

使用 HttpClient 和 HtmlParser 实现简易爬虫
这篇文章介绍了 HtmlParser 开源包和 HttpClient 开源包的使用,在此基础上实现了一个简易的网络
爬虫 (Crawler) ,来说明如何使用 HtmlParser 根据需要处理 Internet 上的网页,以及如何使用
HttpClient 来简化 Get 和 Post 请求操作,构建强大的网络应用程序。
HttpClient 与 HtmlParser 简介
本小结简单的介绍一下 HttpClinet 和 HtmlParser 两个开源的项目,以及他们的网站和提供下载的地
址。
HttpClient 简介
HTTP 协议是现在的因特网最重要的协议之一。除了 WEB 浏览器之外, WEB 服务,基于网络的应
用程序以及日益增长的网络计算不断扩展着 HTTP 协议的角色,使得越来越多的应用程序需要
HTTP 协议的支持。虽然 JAVA 类库 .net 包提供了基本功能,来使用 HTTP 协议访问网络资源,但
是其灵活性和功能远不能满足很多应用程序的需要。而 Jakarta Commons HttpClient 组件寻求提供更
为灵活,更加高效的 HTTP 协议支持,简化基于 HTTP 协议的应用程序的创建。 HttpClient 提供了
很多的特性,支持最新的 HTTP 标准,可以访问这里了解更多关于 HttpClinet 的详细信息。目前有
很多的开源项目都用到了 HttpClient 提供的 HTTP 功能,登陆网址可以查看这些项目。本文中使用
HttpClinet 提供的类库来访问和下载 Internet 上面的网页,在后续部分会详细介绍到其提供的两种请
求网络资源的方法: Get 请求和 Post 请求。Apatche 提供免费的 HTTPClien t 源码和 JAR 包下载,
可以登陆这里 下载最新的 HttpClient 组件。笔者使用的是 HttpClient3.1。
HtmlParser 简介
当今的 Internet 上面有数亿记的网页,越来越多应用程序将这些网页作为分析和处理的数据对象。
这些网页多为半结构化的文本,有着大量的标签和嵌套的结构。当我们自己开发一些处理网页的应
用程序时,会想到要开发一个单独的网页解析器,这一部分的工作必定需要付出相当的精力和时间。
事实上,做为 JAVA 应用程序开发者, HtmlParser 为其提供了强大而灵活易用的开源类库,大大节
省了写一个网页解析器的开销。 HtmlParser 是 http://sourceforge.net 上活跃的一个开源项目,它提供
了线性和嵌套两种方式来解析网页,主要用于 html 网页的转换(Transformation) 以及网页内容的抽
