影响一个词#在一篇文档中的重要性主要有两个因素:
#&34(5&*0:即此 # 在此文档中出现了多少次。*0&越大说明越重要。
/(*&34(5& 0:即有多少文档包含次 #。 0&越大说明越不重要。
词#在文档中出现的次数越多,说明此词#对该文档越重要,如“搜索”
这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而
在一篇英语文档中,*) 出现的次数更多,就说明越重要吗?不是的,这是由第二
个因素进行调整,第二个因素说明,有越多的文档包含此词#9&说明此词
#太普通,不足以区分这些文档,因而重要性越低
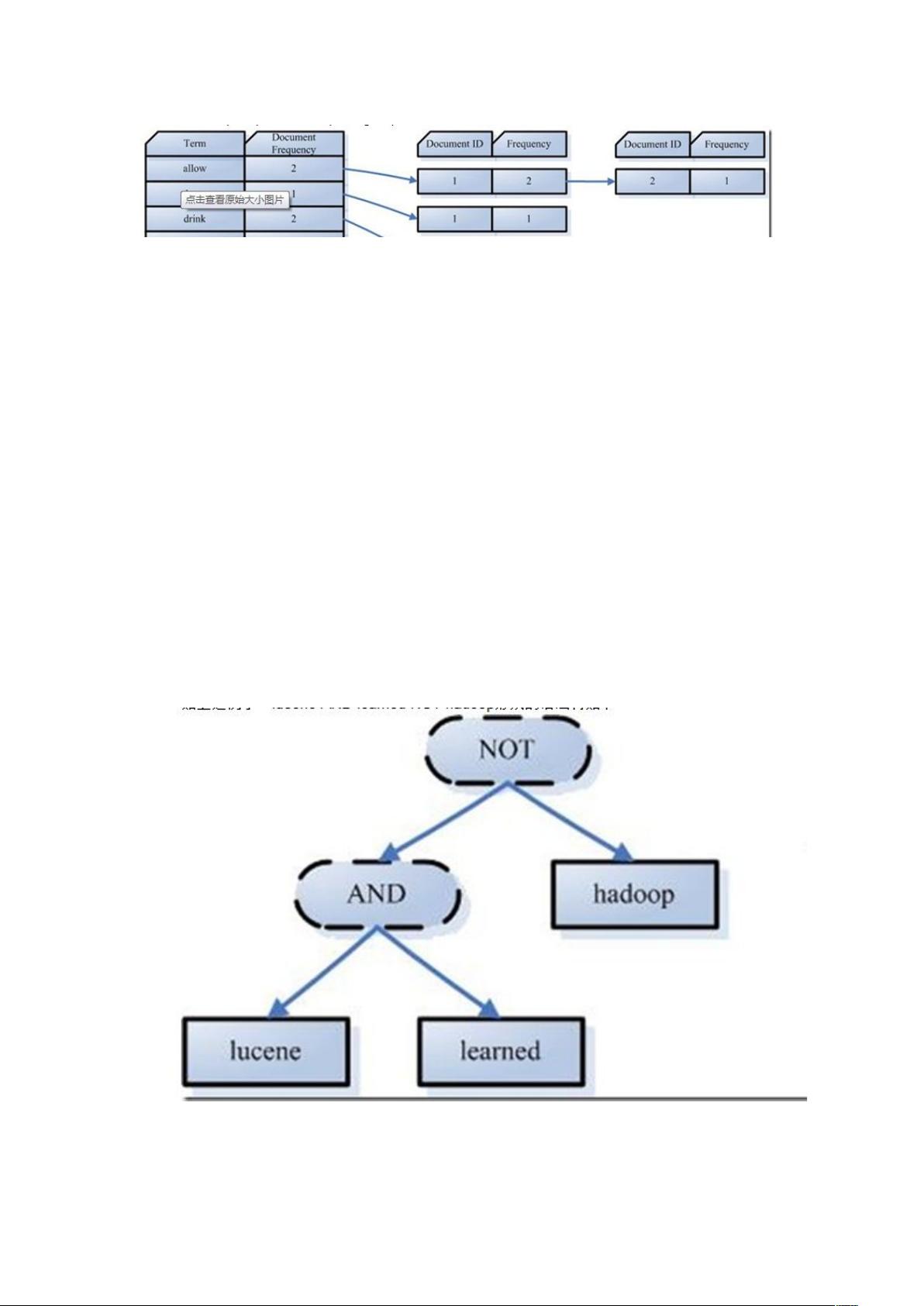
&判断 # 之间的关系从而得到文档相关性的过程,也即向量空间模型的算法
:;<。
