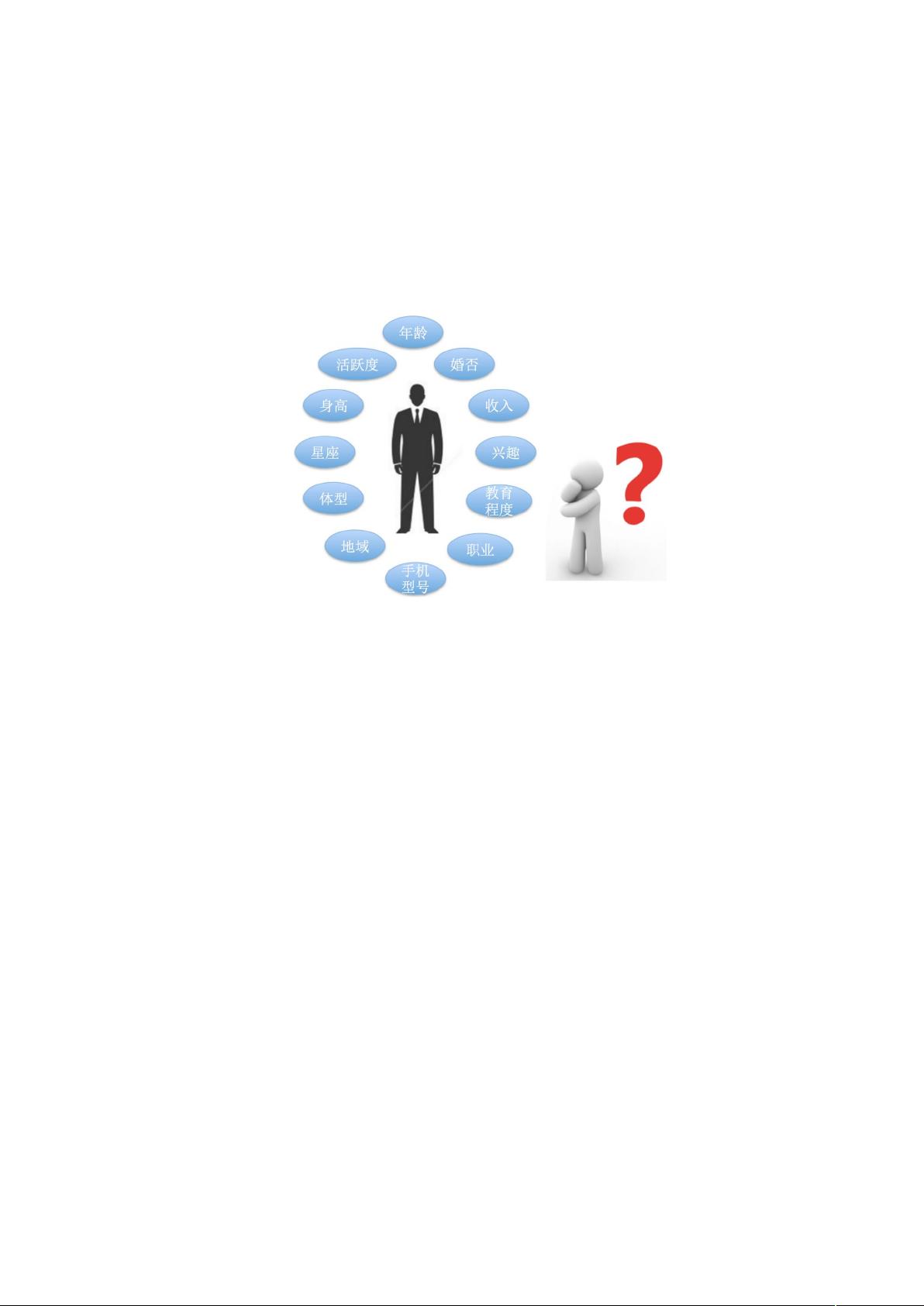
互联网的海量数据不可能靠人工一个个处理,只能依靠计算机批量处理。
最初的做法是人为设定好一些规则,由机器来执行。比如明确指定计算机给男
性、30 岁的用户推送汽车广告。很明显如此粗略的规则不会有好效果,因为对

剩余11页未读,继续阅读
资源评论