取 (Extraction)。HtmlParser 有如下一些易于使用的特性:过滤器 (Filters) ,访问者模式 (Visitors),
处理自定义标签以及易于使用的 JavaBeans 。正如 HtmlParser 首页所说:它是一个快速,健壮以及
严格测试过的组件;以它设计的简洁,程序运行的速度以及处理 Internet 上真实网页的能力吸引着
越来越多的开发者。 本文中就是利用 HtmlParser 里提取网页里的链接,实现简易爬虫里的关键部
分。HtmlParser 最新的版本是 HtmlParser1.6 ,可以登陆这里下载其源码、 API 参考文档以及 JAR 包。
开发环境的搭建
笔者所使用的开发环境是 Eclipse Europa ,此开发工具可以在 www.eclipse.org 免费的下载;JDK 是
1.6 ,你也可以在 www.java.sun.com 站点下载,并且在操作系统中配置好环境变量。在 Eclipse 中创
建一个 JAVA 工程,在工程的 Build Path 中导入下载的 Commons-httpClient3.1.Jar,htmllexer.jar 以
及 htmlparser.jar 文件。
图 1. 开发环境搭建
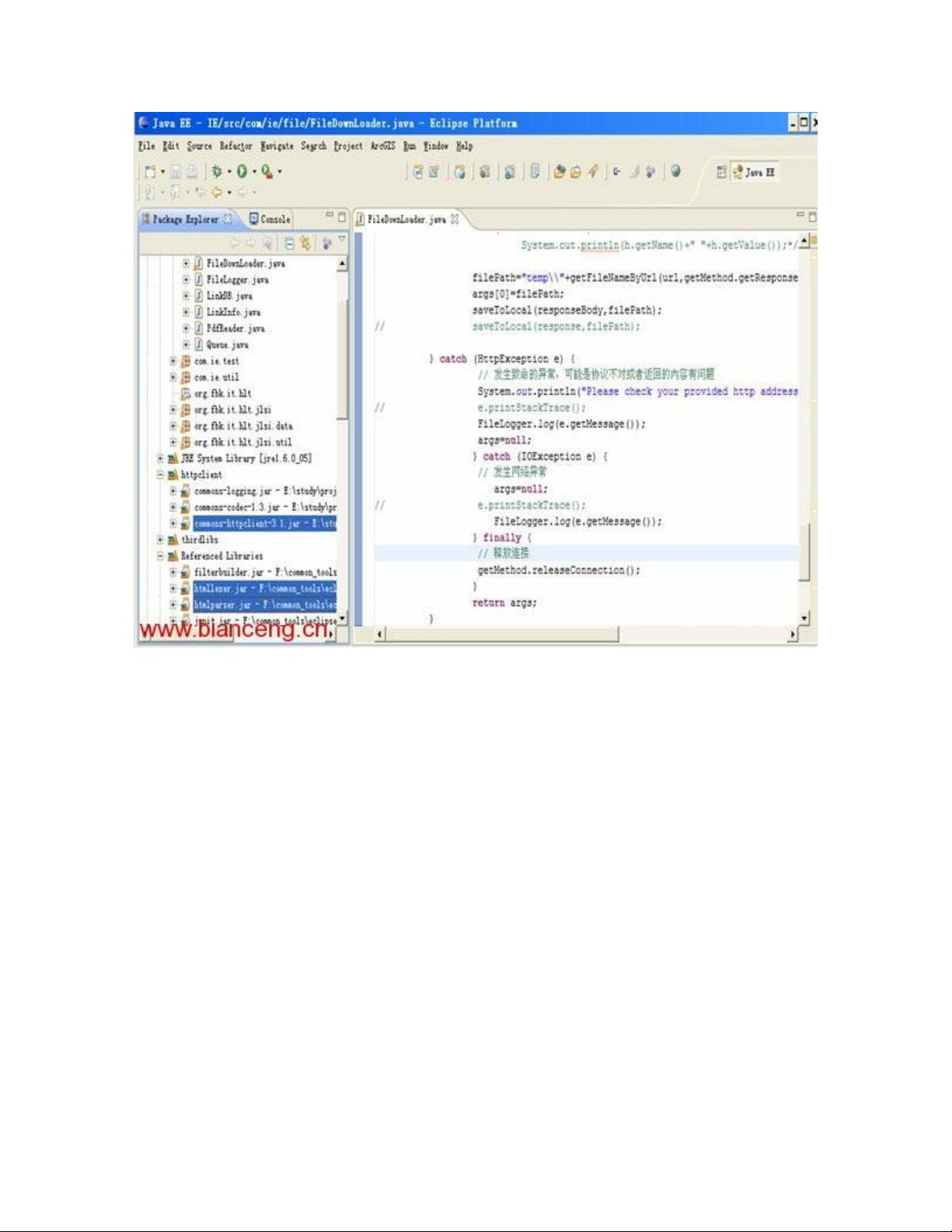

剩余13页未读,继续阅读

chenxiaowei715
- 粉丝: 0
- 资源: 4









最新资源
- Java Web实现电子购物系统
- (30485858)SSM(Spring+springmvc+mybatis)项目实例.zip
- (172760630)数据结构课程设计文档1
- 基于simulink的悬架仿真模型,有主动悬架被动悬架天棚控制半主动悬架 1基于pid控制的四自由度主被动悬架仿真模型 2基于模糊控制的二自由度仿真模型,对比pid控制对比被动控制,的比较说明
- (175184224)点餐小程序源码.rar
- NVR-K51-BL-CN-V4.50.010-210322
- (174517644)Drawing1(1).dwg
- Java Web开发短消息系统
- 空气流注放电模型,采用等离子体模块,包含多种化学反应 空气流注放电模型,采用等离子体模块,包含多种化学反应 Comsol等离子体模块 空气棒板放电 11种化学反应 放的是求的速率 碰撞界面数据在bol
- (175619628)两相交错并联LLC谐振变换器,均流和不均流方式都有,联系前请注明是否均流 模型均可实现输出电压闭环控制 第二幅波形图模拟的效果为
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页