# GPT Crawler
Crawl a site to generate knowledge files to create your own custom GPT from one or multiple URLs
## Example
[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
This project crawled the docs and generated the file that I uploaded as the basis for the custom GPT.
[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
> Note that you may need a paid ChatGPT plan to access this feature
## Get started
### Prerequisites
Be sure you have Node.js >= 16 installed
### Clone the repo
```sh
git clone https://github.com/builderio/gpt-crawler
```
### Install Dependencies
```sh
npm i
```
If you do not have Playwright installed:
```sh
npx playwright install
```
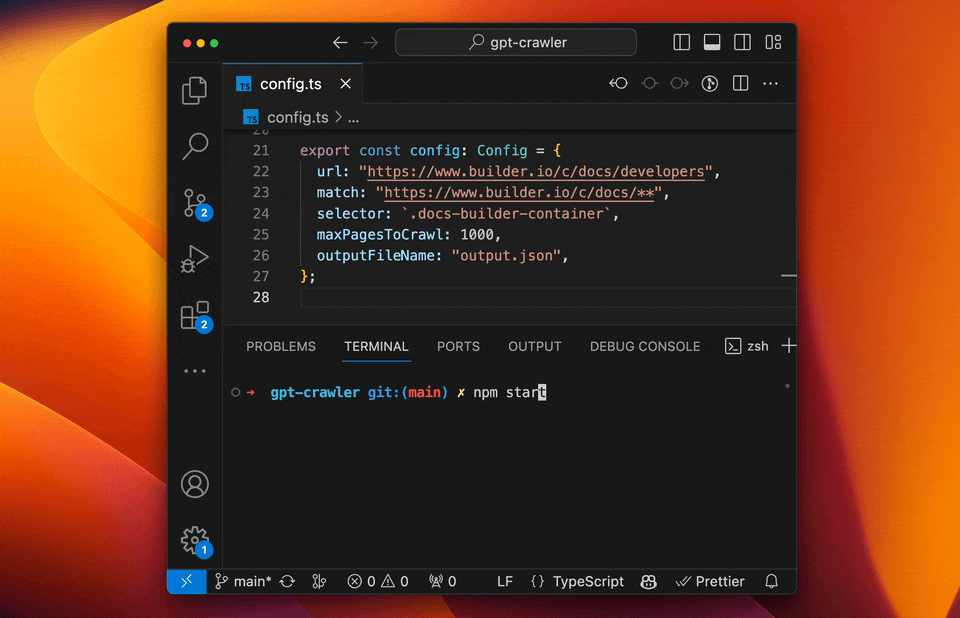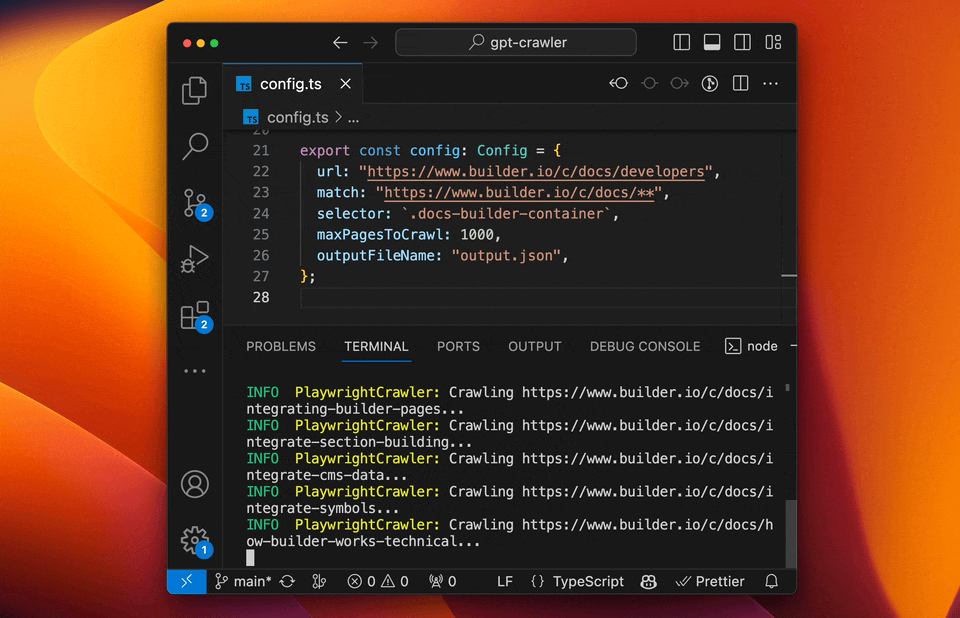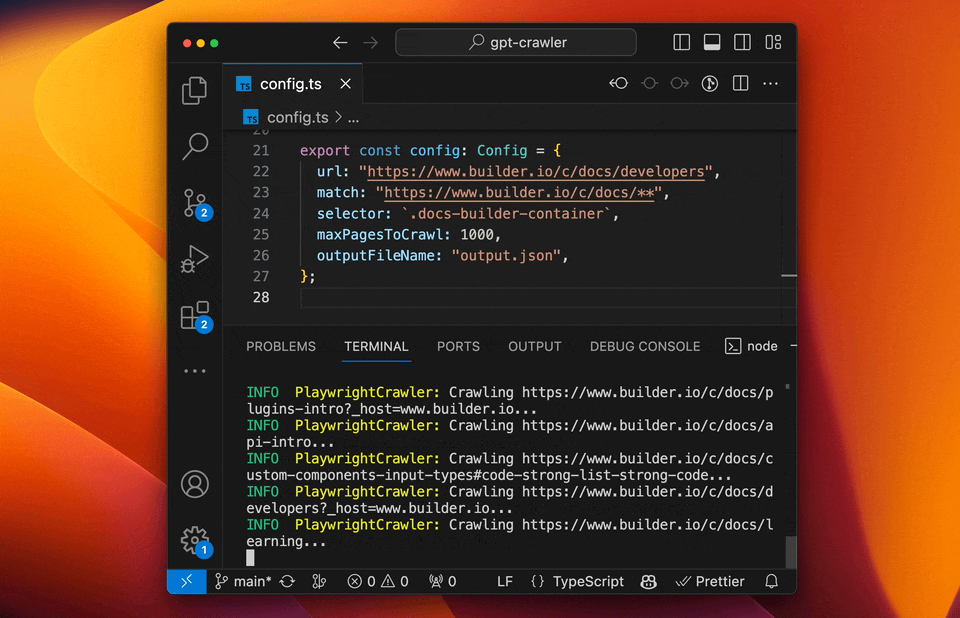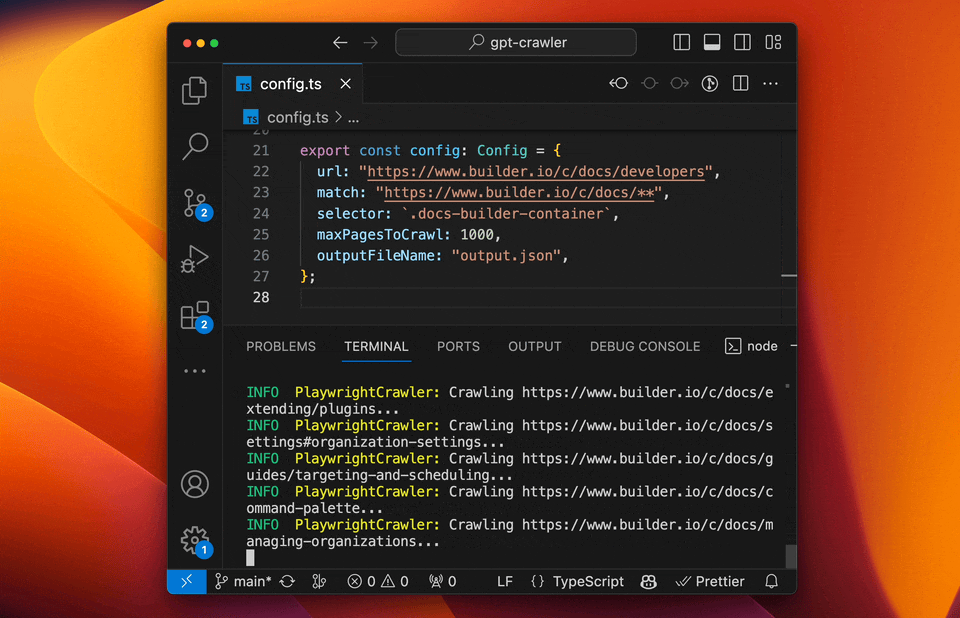
### Configure the crawler
Open [config.ts](config.ts) and edit the `url` and `selectors` properties to match your needs.
