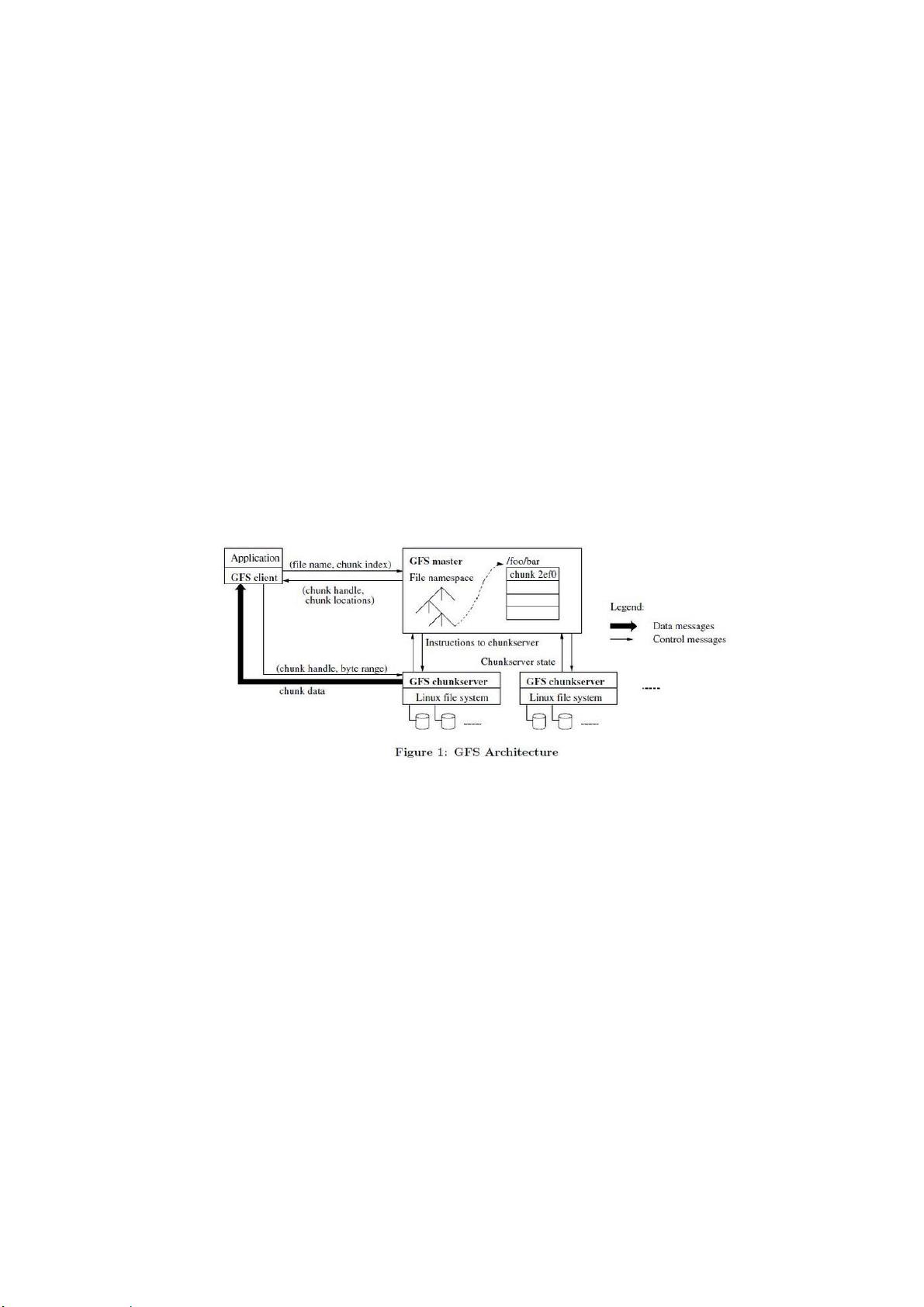
1
TheGoogleFileSystem 中文版
译者:alex
摘要
我们设计并实现了 Google 文件系统(GFS),一个面向大规模数据密集型应用的、可伸
缩的分布式文件系统。GFS 虽然运行在廉价的普遍硬件设备上,但是它依然了提供灾难冗余
的能力,为大量客户机提供了高性能的服务。
虽然 GFS 的设计目标与许多传统的分布式文件系统有很多相同之处,但是,我们的设计
还是以我们对自己的应用的负载情况和技术环境的分析为基础的,不管现在还是将来,GFS
和早期的分布式文件系统的设想都有明显的不同。所以我们重新审视了传统文件系统在设计
上的折衷选择,衍生出了完全不同的设计思路。
GFS 完全满足了我们对存储的需求。GFS 作为存储平台已经被广泛的部署在 Google 内
部,存储我们的服务产生和处理的数据,同时还用于那些需要大规模数据集的研究和开发
工作。目前为止,最大的一个集群利用数千台机器的数千个硬盘,提供了数百 TB 的存储空
间,同时为数百个客户机服务。
在本论文中,我们展示了能够支持分布式应用的文件系统接口的扩展,讨论我们设计的
许多方面,最后列出了小规模性能测试以及真实生产系统中性能相关数据。
分类和主题描述 D[4]:3—D 分布文件系统
常用术语 设计,可靠性,性能,测量
关键词 容错,可伸缩性,数据存储,集群存储
1 简介
为了满足 Google 迅速增长的数据处理需求,我们设计并实现了 Google 文件系统(Google
FileSystem–GFS)。GFS 与传统的分布式文件系统有着很多相同的设计目标,比如,性能、
可伸缩性、可靠性以及可用性。但是,我们的设计还基于我们对我们自己的应用的负载情
况和技术环境的观察的影响,不管现在还是将来,GFS 和早期文件系统的假设都有明显的
不同。所以我们重新审视了传统文件系统在设计上的折衷选择,衍生出了完全不同的设计
思路。
首先,组件失效被认为是常态事件,而不是意外事件。GFS 包括几百甚至几千台普通的
廉价设备组装的存储机器,同时被相当数量的客户机访问。GFS 组件的数量和质量导致在
事实上,任何给定时间内都有可能发生某些组件无法工作,某些组件无法从它们目前的失
效状态中恢复。我们遇到过各种各样的问题,比如应用程序 bug、操作系统的 bug、人为失
误,甚至还有硬盘、内存、连接器、网络以及电源失效等造成的问题。所以,持续的监
控、错误侦测、灾难冗余以及自动恢复的机制必须集成在 GFS 中。
其次,以通常的标准衡量,我们的文件非常巨大。数 GB 的文件非常普遍。每个文件通
常都包含许多应用程序对象,比如 web 文档。当我们经常需要处理快速增长的、并且由数
亿个对象构成的、数以 TB 的数据集时,采用管理数亿个 KB 大小的小文件的方式是非常不
明智的,尽管有些文件系统支持这样的管理方式。因此,设计的假设条件和参数,比如 I/O
操作和 Block 的尺寸都需要重新考虑。
第三,绝大部分文件的修改是采用在文件尾部追加数据,而不是覆盖原有数据的方式。
对文件的随机写入操作在实际中几乎不存在。一旦写完之后,对文件的操作就只有读,而
且通常是按顺序读。大量的数据符合这些特性,比如:数据分析程序扫描的超大的数据