

Gi from the bottom up
Wed, Dec
by John Wiegley
In my pursuit to understand Git, it’s been helpful for me to understand it from the bottom
up — rather than look at it only in terms of its high-level commands. And since Git is so beauti-
fully simple when viewed this way, I thought others might be interested to read what I’ve found,
and perhaps avoid the pain I went through finding it.
I used Git version 1.5.4.5 for each of the examples found in this document.
Contents
1. License 2
2. Introduction 3
3. Repository: Directory content tracking 5
Introducing the blob 6
Blobs are stored in trees 7
How trees are made 8
e beauty of commits 10
A commit by any other name… 12
Branching and the power of rebase 15
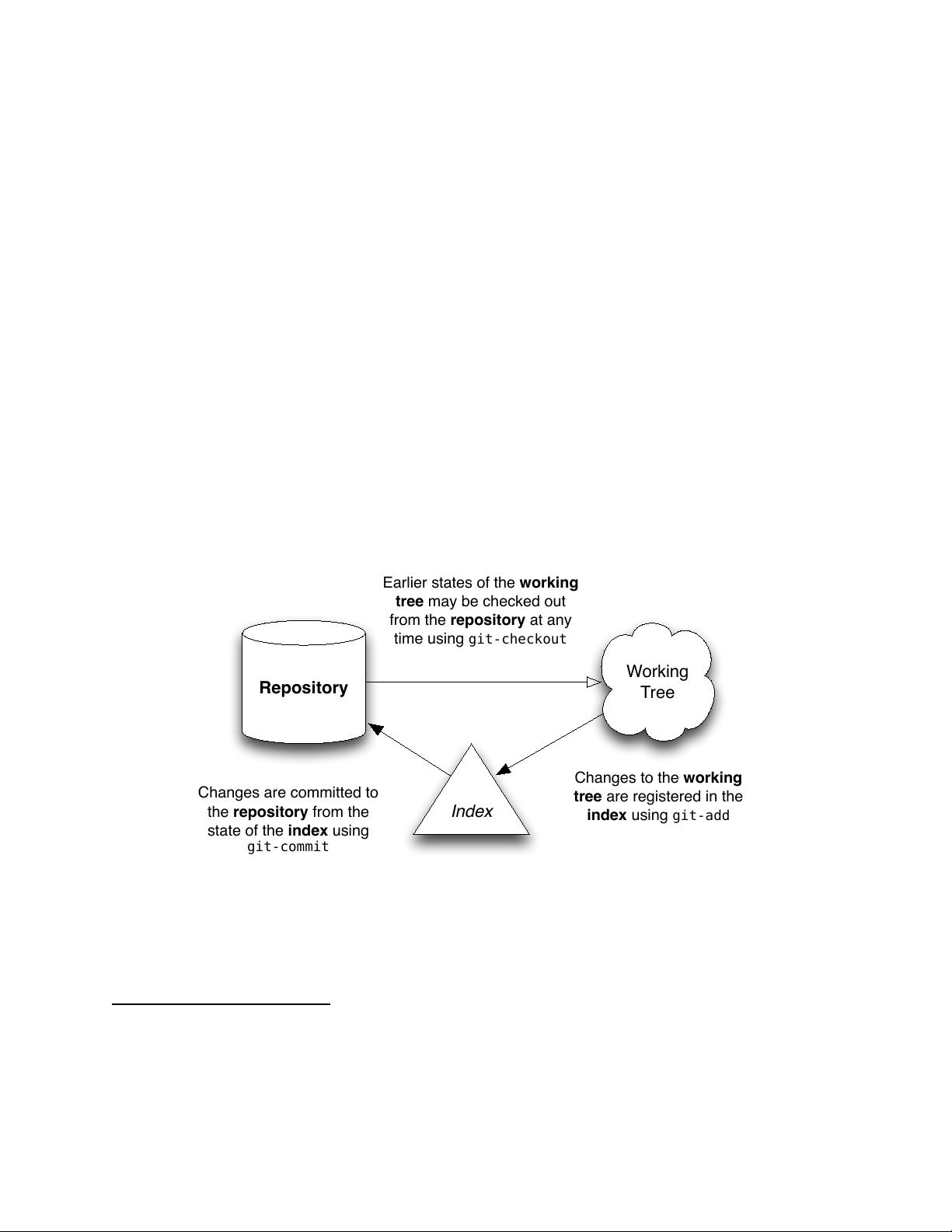
4. e Index: Meet the middle man 20
Taking the index farther 22
5. To reset, or not to reset 24
Doing a mixed reset 24
Doing a so reset 24
Doing a hard reset 25
6. Last links in the chain: Stashing and the reflog 27
7. Conclusion 30
8. Further reading 31



剩余30页未读,继续阅读
资源评论


coldturnip
- 粉丝: 0
- 资源: 2









最新资源
- 《能源转型投资展望:2025年及长远规划》.pdf
- PPTAAD DADAA
- SM2258XT-BGA144-4BGA180-6L-R1019 三星KLUCG4J1CB B0B1颗粒开盘工具 , EC, 3A, 94, 43, A4, CA 七彩虹SL300这个固件有用
- 基于Java开发的日程管理FlexTime应用设计源码
- 基于JavaScript、CSS、HTML的简易DOM版飞机游戏设计源码
- 【C++初级程序设计·配套源码】第1期-语法基础
- 基于华为消费者业务官网的仿制前端首页设计源码
- 影驰战将PS3111 东芝芯片TT18G23AIN开卡成功分享,图片里面画线的选项很重要
- 基于Java和Vue的kopsoftKANBAN车间电子看板设计源码
- 基于Go语言的SharpWxDump微信取证信息分析设计源码
- 基于C语言的USB光盘资料操作教学源码
- 基于GitHub的TypeScript文档中文翻译设计源码
- 【C++初级程序设计·配套源码】第2期-基本数据类型
- 基于Vue和SpringBoot的企业员工管理系统2.0版本设计源码
- 没用333333333333333333333333333333
- C++ STL 高级教程深入浅出版.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


