
不论是 聚集索引, 还是非聚集索引, 都是用 B+树来实现的。 我们在了解这两种
索引之前,需要先了解 B+树。如果你对 B 树不了解的话,建议参看以下几篇文
章:
BTree,B-Tree,B+Tree,B*Tree 都是什么
http://blog.csdn.net/manesking/archive/2007/02/09/1505979.aspx
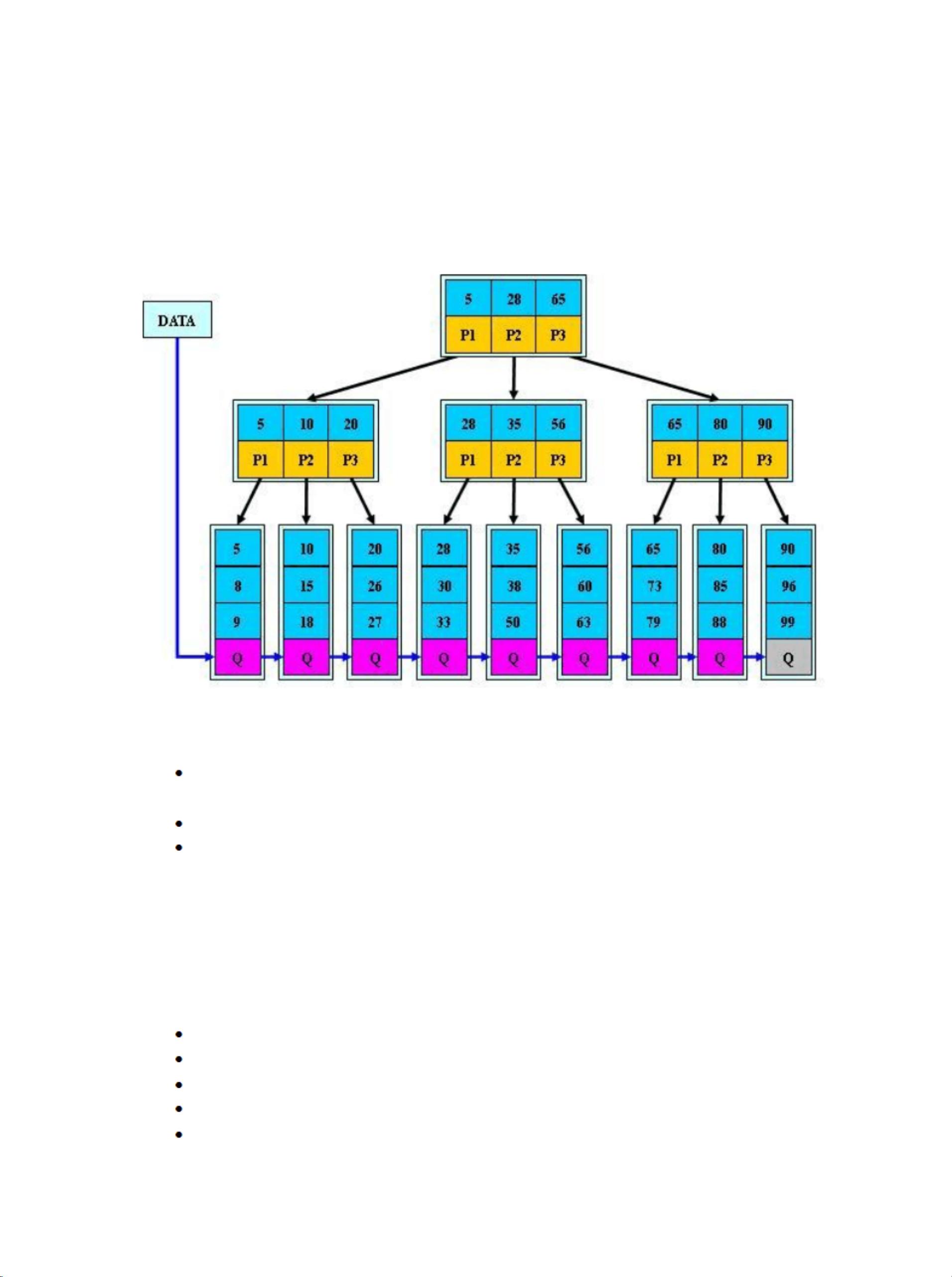
B+ 树的结构图 :
B+ 树的特点 :
所有关键字都出现在叶子结点的链表中 (稠密索引) ,且链表中的关键字
恰好是有序的;
不可能在非叶子结点命中;
非叶子结点相当于是叶子结点的索引 (稀疏索引) ,叶子结点相当于是存
储(关键字)数据的数据层;
B+ 树中增加一个数据,或者删除一个数据,需要分多种情况处理,比较复杂,
这里就不详述这个内容了。
聚集索引( Clustered Index )
聚集索引的叶节点就是实际的数据页
在数据页中数据按照索引顺序存储
行的物理位置和行在索引中的位置是相同的
每个表只能有一个聚集索引
聚集索引的平均大小大约为表大小的 5%左右
资源评论


czq131452007
- 粉丝: 2
- 资源: 12万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 小说网站-JAVA-基于springBoot“西贝”小说网站的设计与实现
- 游戏分享网站-JAVA-基于springBoot“腾达”游戏分享网站的设计与实现
- 学习交流-JAVA-基于springBoot“非学勿扰”学习交流平台设计与实现
- EDAfloorplanning
- 所有课程均提供 Python 复习部分.zip
- 所有算法均在 Python 3 中实现,是 hacktoberfest2020 的一个项目 - 没有针对 hacktoberfest 2021 的问题或 PR.zip
- OpenCV的用户手册资源.zip
- 用springmvc实现的校园选课管理系统
- 我的所有 Python 代码都存储在这个文件夹中 .zip
- 以下是关于毕业设计项目开发的详细资源.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


