

2021/2/2 Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick
mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/ 1/8
Chris McCormick
New BERT eBook + 11 Application Notebooks! → The BERT Collection
Word2Vec Tutorial - The Skip-Gram
Model
19 Apr 2016
This tutorial covers the skip gram neural network architecture for Word2Vec.
My intention with this tutorial was to skip over the usual introductory and
abstract insights about Word2Vec, and get into more of the details. Specifically
here I’m diving into the skip gram neural network model.
The Model
The skip-gram neural network model is actually surprisingly simple in its most
basic form; I think it’s all of the little tweaks and enhancements that start to
clutter the explanation.
Let’s start with a high-level insight about where we’re going. Word2Vec uses a
trick you may have seen elsewhere in machine learning. We’re going to train a
simple neural network with a single hidden layer to perform a certain task, but
then we’re not actually going to use that neural network for the task we trained
it on! Instead, the goal is actually just to learn the weights of the hidden layer–
we’ll see that these weights are actually the “word vectors” that we’re trying to
learn.
Another place you may have seen this trick is in unsupervised feature
learning, where you train an auto-encoder to compress an input vector in
the hidden layer, and decompress it back to the original in the output
layer. After training it, you strip off the output layer (the decompression
step) and just use the hidden layer--it's a trick for learning good image
features without having labeled training data.
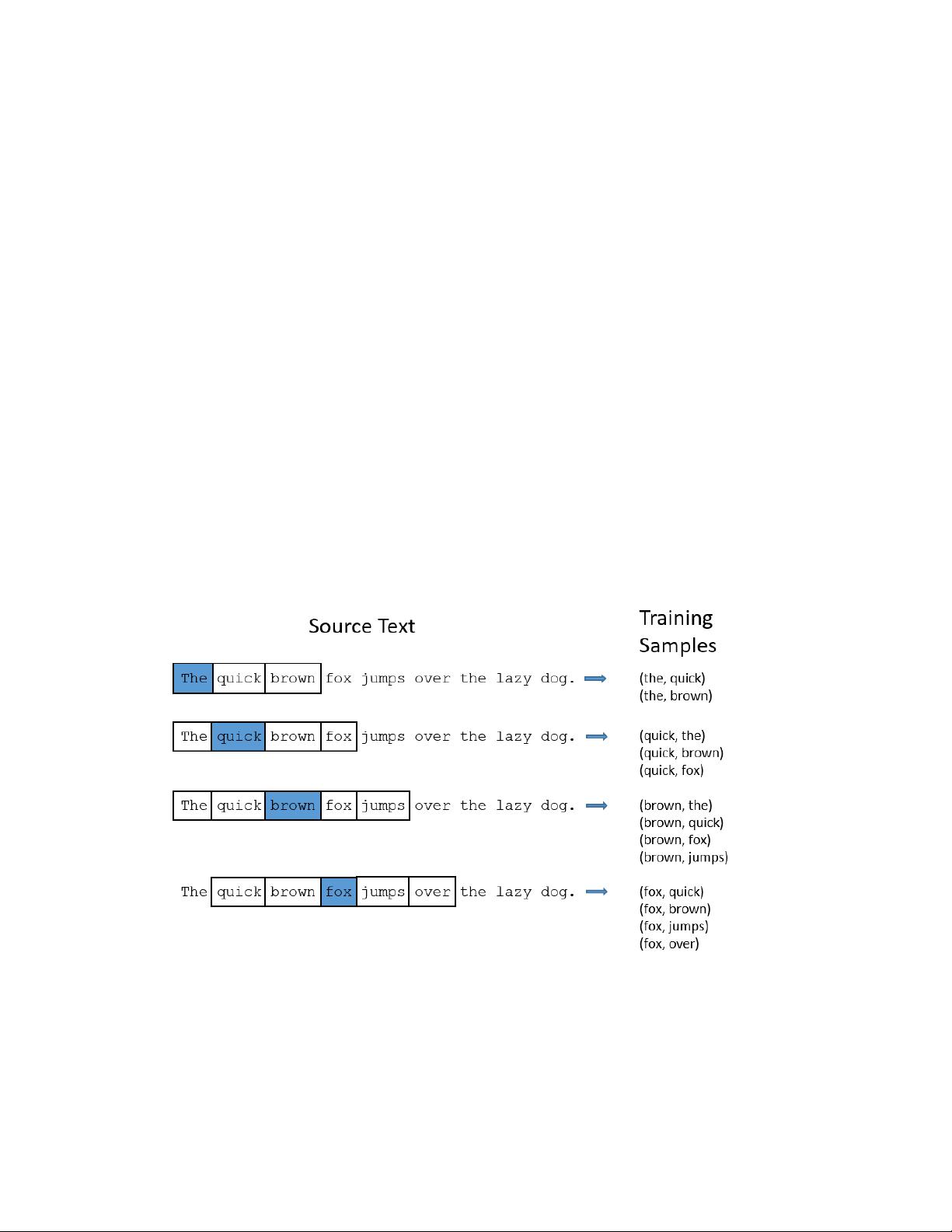
The Fake Task
So now we need to talk about this “fake” task that we’re going to build the
neural network to perform, and then we’ll come back later to how this
indirectly gives us those word vectors that we are really after.
About
Tutorials
Store
Archive
剩余7页未读,继续阅读
资源评论


da_pipi
- 粉丝: 2
- 资源: 1









最新资源
- MBR污水一体化处理系统(集装箱)工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- lattice diamond3.11的license文件
- vsvbxcygsyzgvytfvdyvs
- DJS-042-锁螺丝机方案工程图机械结构设计图纸和其它技术资料和技术方案非常好100%好用.zip
- FMASTERSW3.2版本
- qemu上运行Linux系统开启并验证IMA功能
- HE-Drive-main.zip
- mysql安装配置教程.txt
- mysql安装配置教程.txt
- mysql安装配置教程.txt
- 汇川伺服6V30-EOE-MXL文件-037515
- 2024中国CIO&CDO现状、挑战及未来趋势研究报告
- 鼠标连点器+自动单机+录制点击
- 4G DTU串口数据采集网关设计全套资料(源码、原理图、外壳文件、产品手册).zip
- 利用Python绘制装饰圣诞树的技术实例
- 测试程序:qabstractvideosurface
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


