

概述
http://www.cnblogs.com/zhangningbo/p/4146398.html
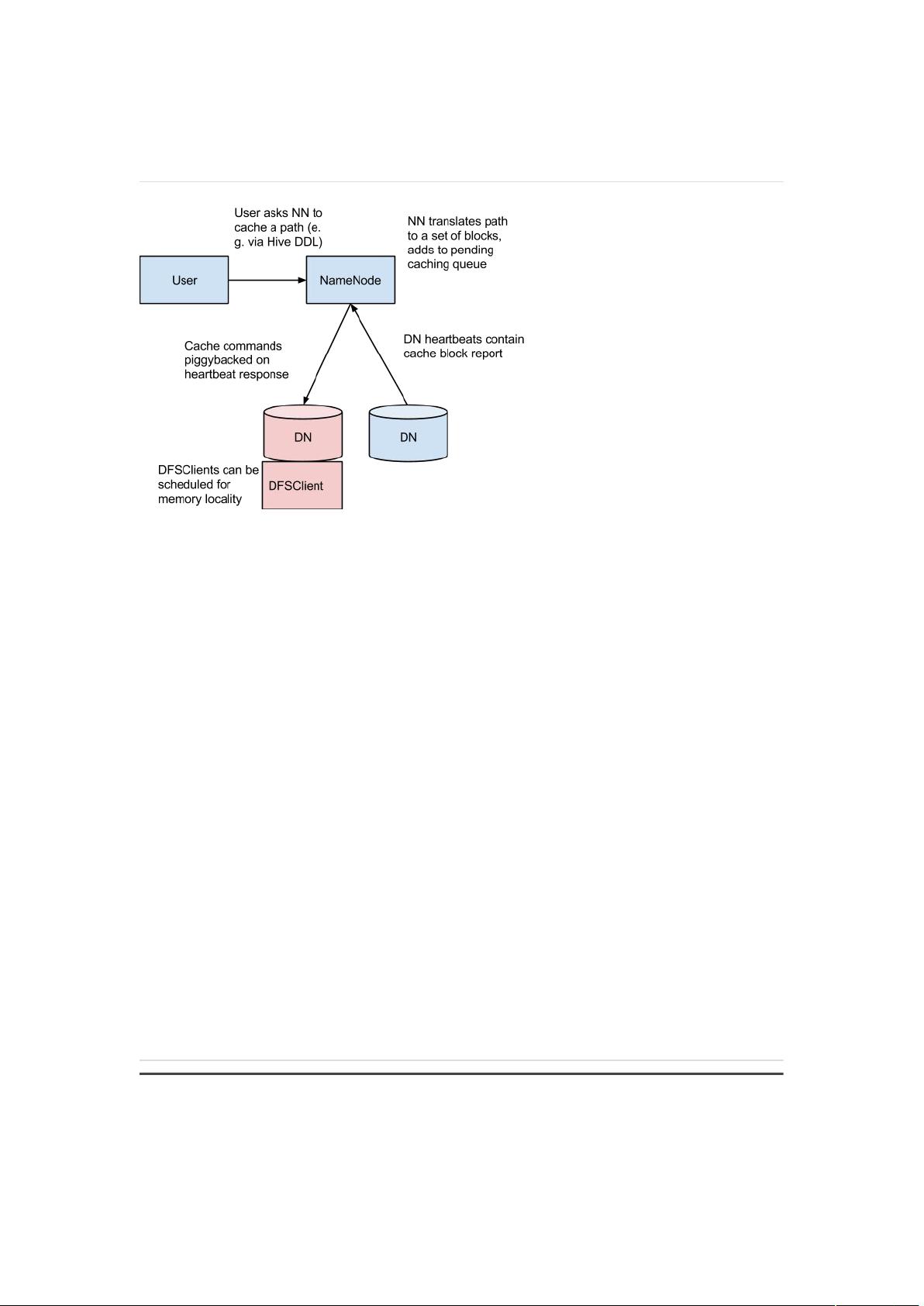
HDFS 中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的 HDFS 路径。
NameNode 会和保存着所需快数据的所有 DataNode 通信,并指导他们把块数据缓存在
o!-heap 缓存中。
HDFS 集中化缓存管理具有许多重大优势:
1.明确的锁定可以阻止频繁使用的数据被从内存中清除。当工作集的大小超过了主内存大
小(这种情况对于许多 HDFS 负载都是司空见惯的)时,这一点尤为重要。
2.由于 DataNode 缓存是由 NameNode 管理的,所以,在确定任务放置位置时,应用程
序可以查询一组缓存块位置。把任务和缓存块副本放在一个位置上可以提高读操作的性能。
3.当块已经被 DataNode 缓存时,客户端就可以使用一个新的更高效的零拷贝读操作
API。因为缓存数据的 checksum 校验只需由 DataNode 执行一次,所以,使用这种新
API 时,客户端基本上不会有开销。
4.集中缓存可以提高整个集群的内存使用率。当依赖于每个 DataNode 上操作系统的
bu!er 缓存时,重复读取一个块数据会导致该块的 N 个副本全部被送入 bu!er 缓存。使
用集中化缓存管理,用户就能明确地只锁定这 N 个副本中的 M 个了,从而节省了 N-M 的
内存量。
使用场景
集中化缓存管理对于重复访问的文件很有用。例如, Hive 中的一个较小的 fact 表(常常
用于 joins 操作)就是一个很好的缓存对象。另一方面,对于一个全年报表查询的输入数
据做缓存很可能就没有多大作用了,因为,历史数据只会读取一次。
集中化缓存管理对于带有性能 SLA(Service-Level Agreement)的混合负载也很有用。
缓存正在使用的高优先级负载可以保证它不会和低优先级负载竞争磁盘 I/O。
剩余7页未读,继续阅读
资源评论