我们把文档看作一系列词#,每一个词#都有一个权重#&*,不同
的词#根据自己在文档中的权重来影响文档相关性的打分计算。
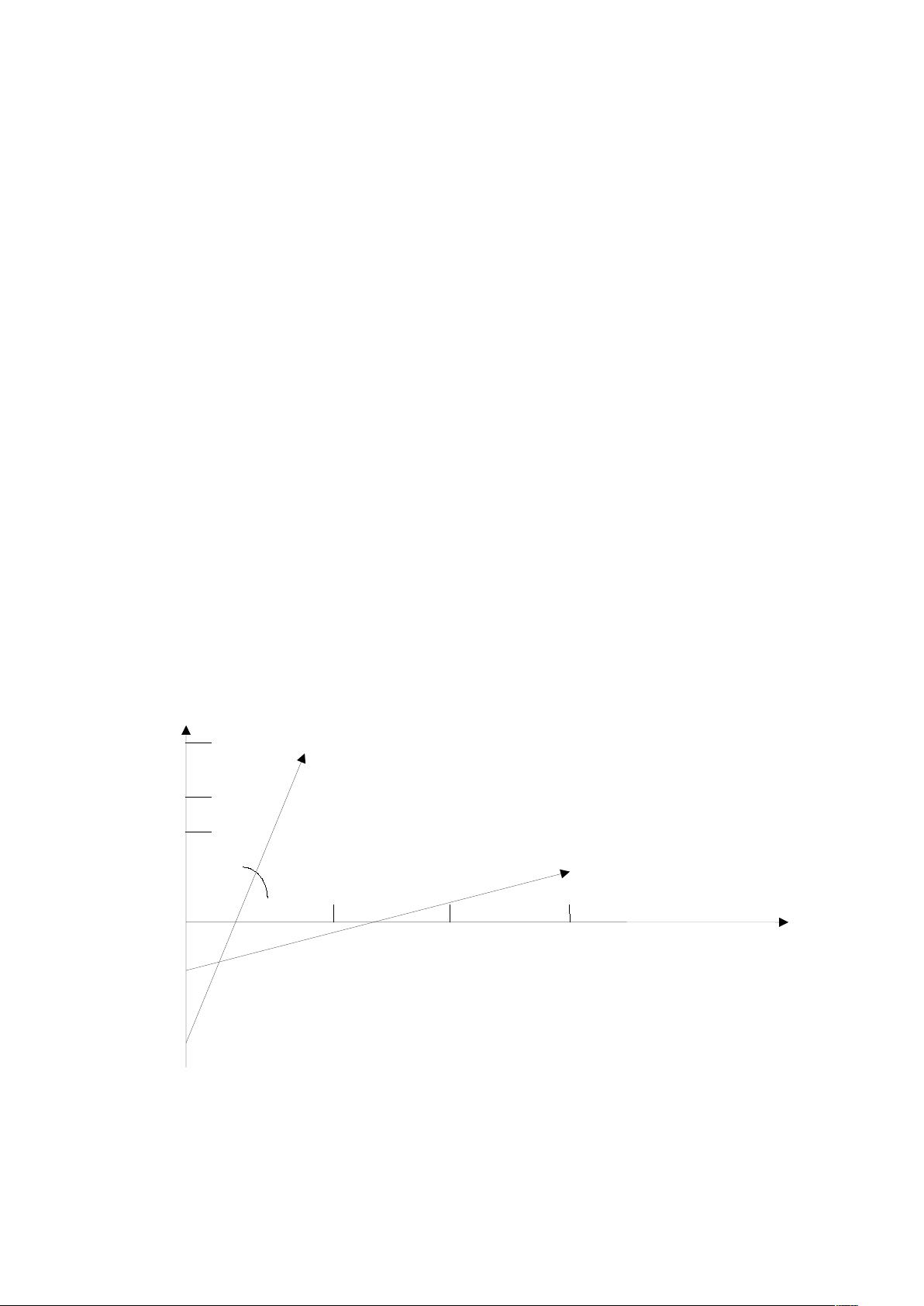
于是我们把所有此文档中词*的权重*&*&看作一个向量。
/(*&=&>*9&*9&??&9*&7@
/(*&:*&=&>*9&*9&??&9*&7@
同样我们把查询语句看作一个简单的文档,也用向量来表示。
(5&=&>*9&*&9&??&9&*&7@
(5&:*&=&>*9&*9&??&9&*&7@
总结:索引过程:
1) 有一系列被索引文件
2) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
3) 经过索引创建形成词典和反向索引表。
4) 通过索引存储将索引写入硬盘。