
经过好几天的尝试,终于成功在 windows7 的环境下将 nutch 成功运行出来了,下面将经验
记下。
1、cygwin 的安装:下载地址: http://www.cygwin.com/setup.exe
(1)因为 nutch 自身的命令是要在 linux 环境下才能运行,所以先安装了 cygwin,Cygwin
是一个在 Windows 下的模拟 Linux 系统程序。Cygwin 的安装:
http://www.programarts.com/cfree_ch/doc/help/UsingCF/CompilerSupport/Cygwin/
Cygwin1.htm
这个网址对 cygwin 的安装步骤演示的很详细,对我们这些初步接触 cygwin 的人有很大的
帮助。
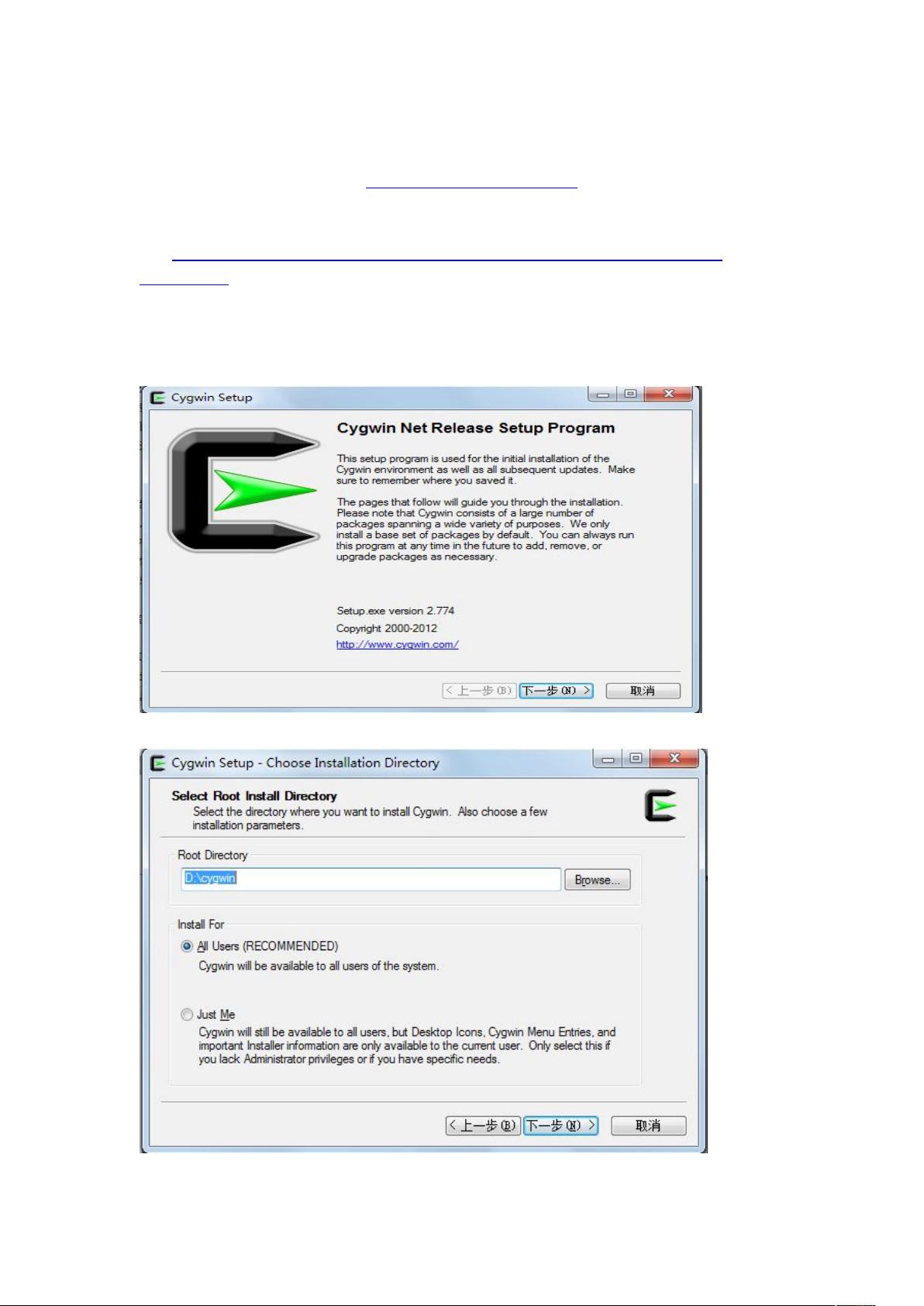
(2)下面是我自己安装时的截图
1)安装页面,点击下一步
2)选择安装目录,可以根据默认,也可以根据自己需要换路径
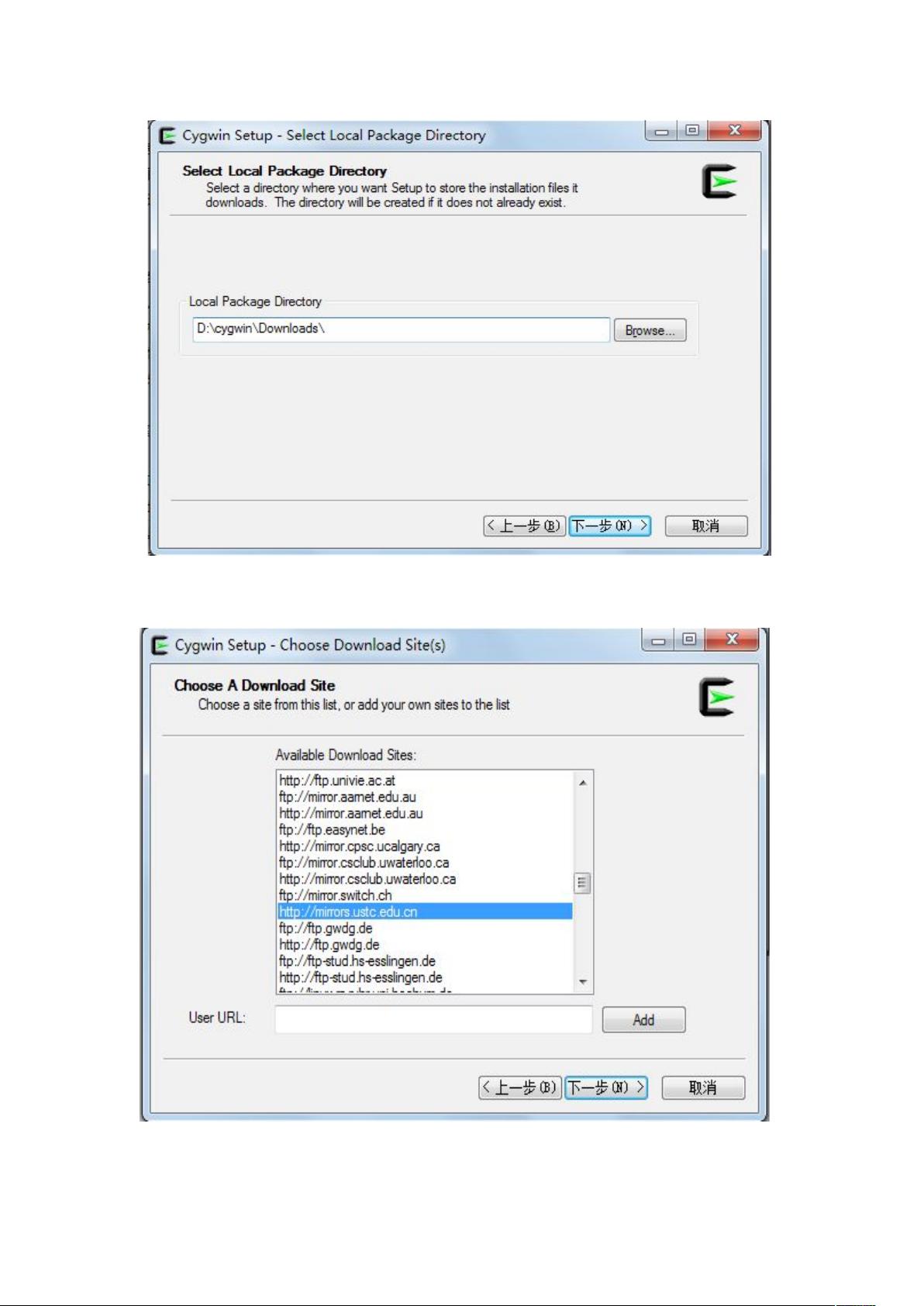
3)建立 Downloads 文件夹,接收下载包
剩余9页未读,继续阅读
资源评论

 xiaojun90812013-10-11很详细的文档
xiaojun90812013-10-11很详细的文档











