1、hadoop3.1.4简单介绍及部署、简单验证
需积分: 0 42 浏览量
2023-05-29
13:44:27
上传
评论
收藏 1.45MB PDF 举报

本文介绍hadoop的发展过程、3.1.4的特性、部署及简单验证。
本文前提依赖:免密登录设置、jdk已经安装、zookeeper部署完成且正常运行。具体参见相关文章,具
体在zookeeper专栏、环境配置。
本文分为三个部分介绍,即hadoop发展史、hadoop3.1.4部署及验证。
@TOC
一、hadoop发展史
1、Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件
平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
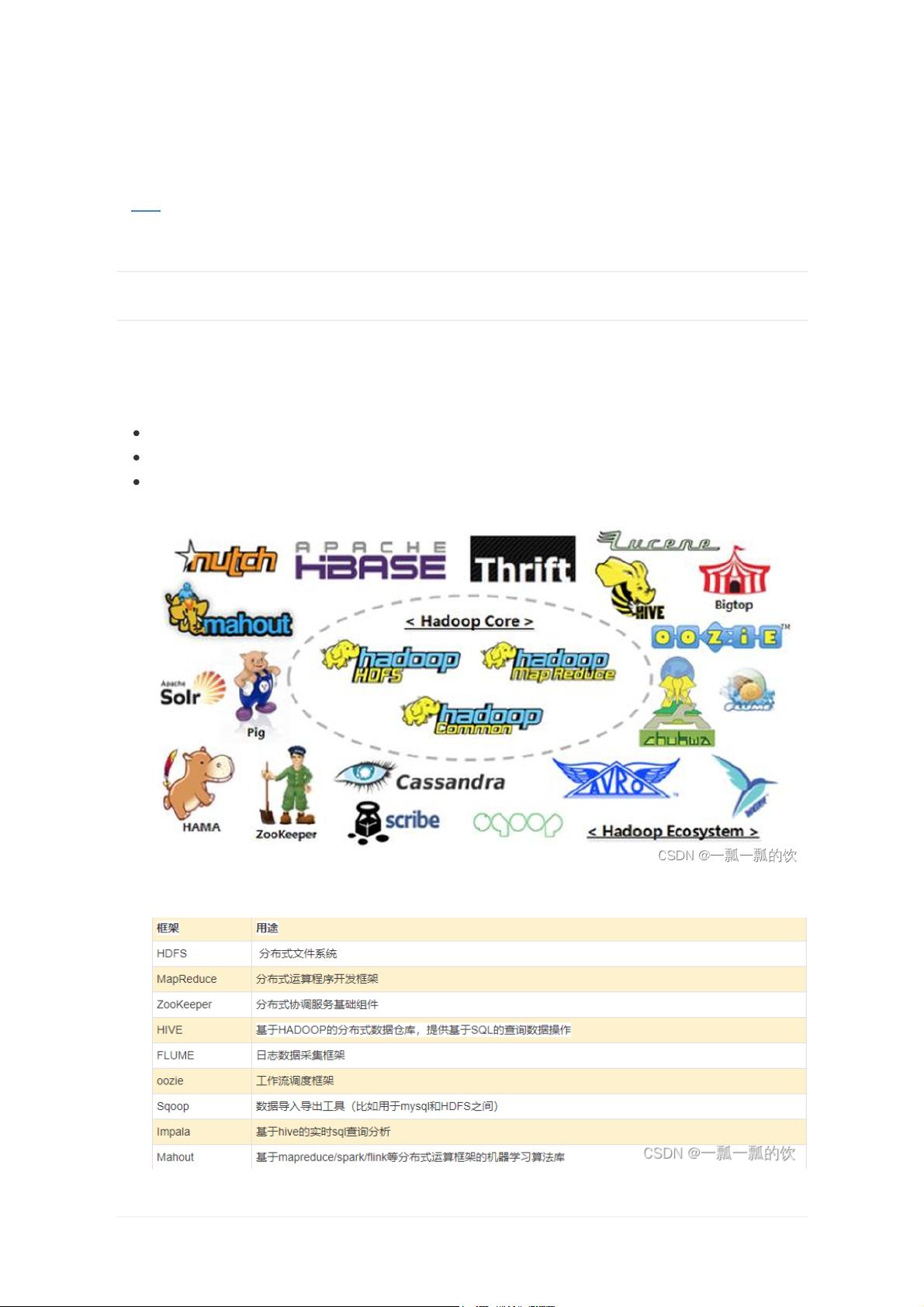
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
YARN(作业调度和集群资源管理的框架):解决资源任务调度
MAPREDUCE(分布式运算编程框架):解决海量数据计算
Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中
不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如:
2、Hadoop发展简史
Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。



剩余40页未读,继续阅读
资源评论













