

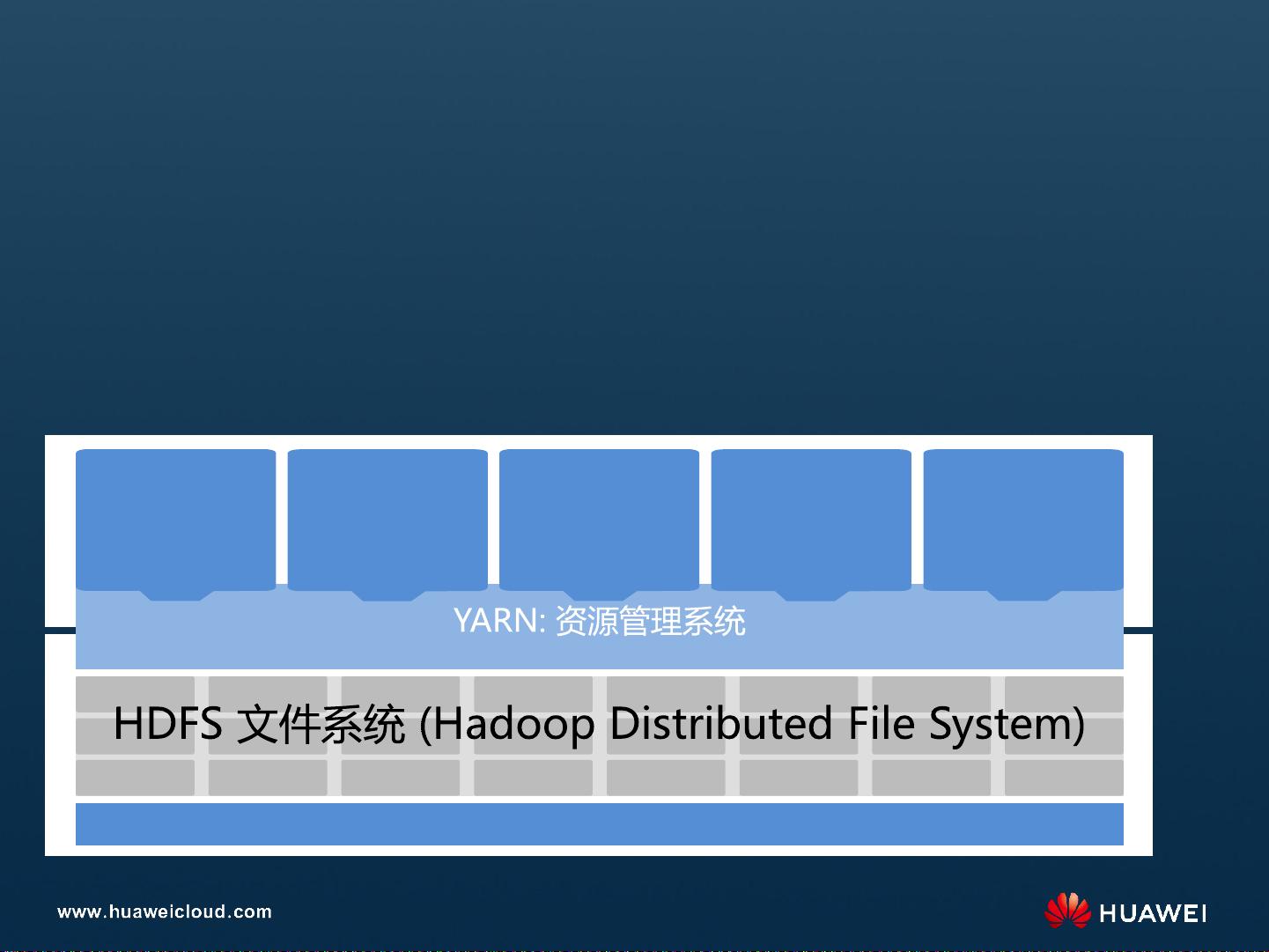
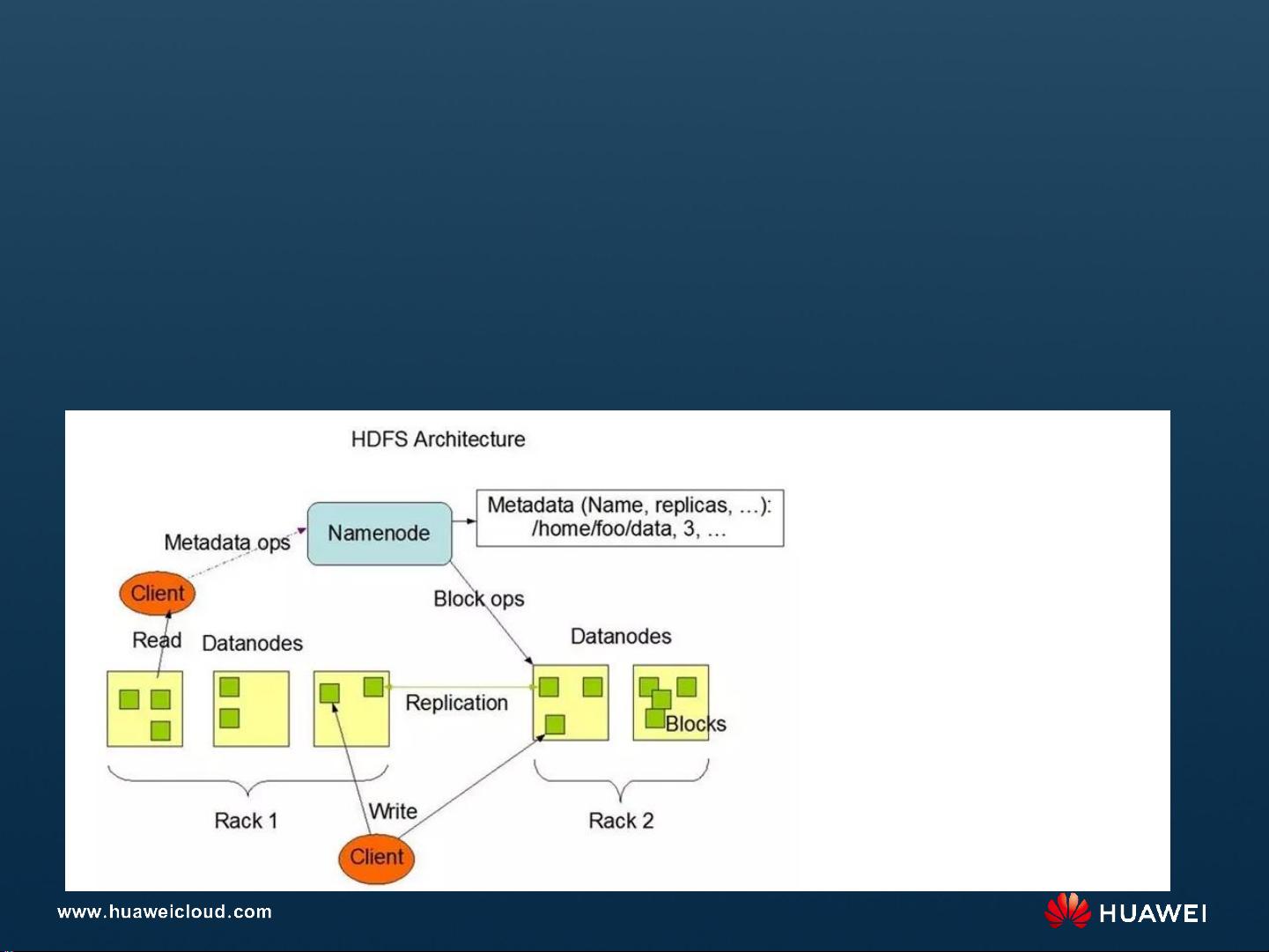
Day1-2 MapReduce服务
课程资料
详细视频讲解网址
https://education.huaweicloud.com:8443/courses/course-
v1:HuaweiX+CBUCNXE006+Self-paced/about?isAuth=0&cfrom=hwc