E.g. to crawl the Builder.io docs to make our custom GPT you can use:
```ts
export const config: Config = {
url: "https://www.builder.io/c/docs/developers",
match: "https://www.builder.io/c/docs/**",
selector: `.docs-builder-container`,
maxPagesToCrawl: 50,
outputFileName: "output.json",
};
```
See the top of the file for the type definition for what you can configure:
```ts
type Config = {
/** URL to start the crawl */
url: string;
/** Pattern to match against for links on a page to subsequently crawl */
match: string;
/** Selector to grab the inner text from */
selector: string;
/** Don't crawl more than this many pages */
maxPagesToCrawl: number;
/** File name for the finished data */
outputFileName: string;
/** Optional cookie to be set. E.g. for Cookie Consent */
cookie?: {name: string; value: string}
/** Optional function to run for each page found */
onVisitPage?: (options: {
page: Page;
pushData: (data: any) => Promise<void>;
}) => Promise<void>;
/** Optional timeout for waiting for a selector to appear */
waitForSelectorTimeout?: number;
};
```
### Run your crawler
```sh
npm start
```
### Upload your data to OpenAI
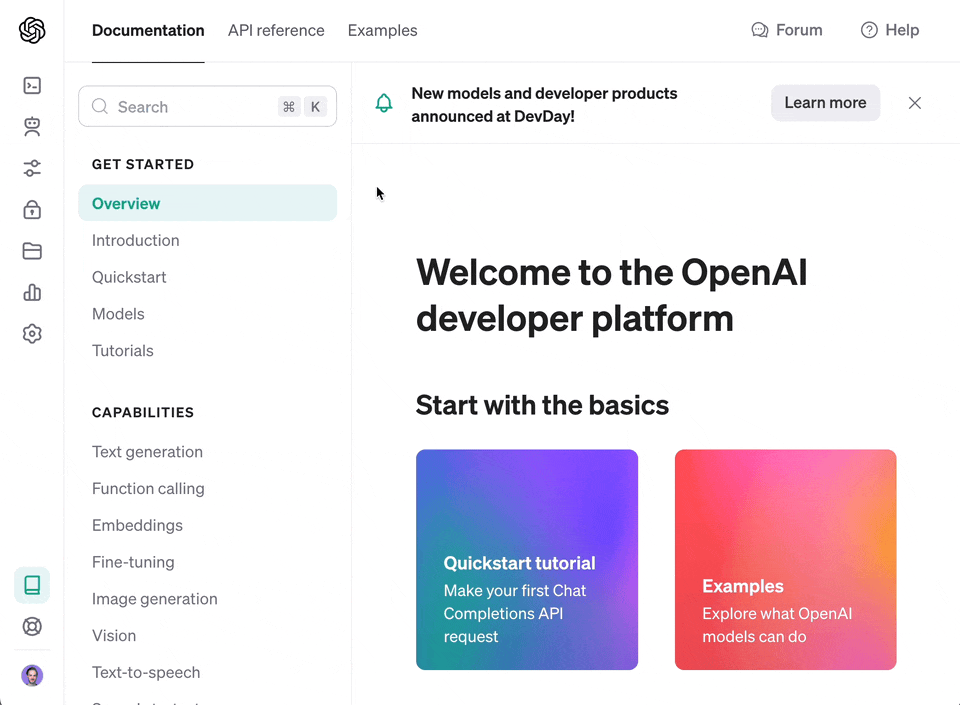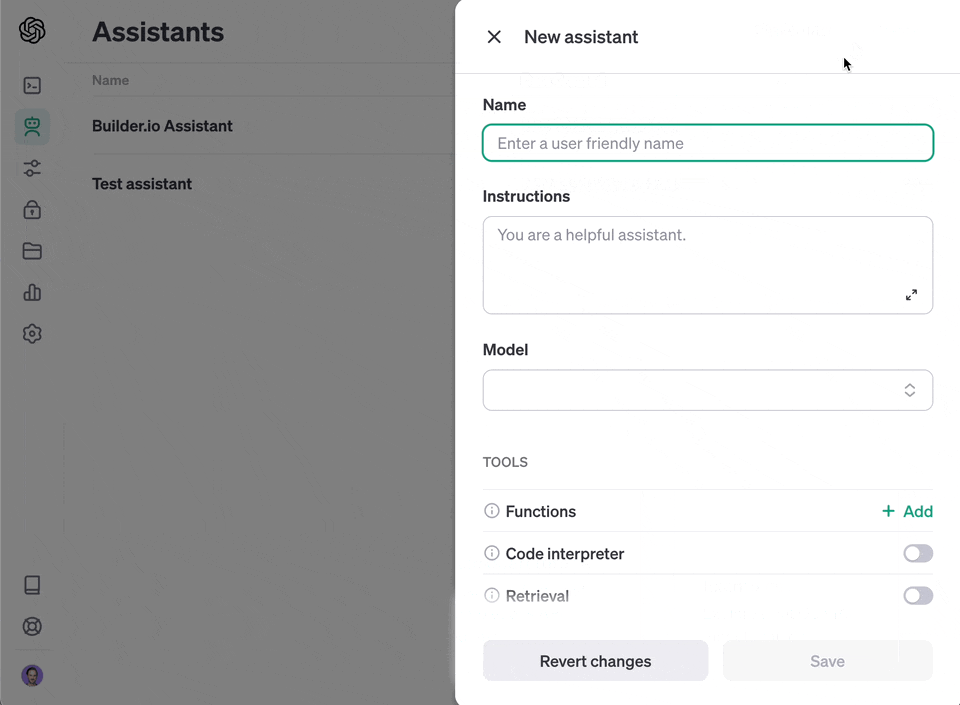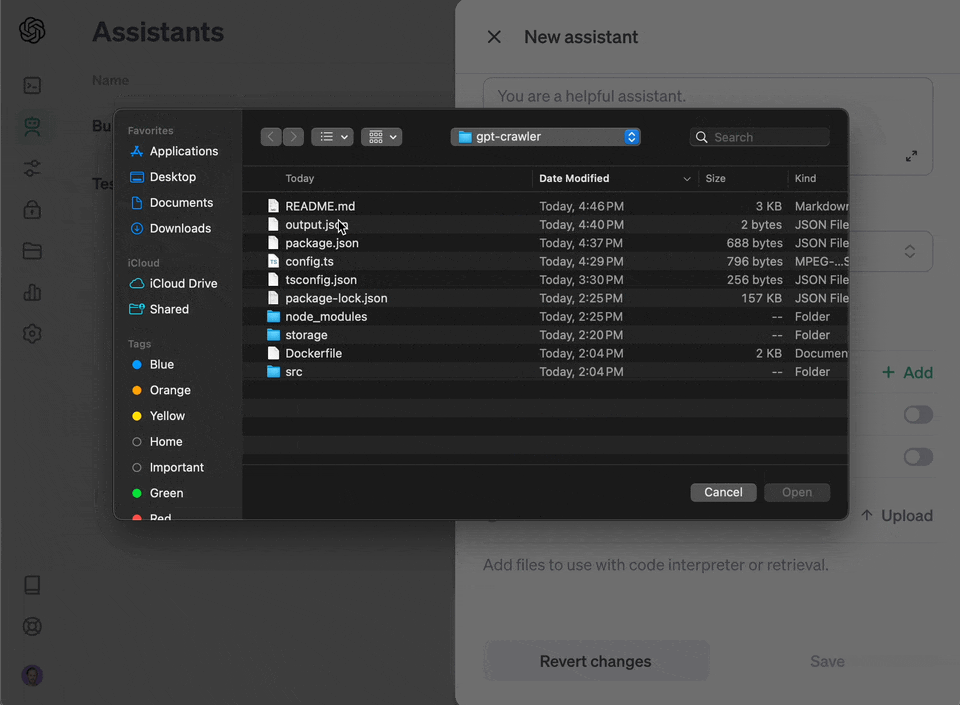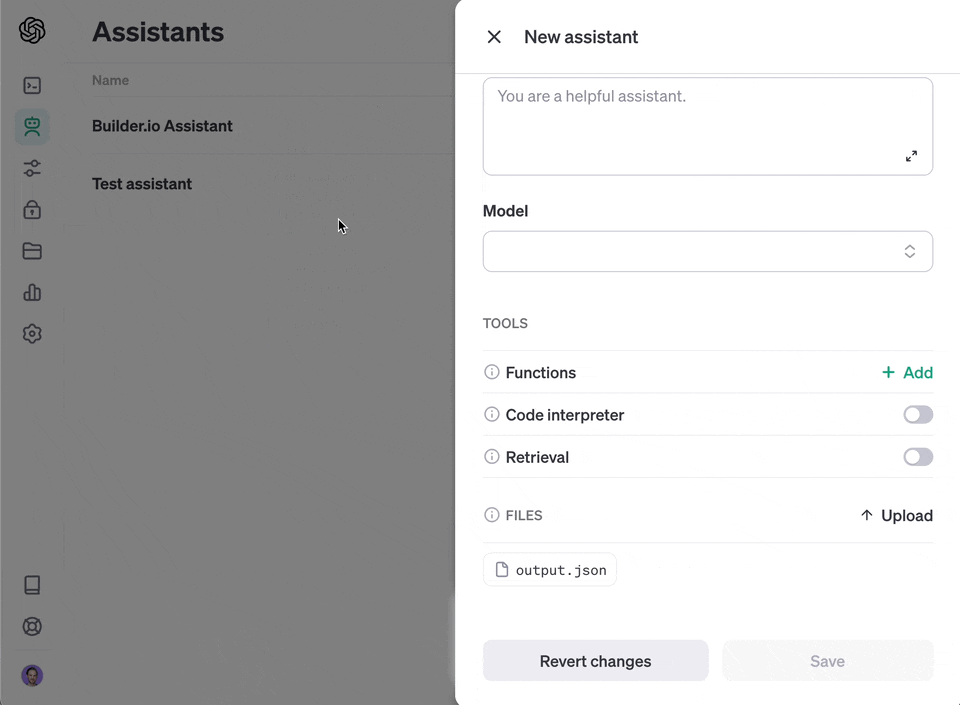
The crawl will generate a file called `output.json` at the root of this project. Upload that [to OpenAI](https://platform.openai.com/docs/assistants/overview) to create your custom assistant or custom GPT.
