
机器学习与数据挖掘复习
第一章:Introduction
1. 什么是数据挖掘:数据挖掘时从大量的数据中取出令人感兴趣的知识(令人感兴趣的知
识:有效地、新颖的、潜在有用的和最终可以理解的)。
2. 数据挖掘的分类(从一般功能上的分类):
a) 描述型数据挖掘(模式):聚类,summarization,关联规则,序列发现。
b) 预测型数据挖掘(值):分类,回归,时间序列分析,预测。
3. KDD(数据库中的知识发现)的概念:KDD 是一个选择和提取数据的过程,它能自动地发
现新的、精确的、有用的模式以及现实世界现象的模型。数据挖掘是 KDD 过程的一个主要的
组成部分。
4. 用数据挖掘解决实际问题的大概步骤:
a) 对数据进行 KDD 过程的处理来获取知识。
b) 用知识指导行动。
c) 评估得到的结果:好的话就循环使用,不好的话分析、得到问题然后改进。
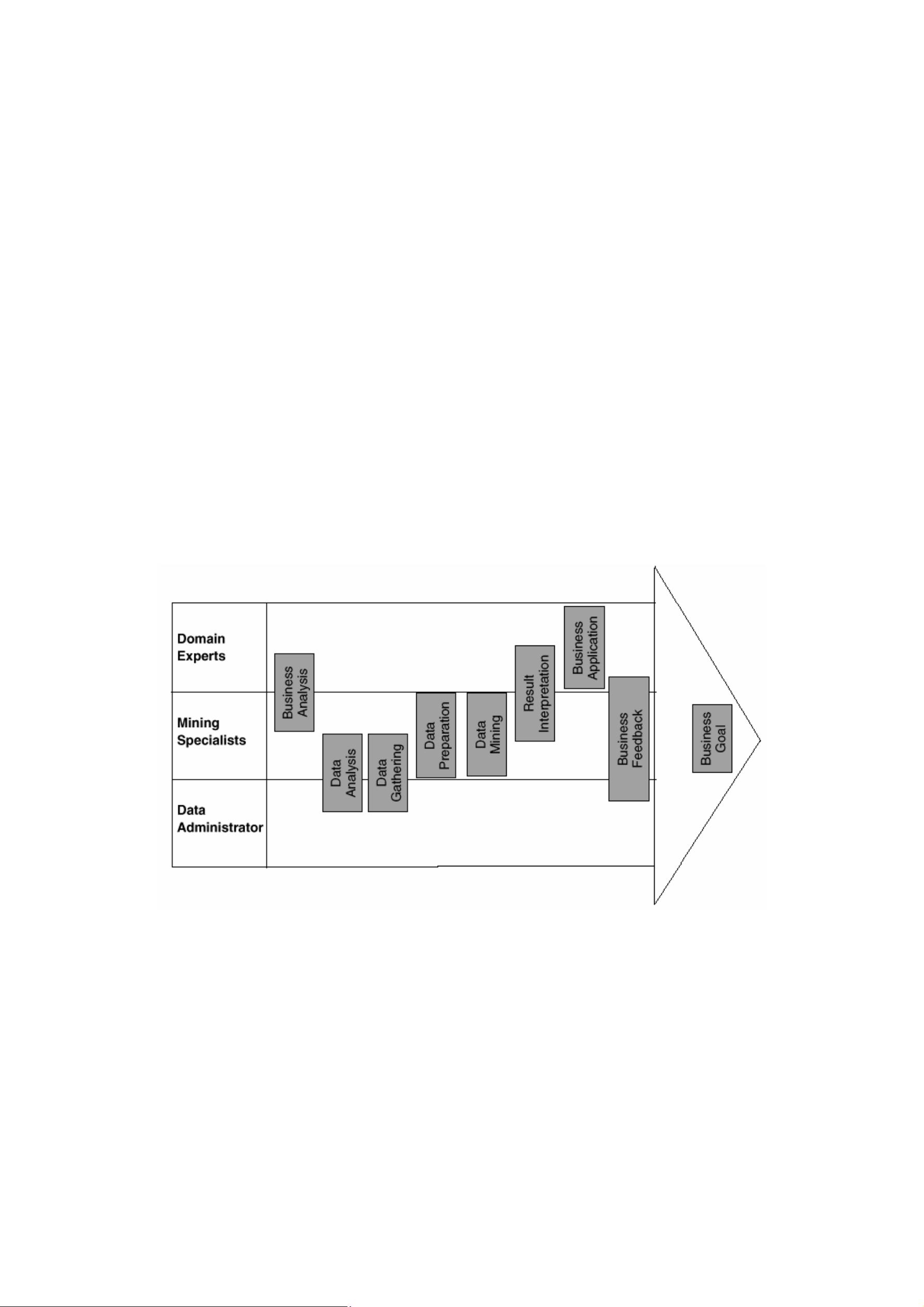
5. KDD 过程中的角色问题:
6. 整个 KDD 过程:
a) 合并多个数据源的数据。
b) 对数据进行选择和预处理。
c) 进行数据挖掘过程得到模式或者模型。
d) 对模型进行解释和评价得到知识。
1 / 13


剩余12页未读,继续阅读
资源评论


苦茶子12138
- 粉丝: 1w+
- 资源: 6万+









最新资源
- 现在微信小程序能用的mqtt.min.js
- 基于MPC的非线性摆锤系统轨迹跟踪控制matlab仿真,包括程序中文注释,仿真操作步骤
- 基于MATLAB的ITS信道模型数值模拟仿真,包括程序中文注释,仿真操作步骤
- 基于Java、JavaScript、CSS的电子产品商城设计与实现源码
- 基于Vue 2的zjc项目设计源码,适用于赶项目需求
- 基于跨语言统一的C++头文件设计源码开发方案
- 基于MindSpore 1.3的T-GCNTemporal Graph Convolutional Network设计源码
- 基于Java的贝塞尔曲线绘制酷炫轮廓背景设计源码
- 基于Vue框架的Oracle数据库实训大作业设计与实现源码
- 基于SpringBoot和Vue的共享单车管理系统设计源码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


