Oracle数据迁移方案!!!.docx
版权申诉
147 浏览量
2023-09-08
19:20:36
上传
评论
收藏 1.09MB DOCX 举报


数据迁移通俗的说就是将数据从一个地方转移到另一个地方。主要使用场景有:根据正式系统搭建测试环境、从内网复制到外网、数据库服务器硬件升级等。
根据需要迁移的数据量大小、系统架构,可采取不同的迁移方法。
注:以下所说方法,不考虑数据的增量更新、不考虑数据的实时同步、不考虑数据的逻辑转换。如果有这些需求,建议使用第三方 ETL 工具或使用 Oracle 的其
他数据同步技术。
一、常用示例
1.1 如何在客户现场搭建测试环境?
常规方案,使用 imp/exp 工具,先在源库执行直接路径导出操作,然后在目标库执行导入操作。IMP/EXP 的执行速度主要受限于磁盘及网络。
数据量:1.5G
导出用时:5 分钟
导入用时:23 分钟
导出文件大小:641M
导出导入环境:单 CPU,700M 内存。为力求最大速度,使用直接路径导出、设置最大 I/O 缓冲、导入导出文件都放在服务器上执行。
1.2 还有没有更快的办法?
有,仍然使用 impdp/expdp。只是不再将数据导出后导入,而是直接将数据从源库导入到目的库。
CMD> Impdp testi@目标库 directory=DMPDIR schemas=TESTI
network_link=源库 dblink remap_schema=TESTI:TESTA
上面语句的操作是将源库的 TESTI 用户的数据,导入到目标库的 TESTA 用户下。
这个操作是局域网内迁移数据最方便的工具,不过也可能是速度最慢的工具。
1.3 有没有还快一点的方法?
有,换用 impdp/expdp。同样在源库执行导出,在目标库执行导入。操作速度能得到极大提升。IMPDP/EXPDP 速度主要受限于磁盘,与网络无关。
原数据大小:1.5G
expdp 导出操作用时:5 分钟
impdp 导入操作用时:22 分钟
导出文件大小:588M
导出导入环境:单 CPU,700M 内存,并行度 = 1
??你不是说这个会更快么?为什么速度跟 1.1 的 imp/exp 差不多啊?
请看第四部分总结的解释。
1.4 你还敢再快一点么?
使用表空间迁移。将表空间的元数据导出,和数据文件一起,复制到新库。执行元数据导入。一般来说,整个导入导出的数据量不到 5M。速度相当快,但使用
限制比较多。
导出时间:1 分钟
导入时间:3 分钟
导出文件:60M + 数据文件 1.5G
1.5 如何将数据从 linux 环境转到 windows 环境?
查看 v$transportable_platform,如果数据编码一致,可尝试直接复制数据文件。否则使用 rman 或 impdp/expdp 或 imp/exp。
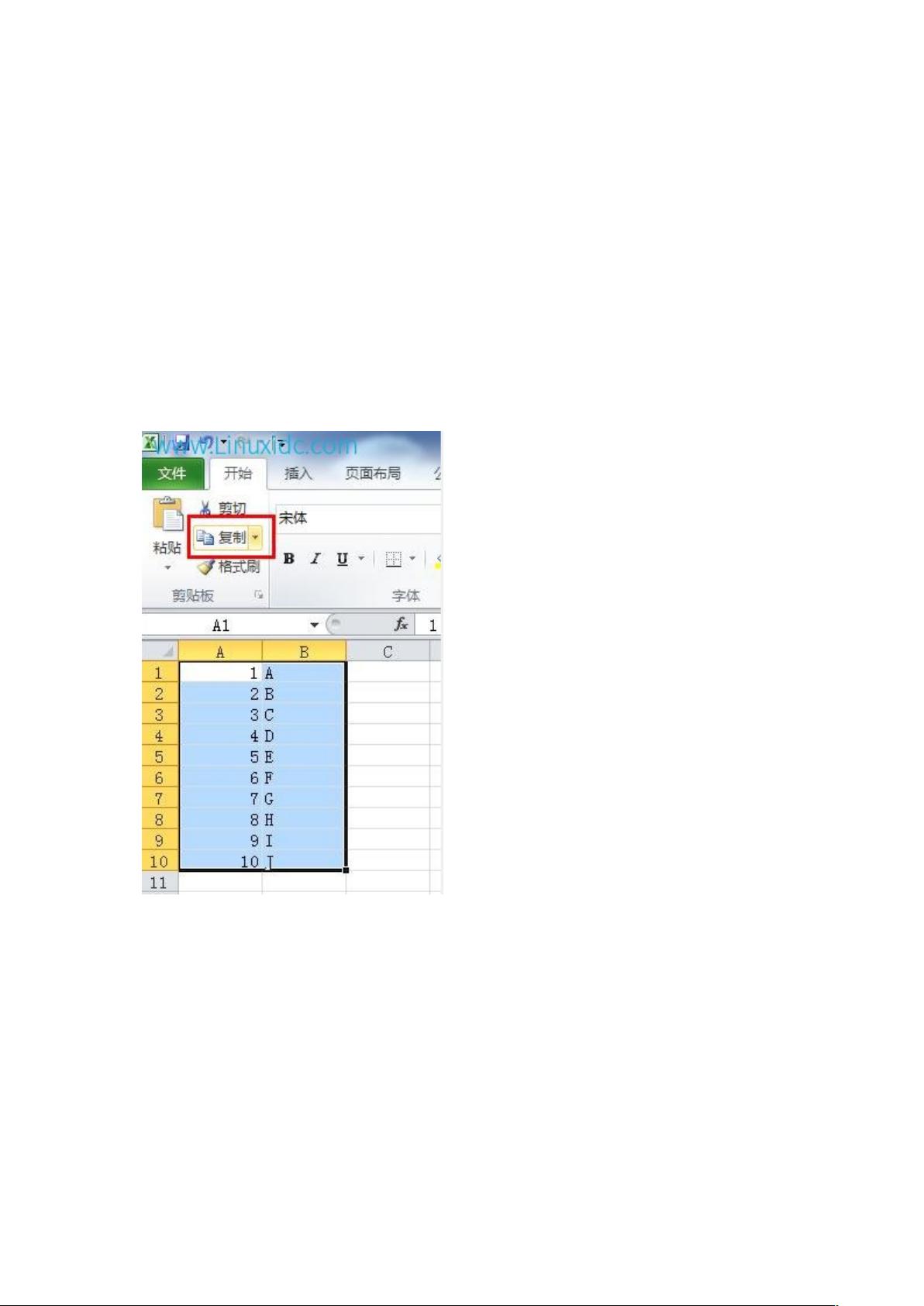
1.6 如果你有一个 excel 格式的数据表,需要远程更新到客户数据库上,怎么更新?
使用 pl/sql developer,复制、粘贴、提交。
剩余10页未读,继续阅读
资源评论













