
大数据仓库架构设计实践案例共享
命名的规范次要分为表命名的规范和字段命名的规范。
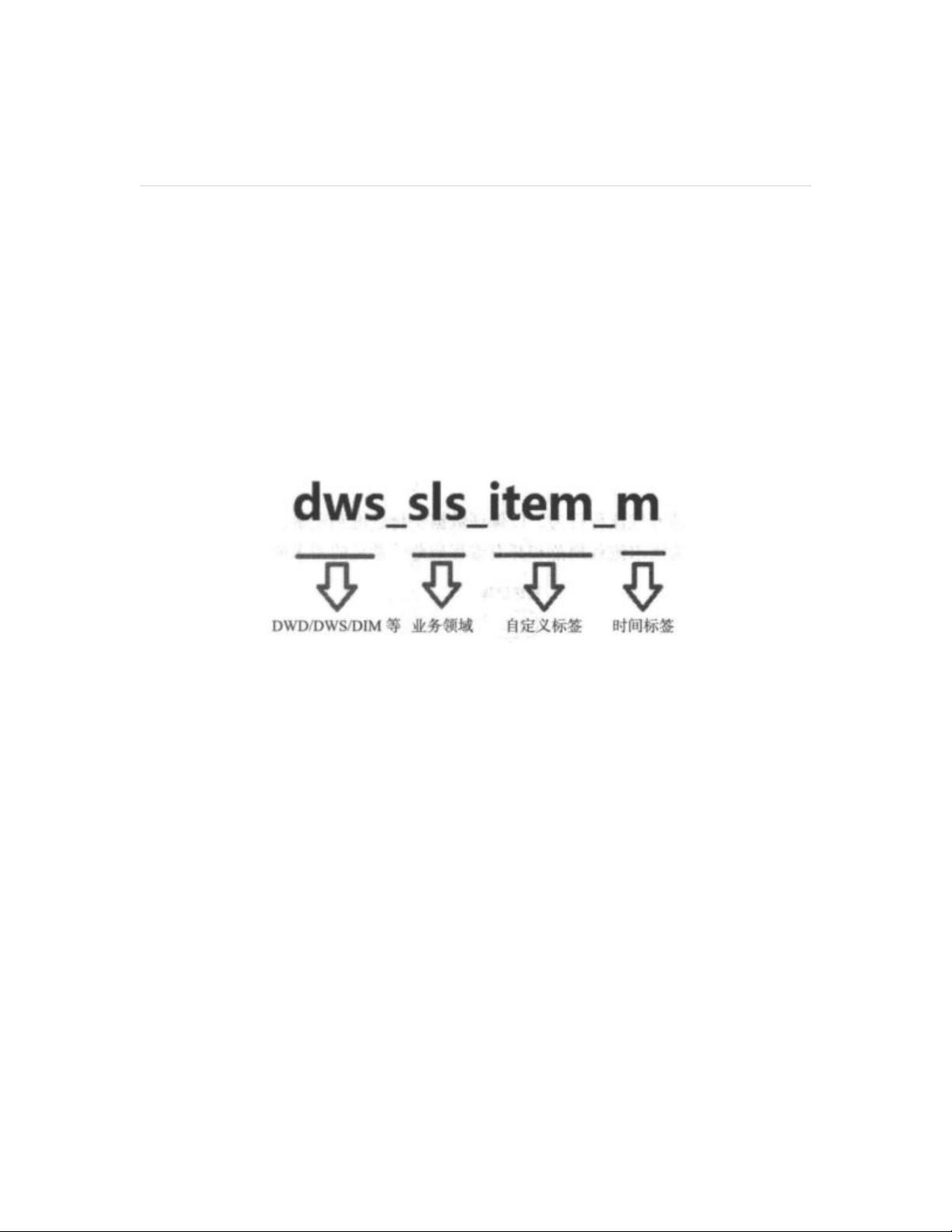
其中表命名的规范是为了让数据全部相关方对表包含的信息有一个共同的认知,
比如属于哪一层(ODS、DWD、DWS、ADS)?哪个业务领域(销售、库
存、促销)等?哪个维度(商品、买家、卖家、类目等)?哪个时间跨度(天、
月、年、实时)?增量还是全量?
基于此,数据平台建设者应当首先规定数据仓库分层、业务领域、常见维度和时
间跨度等的英文缩写,并据此给出表的命名规范。
开发规范
开发规范次要用于规范和约束数据开发人员和使用人员的习惯,以最大限度地降
低数据的使用风险,并同时保证用户恪守最佳实践 到底数据代码并不只是给本
人看的,很多时候也需要供他人阅读和参考, 尤其是处理问题的时候。
开发规范次要包含以下几个方面。
主数据任务的分类和存放(即名目结构的划分) :公共代码如何存放,个人
代码如何存放,项目和产品的代码如何分类存放,实际项目中需要对此进行
统筹规划并保证每个人都恪守,以使得用户很简约找到对应项目、产品或者
各个层次的代码( ODS 、DWD、DWS、ADS)。
代码的编程规范 :比如任务注释的规范必需包含哪些部分 代码的对齐规范、
代码的开发商定等。
资源评论


bingbingbingduan
- 粉丝: 0
- 资源: 7万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP











