
语音算法原理介绍
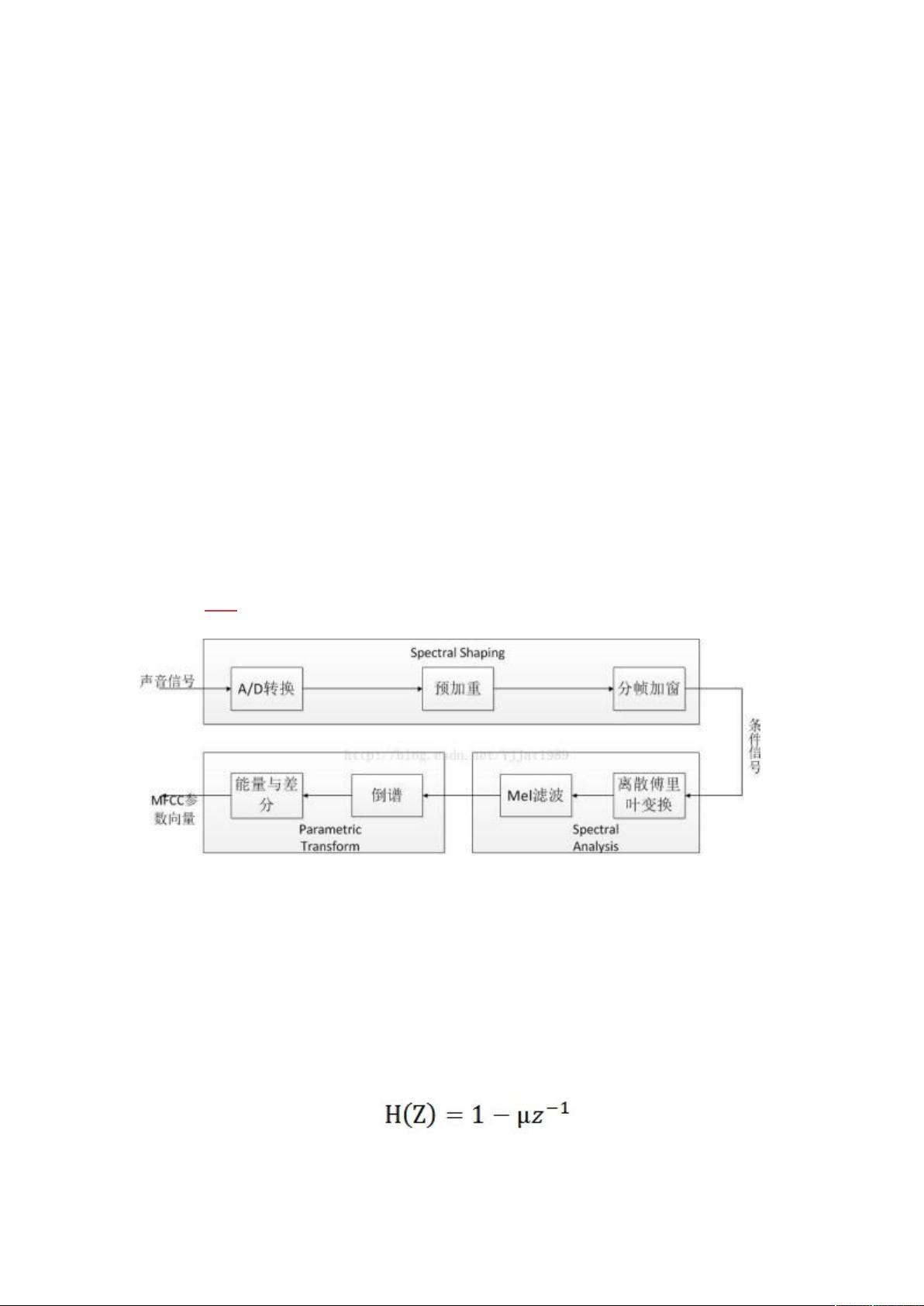
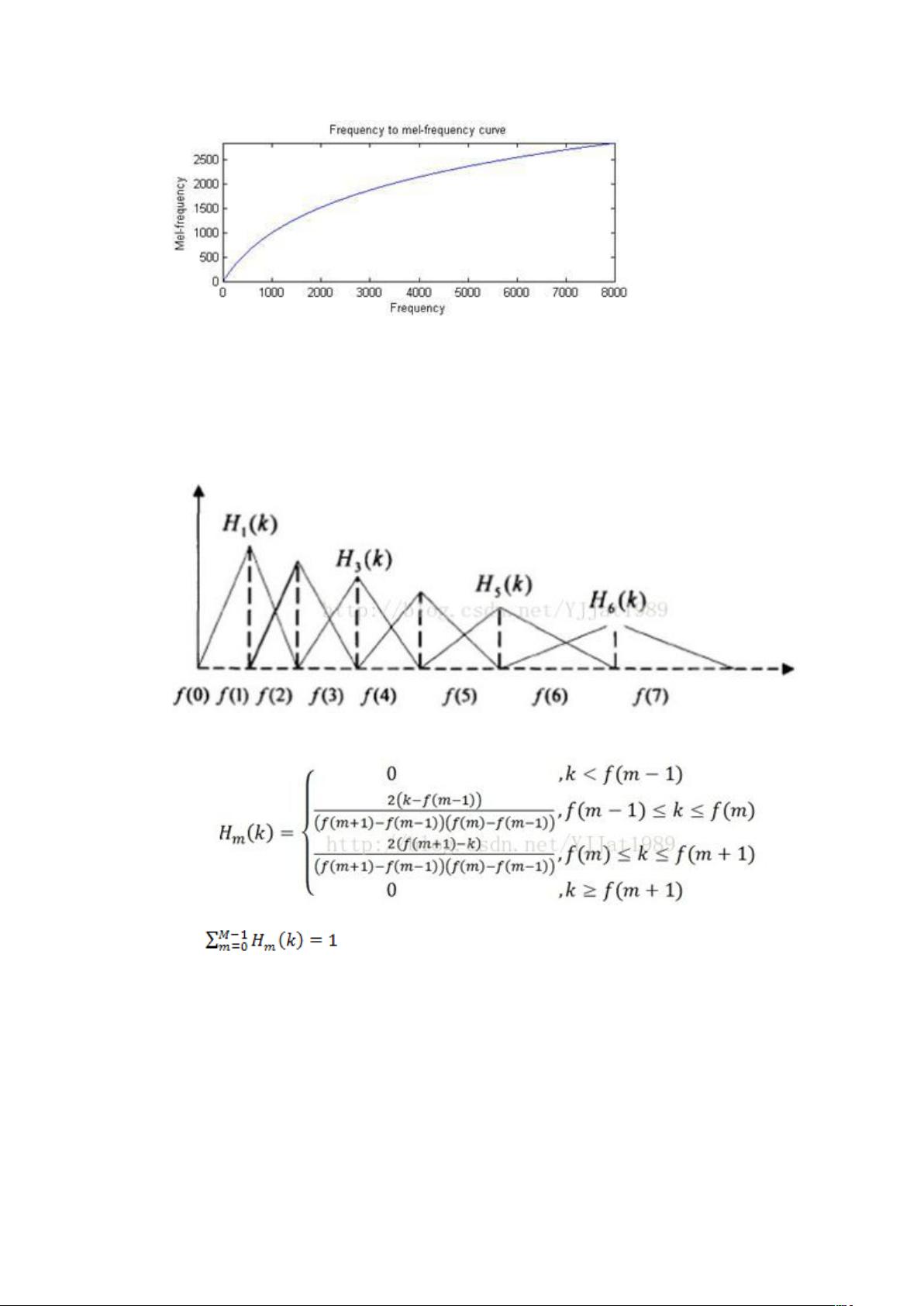
MFCC 提取过程
声音是模拟信号,声音的时域波形只代表声压随时间变化的关系,不能很好的代表声
音的特征,因此,必须将声音波形转换为声学特征向量。目前有许多声音特征提取方法,
如梅尔频率倒谱系数 、线性预测倒谱系数 、多媒体内容描述接口 等,
其中 是基于倒谱的,更符合人的听觉原理,因而是最普遍、最有效的声音特征提取
算法。在提取 前,需要对声音做前期处理,包括模数转换、预加重和加窗。
模数转换就是把模拟信号转换为数字信号,包括两个步骤:采样和量化,即以一定的
采样率和采样位数把声音连续波形转换为离散的数据点。由于日常生活中的声音一般都在
以下,根据 定律, 采样率足以使得采样出来的数据包含大多数声音
信息。 意味着 的时间内采样 个样本,这些样本都是以幅度值存储,为了有
效 存 储 幅 度 值 , 需 要 将 其 量 化 为 整 数 。 对 于 位 采 样 位 数 来 说 , 可 以 表 示
之间的整数值,所以可以将采样幅度值量化为最近的整数值。
采样和量化后的波形表示为 ,其中 是时间索引。然后可以对 做 特
征提取,算法流程图如图:
一、预加重-
特征提取的第一步是增加声音高频部分的能量。对于声音信号的频谱来说,往
往低频部分的能量高于高频部分的能量,每经过 倍 ,频谱能量就会衰减 !,为
了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,
此外为使高频部分的能量和低频部分能量有相似的幅度,使信号的频谱变得平坦,保持在
低频到高频的整个频带中,能用同样的信噪比求频谱"则需要提升高频部分的能量。加强高
频部分的能量能使声学模型更好的利用高频共振峰,从而提高识别准确率。
预加重可以通过一个一阶高通滤波器实现,在时域,如果输入信号是 "并且式中 #
的值介于 $%$ 之间,我们通常取 $%,滤波器表示为 &#;在频域
则表示为'
二、分帧加窗---


剩余52页未读,继续阅读
资源评论













