

GPU编程高级优化技术杂谈
前言
数年前,我初入编程领域,一开始根据兴趣GPGPU这个方向,
那是CUDA和OpenCL还未出现,那是底层汇编找色器的时代,而我当时正是通过OpenGL使用GPU汇编指令
,Cg以及GLSL编写着色器来进行GPU通用计算,直至现在一直从事基于GPU和CPU高性能异构计算的工作。
数年前以网名cyrosly经常混迹于CSDN
CUDA论坛和CUDA计算QQ群,讨论各种相关技术或是对一些网友的问题答疑解惑。现在想来那段时期,
有过狂妄,有过激情,更结识了友情。是我的好友郑经维正是在学习CUDA技术的过程中结识的,当
时虽只一面之缘,却成为了这个圈子中最要好的朋友,也正是因为他的劝说才有了我写此书的决定,
或许一本对上感觉的书对于读者的意义远大于在论坛上回答成千上百个问题。本来经纬是想让我尽
可能出版的,但是由于工作的原因,没有多余的精力继续写下去,因此打算把还远未未完成的残稿
贡献出来。
本书的目的跳过众多相关书籍频繁重复的内容通过几个有趣的实例直接介绍GPU编程中的高级
优化技术,读者可从本书中一窥诸如cublas,cufft那些高性能库的大概面貌和其中所使用的主要优化技
术。当然,即使是初学者,也可以通过本书达到技术上跳跃式的升级,而作者也信奉一个观念:一看就
懂的书不是好书,因为这代表了读者最终可以从中获取的信息量太少抑或是自己潜意识里早已知晓
但并未显现,并可能引发部分读者的思考:是否物有所值。本书内容绝不雷同,力求精简,节奏很
快,希望读者可以通过分析本书中的代码找到开发高质量GPU程序的感觉。作者本人没有写书的经验
,,甚至自认不太擅长摆弄文字,所以本书未必是一本好书,但绝对有其独特之处,如果读者可从
中或多或少的学到些其它相关书籍中没有见过的内容,那么也不枉此书了。写作过程历时约一个半
月,由于写作仓促,因此不免有疏漏之处,若有发现,可联系作者更正。
作者的联系方式:
QQ : 295553381
微信 : 13710058492
目录
第一章 设备微架构
1.0 CUDA设备
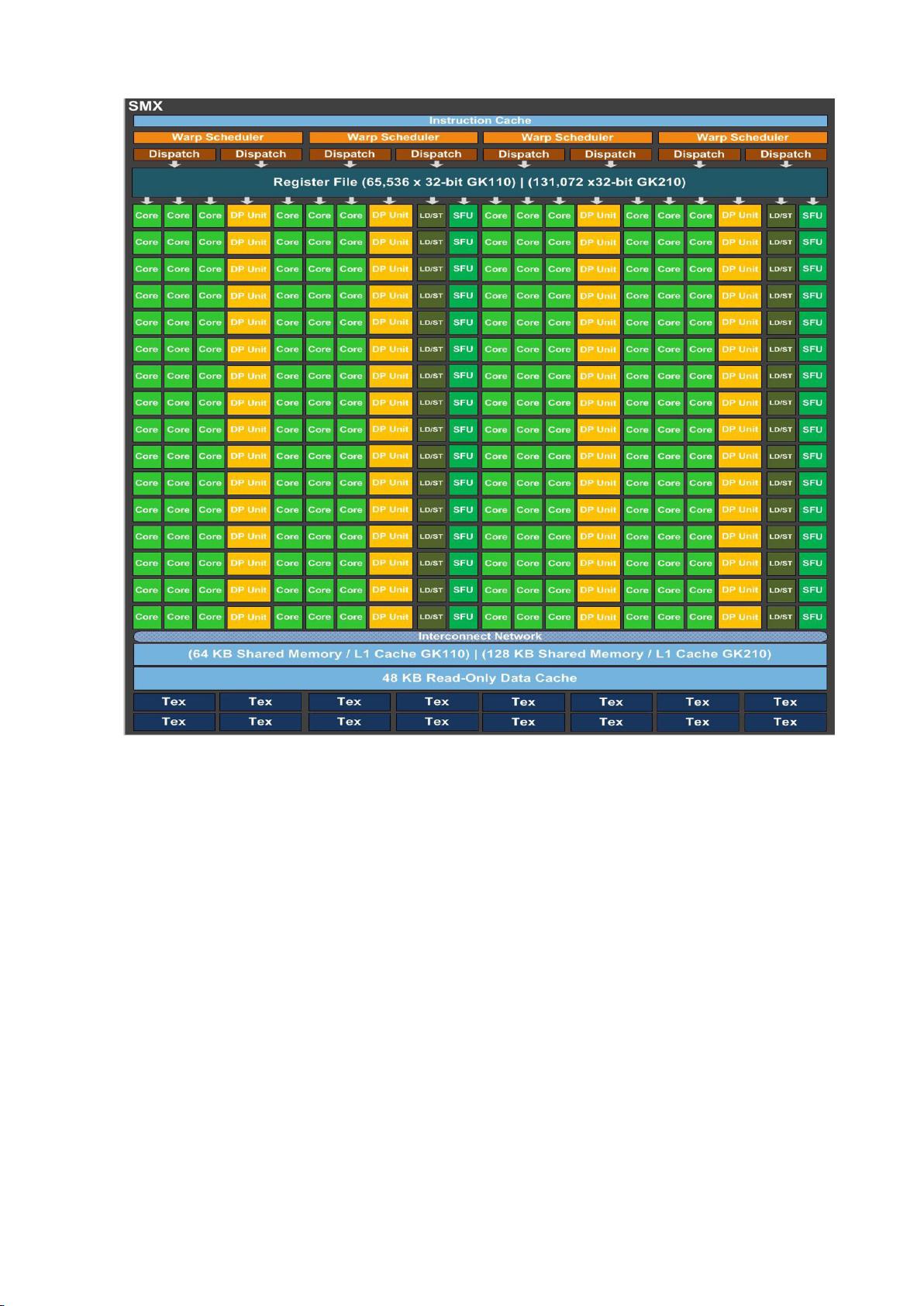
1.0.0 核心微架构
1.0.1 寄存器文件结构