#### Create a custom GPT
Use this option for UI access to your generated knowledge that you can easily share with others
> Note: you may need a paid ChatGPT plan to create and use custom GPTs right now
1. Go to [https://chat.openai.com/](https://chat.openai.com/)
2. Click your name in the bottom left corner
3. Choose "My GPTs" in the menu
4. Choose "Create a GPT"
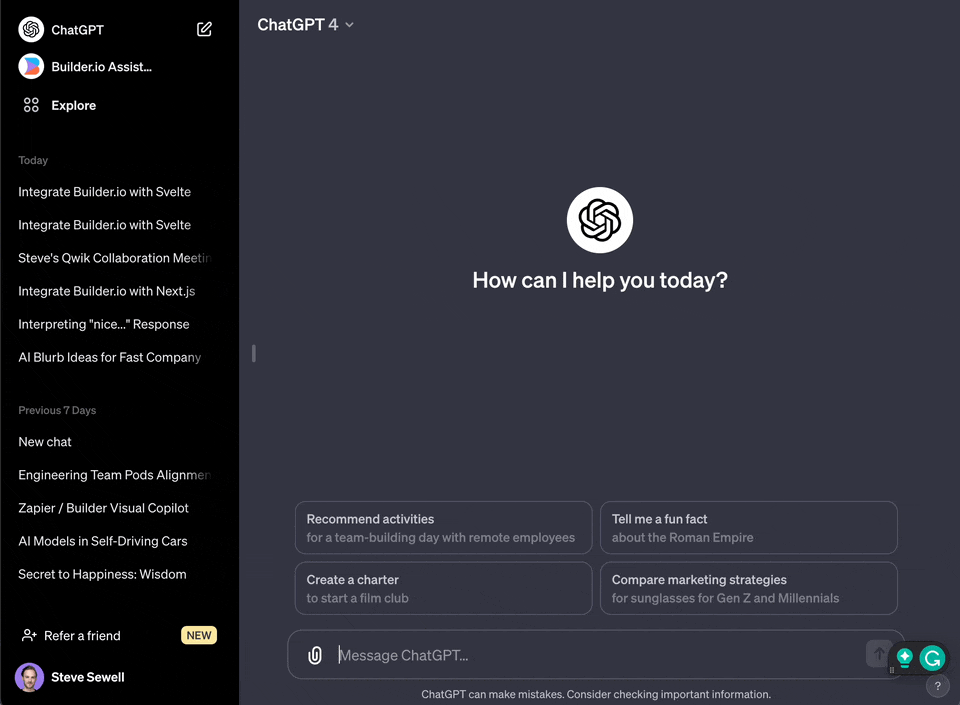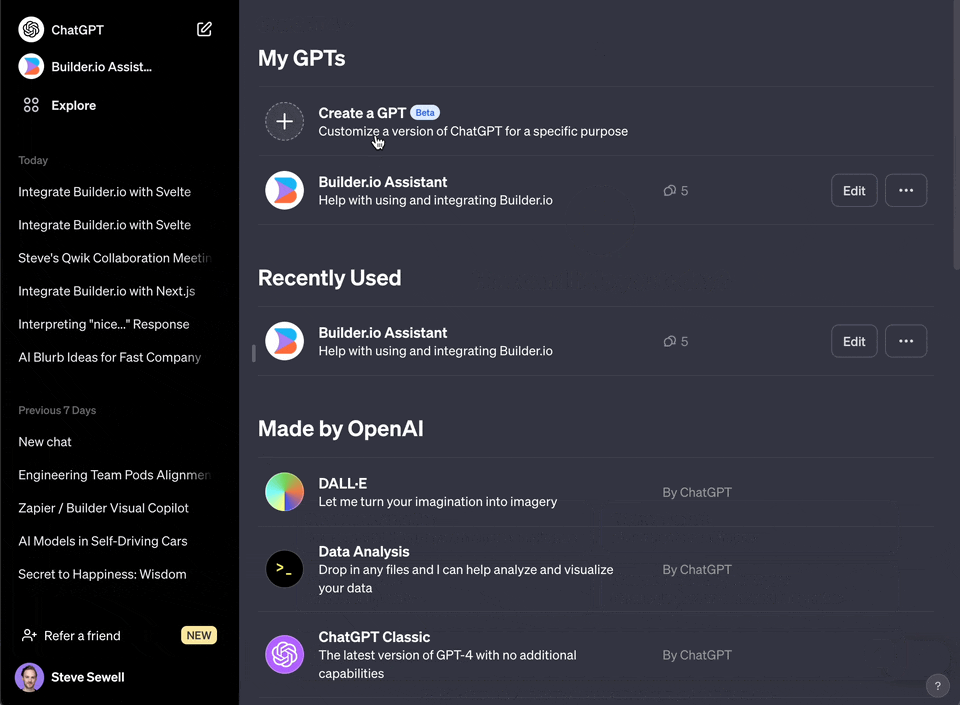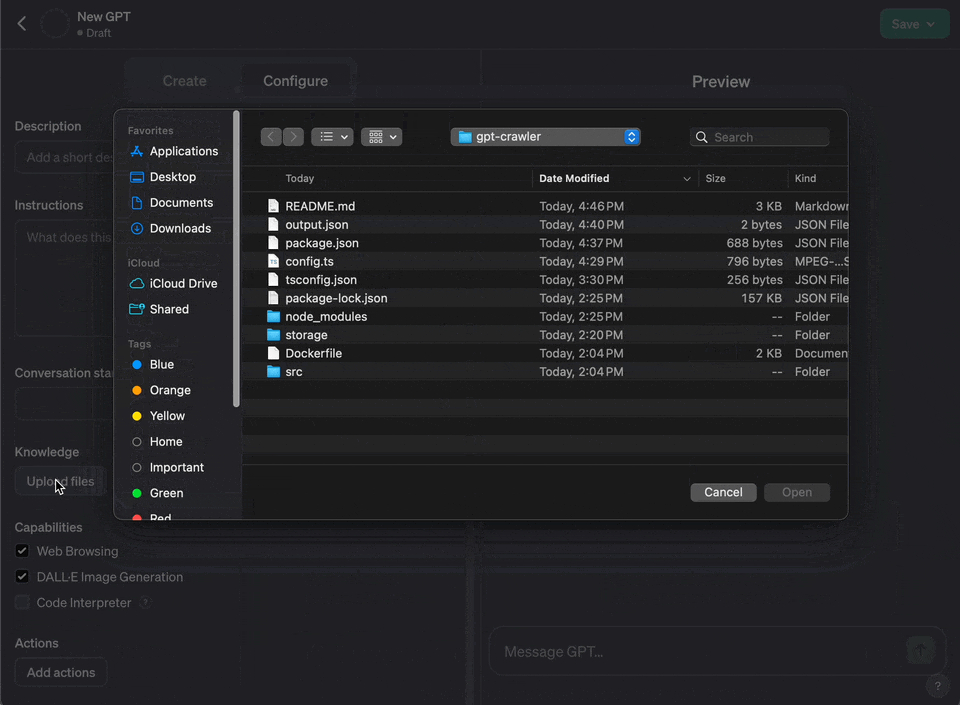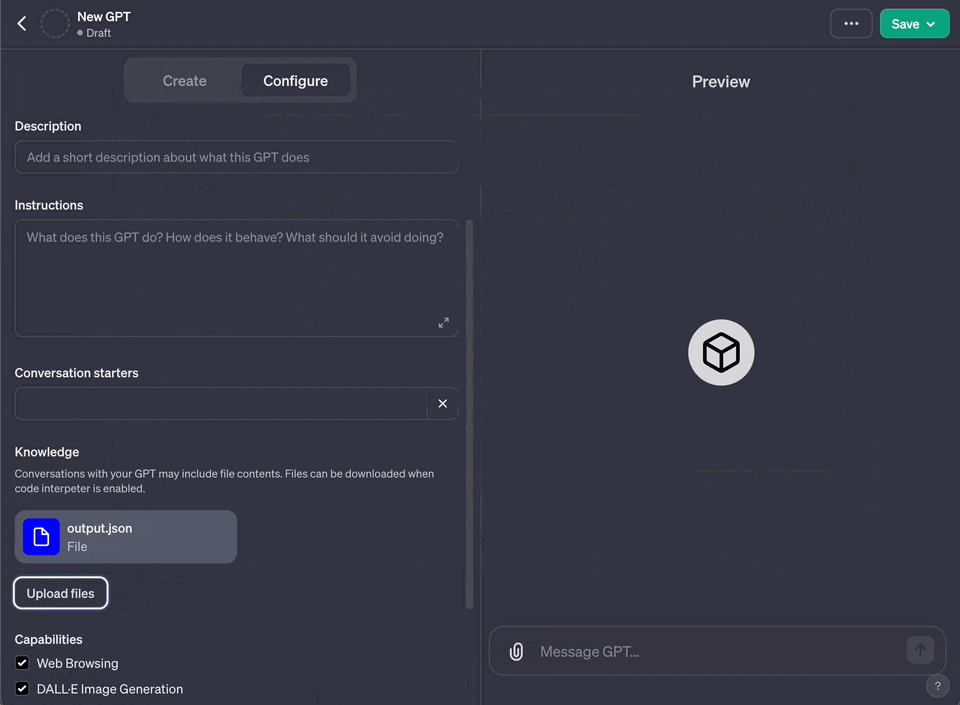
5. Choose "Configure"
6. Under "Knowledge" choose "Upload a file" and upload the file you generated
#### Create a custom assistant
Use this option for API access to your generated knowledge that you can integrate into your product.