剩余26页未读,继续阅读
资源评论


caoxiaoping
- 粉丝: 1
- 资源: 5









最新资源
- 带载流子密度的双温模型matlab,电子晶格温度,电子密度,飞秒激光源模拟,有限元法解偏微分方程 德鲁德模型,带载流子密度变化
- GP026-仓库系统.zip
- HttpCanary_3.3.6.apk
- 线控制动系统仿真 Carsim和Simulink联合仿真线控制动系统BBW-EMB系统 包含简单的制动力分配和四个车轮的线控制动机构 四个车轮独立BLDCM三环PID闭环制动控制,最大真实还原线
- Comsol脉冲涡流无损检测仿真 图一:脉冲涡流仿真,检出电压信号 图二:脉冲涡流模型 图三:磁通密度模 图四:磁通密度模
- CC2530无线zigbee裸机代码实现光敏和热敏传感器数值读取.zip
- CC2530无线zigbee裸机代码实现继电器的控制.zip
- CC2530无线zigbee裸机代码实现看门口狗Watch Dog使用.zip
- CC2530无线zigbee裸机代码实现控制步进电机正反转.zip
- CC2530无线zigbee裸机代码实现人体红外传感器数值读取.zip
- CC2530无线zigbee裸机代码实现睡眠定时器唤醒系统.zip
- CC2530无线zigbee裸机代码实现外部中断控制LED开关.zip
- CC2530无线zigbee裸机代码实现外部中断控制流水灯.zip
- 基于51单片机的污水处理厂气体检测报警系统(protues仿真)-毕业设计
- CC2530无线zigbee裸机代码实现温度传感器DS18B20数值读取.zip
- CC2530无线zigbee裸机代码实现温湿度传感器DHT11数值读取.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


