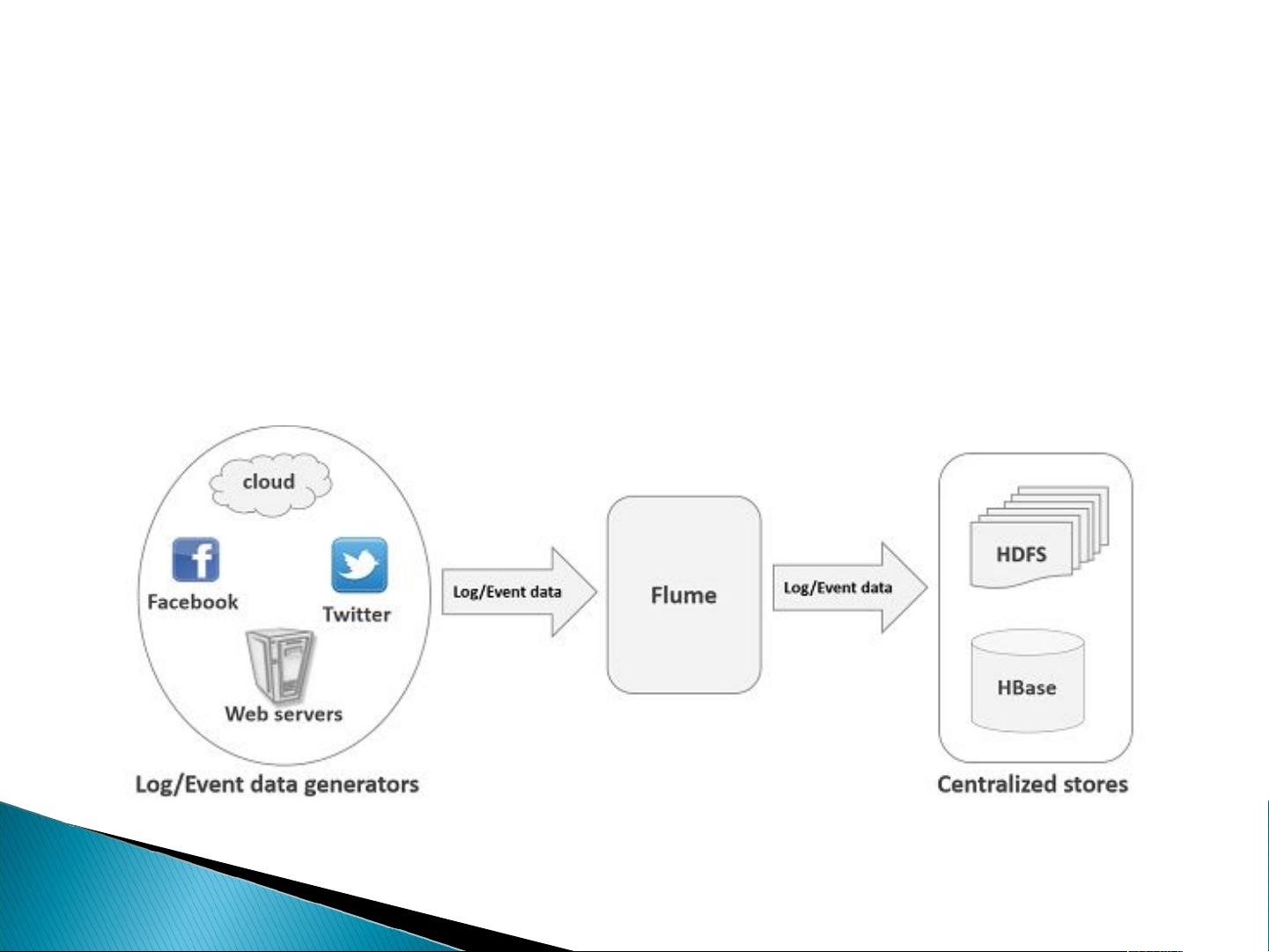
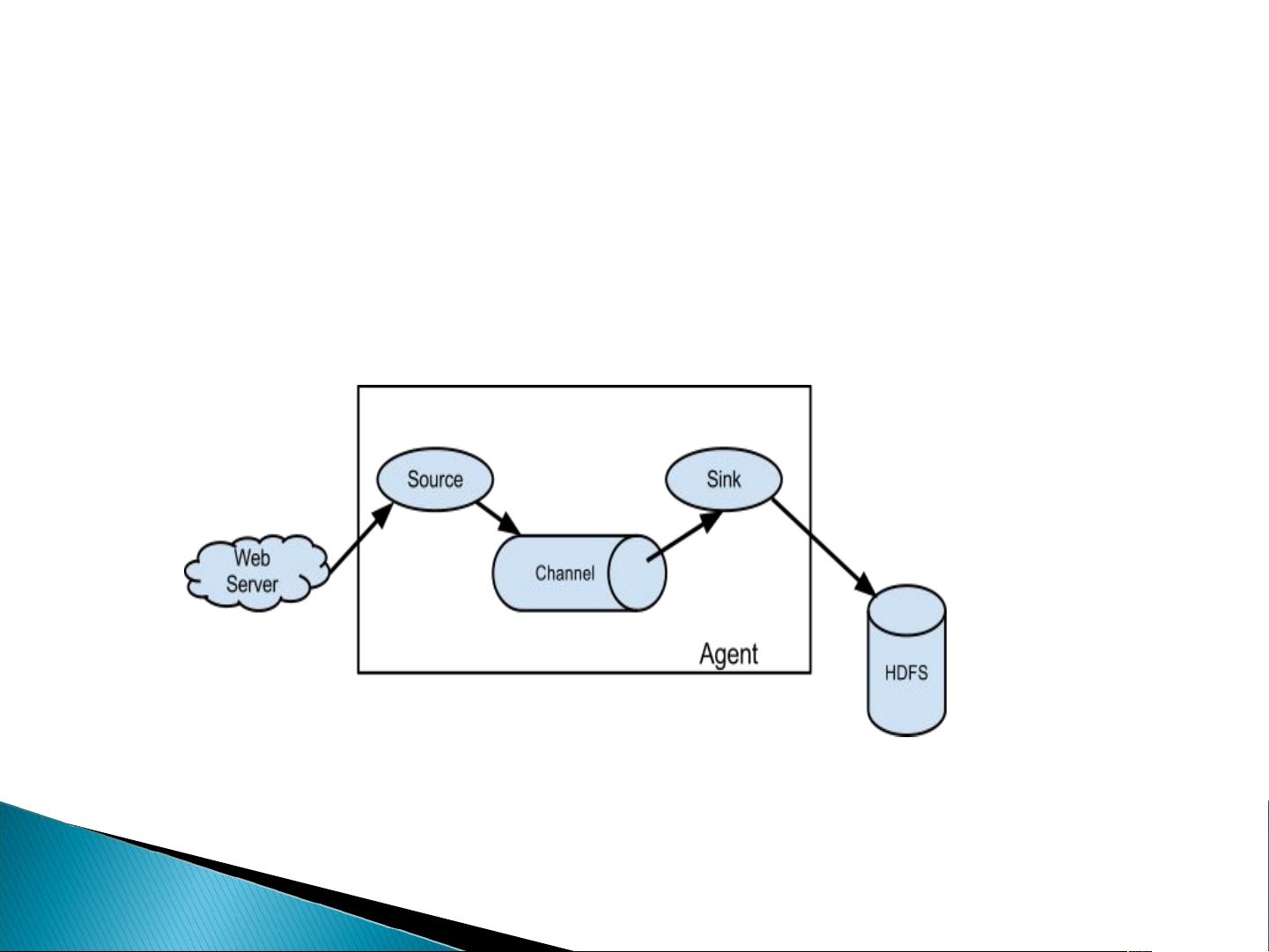
Flume 是什么
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系
统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时, Flume 提供对数据进行简
单处理,并写到各种数据接受方(可定制)的能力。当前 Flume 有两个版本 Flume 0.9X 版本的统称
Flume-og , Flume1.X 版本的统称 Flume-ng 。由于 Flume-ng 经过重大重构,与 Flume-og 有很大不同,
使用时请注意区分。