oracle_buffer_cache深入分析
需积分: 16 22 浏览量
2012-06-25
22:20:25
上传
评论
收藏 486KB PDF 举报


本文首先详细介绍了 oracle 中 buffer cache 的概念以及所包含的内存结构。然后结合各个
后台进程(包括 DBWRn、CKPT、LGWR 等)深入介绍了 oracle 对于 buffer cache 的管理
机制,并详细解释了 oracle 为什么会采用现在的管理机制,是为了解决什么问题。比如为
何会引入 touch 次数、为何会引入增量检查点等等。最后全面介绍了有关 buffer cache 监控
以及调优的实用方法。
1. buffer cache 的概念
用最简单的语言来描述 oracle 数据库的本质,其实就是能够用磁盘上的一堆文件来存储数
据,并提供了各种各样的手段对这些数据进行管理。作为管理数据的最基本要求就是能够保
存和读取磁盘上的文件中的数据。众所周知,读取磁盘的速度相对来说是非常慢的,而内存
相对速度则要快的多。因此为了能够加快处理数据的速度,oracle 必须将读取过的数据缓存
在内存里。而 oracle 对这些缓存在内存里的数据起了个名字:数据高速缓存区(db buffer
cache),通常就叫做 buffer cache。按照 oracle 官方的说法,buffer cache 就是一块含有
许多数据块的内存区域,而这些数据块主要都是数据文件里的数据块内容的拷贝。通过初始
化参数:buffer_cache_size 来指定 buffer cache 的大小。oracle 实例一旦启动,该区域大
小就被分配好了。
buffer cache 所能提供的功能主要包括:
1) 通过缓存数据块,从而减少 I/O。
2) 通过构造 CR 块,从而提供读一致性功能。
3) 通过提供各种 lock、latch 机制,从而提供多个进程并发访问同一个数据块的功能。
2.buffer cache 的内存结构
2.1 buffer cache 概述
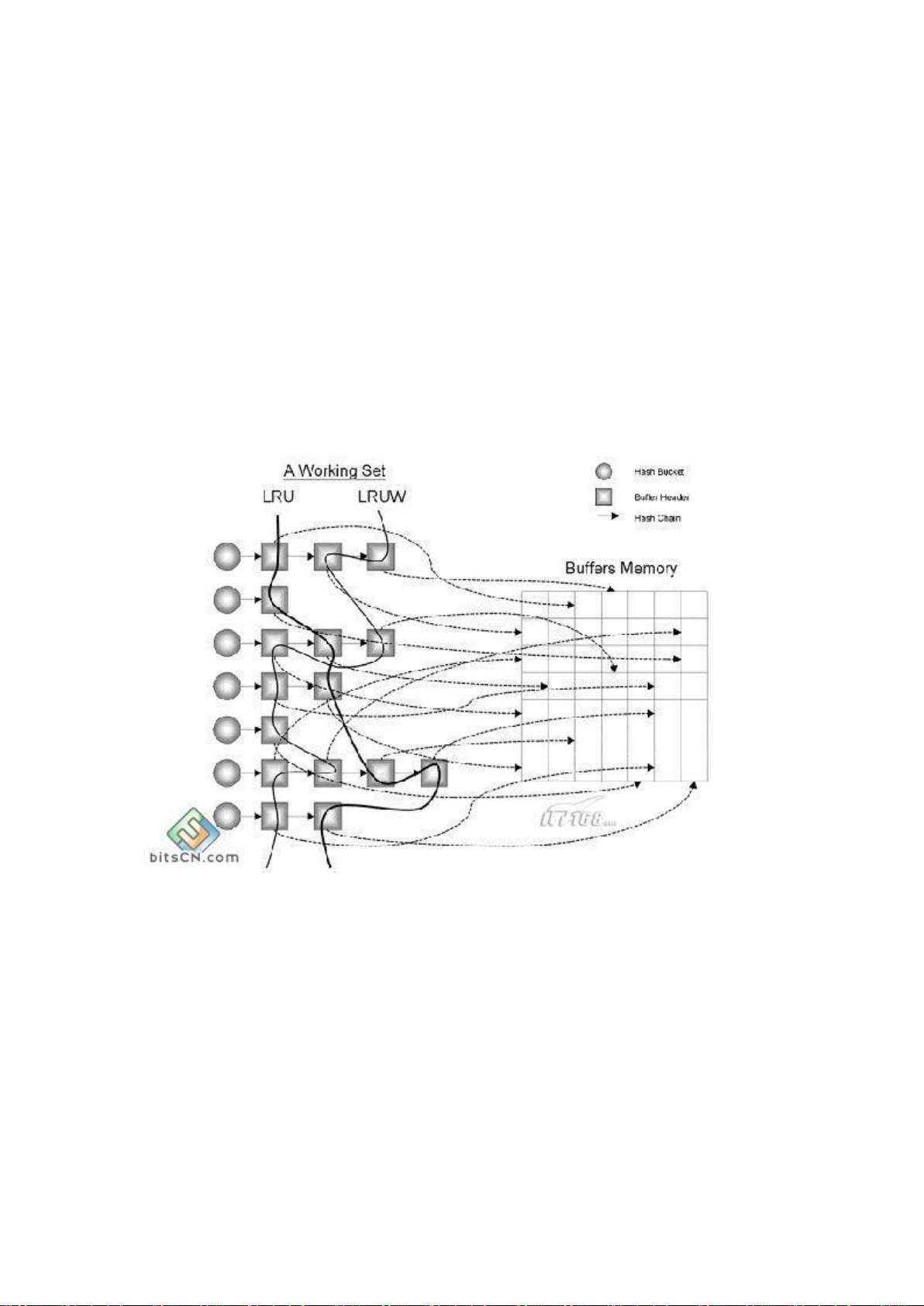
oracle 内部在实现其管理的过程中,有两个非常有名的名词:链表和 hash 算法。
链表是一种数据结构,通过将对象串连在一起,从而构成链表结构。这样,如果要修改、删
除、查找某个对象的话,都可以先到链表中去查找,而不必实际的访问物理介质。oracle
中最有名的链表大概就是 LRU 链表了,我们后面会介绍它。
而 hash 算法则是为了能够进行快速查找定位所使用一种技术。所谓 hash 算法,就是根
据要查找的值,对该值进行一定的 hash 算法后得出该值所在的索引号,然后进入到该值应
该存在的一列数值列表(可以理解为一个二维数组)里,通过该索引号去找它应该属于哪一
个列表。然后再进入所确定的列表里,对其中所含有的值,进行一个一个的比较,从而找到
该值。这样就避免了对整个数值列表进行扫描才能找到该值,这种全扫描的方式显然要比
hash 查找方式低效很多。其中,每个索引号对应的数值列在 oracle 里都叫做一个 hash
bucket。
我们来列举一个最简单的 hash 算法。假设我们的数值列表最多可以有 10 个元素,也就



剩余20页未读,继续阅读
资源评论