剩余52页未读,继续阅读
资源评论

 AwAyfromAwAy2018-02-27好资源,非常赞
AwAyfromAwAy2018-02-27好资源,非常赞
Bruce_0712
- 粉丝: 287
- 资源: 1









最新资源
- 该仿真主要应用于路径规划和轨迹跟踪的研究 主要有五个文件(内部包含3个算法,两个仿真),1.A星算法自动生成避障的最短路径,2.两轮小车及其四轮小车的运动学建模3.纯路径跟踪算法,包括预锚点的选择算
- Edifier Connect_8.4.11.apk
- anaconda配置pytorch环境.md
- 机械设计自动倒角机sw18可编辑非常好的设计图纸100%好用.zip
- 基于28027滑膜算法的水泵驱动方案,带有初始定位算法,启动不反转,pfc采用硬件方案
- 机械设计自动PCM板胶纸机sw18非常好的设计图纸100%好用.zip
- 三相PWM整流器闭环仿真,电压电流双闭环控制,输出直流电压做外环 模型中包含主电路,坐标变,电压电流双环PI控制器,SVPWM控制,PWM发生器 matlab simulink模型 功率因数1,低TH
- anaconda配置pytorch环境.md
- Cytoscape-3-10-3-windows-64bit-仅限个人学习
- DDR3测试模块 fpga测试接口模块,提供测试模块工程 Vivado2019.1或者Vivado2017.4;语言vhdl 可以修改ip引脚,测试初始化完成
- 网络工程领域竞赛试题:网络搭建与应用的技术实战项目
- 山东大学软件学院人工智能导论22级复习资料
- 机械设计自动切断面条机ZD80sw16非常好的设计图纸100%好用.zip
- 毕设基于stm32的风机监控系统程序设计源码.zip
- 机械设计自动贴E型定位胶纸机sw18非常好的设计图纸100%好用.zip
- 机械设计自动贴E型胶纸机sw18非常好的设计图纸100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