1. Go to [https://platform.openai.com/assistants](https://platform.openai.com/assistants)
2. Click "+ Create"
3. Choose "upload" and upload the file you generated
## (Alternate method) Running in a container with Docker
To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
## Contributing
Know how to make this project better? Send a PR!
<br>
<br>
<p align="center">
<a href="https://www.builder.io/m/developers">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://user-images.githubusercontent.com/844291/230786554-eb225eeb-2f6b-4286-b8c2-535b1131744a.png">
<img width="250" alt="Made with love by Builder.io" src="https://user-images.githubusercontent.com/844291/230786555-a58479e4-75f3-4222-a6eb-74c5af953eac.png">
</picture>
</a>
</p>
GPT Crawler,借助自动化爬虫,快速自定制 GPT ChatGPT的普通用户,训练个人专属的智能知识库

需积分: 0 108 浏览量
2023-11-21
08:07:56
上传
评论
收藏 46KB ZIP 举报
 gpt-crawler-main.zip (16个子文件)
gpt-crawler-main.zip (16个子文件)  gpt-crawler-main
gpt-crawler-main  .DS_Store 6KB src main.ts 2KB LICENSE 1KB config.ts 995B package.json 688B Dockerfile 2KB package-lock.json 131KB .gitignore 134B tsconfig.json 256B containerapp data config.ts 1003B init.sh 229B Dockerfile 1KB run.sh 665B README.md 330B .dockerignore 130B README.md 4KB
.DS_Store 6KB src main.ts 2KB LICENSE 1KB config.ts 995B package.json 688B Dockerfile 2KB package-lock.json 131KB .gitignore 134B tsconfig.json 256B containerapp data config.ts 1003B init.sh 229B Dockerfile 1KB run.sh 665B README.md 330B .dockerignore 130B README.md 4KB资源评论













