

Ceph
源码解析: CRUSH
算法
1、简介
随着大规模分布式存储系统 级的数据和成百上千台存储设备的出现。这些系统必
须平衡的分布数据和负载提高资源利用率,最大化系统的性能,并要处理系统的扩展和
硬件失效。 设计了 一个可扩展的伪随机数据分布算法,用在分布式对象存
储系统上,可以有效映射数据对象到存储设备上不需要中心设备。因为大型系统的结构
式动态变化的, 能够处理存储设备的添加和移除,并最小化由于存储设备的的添
加和移动而导致的数据迁移。
为了保证负载均衡,保证新旧数据混合在一起。但是简单 分布不能有效处理设
备数量的变化,导致大量数据迁移。 开发了 (
),一种伪随机数据分布算法,它能够在层级结构的存储集群
中有效的分布对象的副本。 实现了一种伪随机确定性的函数,它的参数是
或 ,并返回一组存储设备用于保存 副本
。 需要 描述存储集群的层级结构、和副本分布策略。
有两个关键优点:
o 任何组件都可以独立计算出每个 所在的位置去中心化。
o 只需要很少的元数据 ,只要当删除添加设备时,这些元数据才需
要改变。
的目的是利用可用资源优化分配数据!当存储设备添加或删除时高效地重组数
据!以及灵活地约束对象副本放置!当数据同步或者相关硬件故障的时候最大化保证数据安
全。支持各种各样的数据安全机制!包括多方复制镜像!" 奇偶校验方案或者其他形式
的校验码!以及混合方法比如 "#$%。这些特性使得 适合管理对象分布非常大
的 级别、要求可伸缩性!性能和可靠性非常高的存储系统。简而言之就是 & 到
的映射过程。
2.映射过程
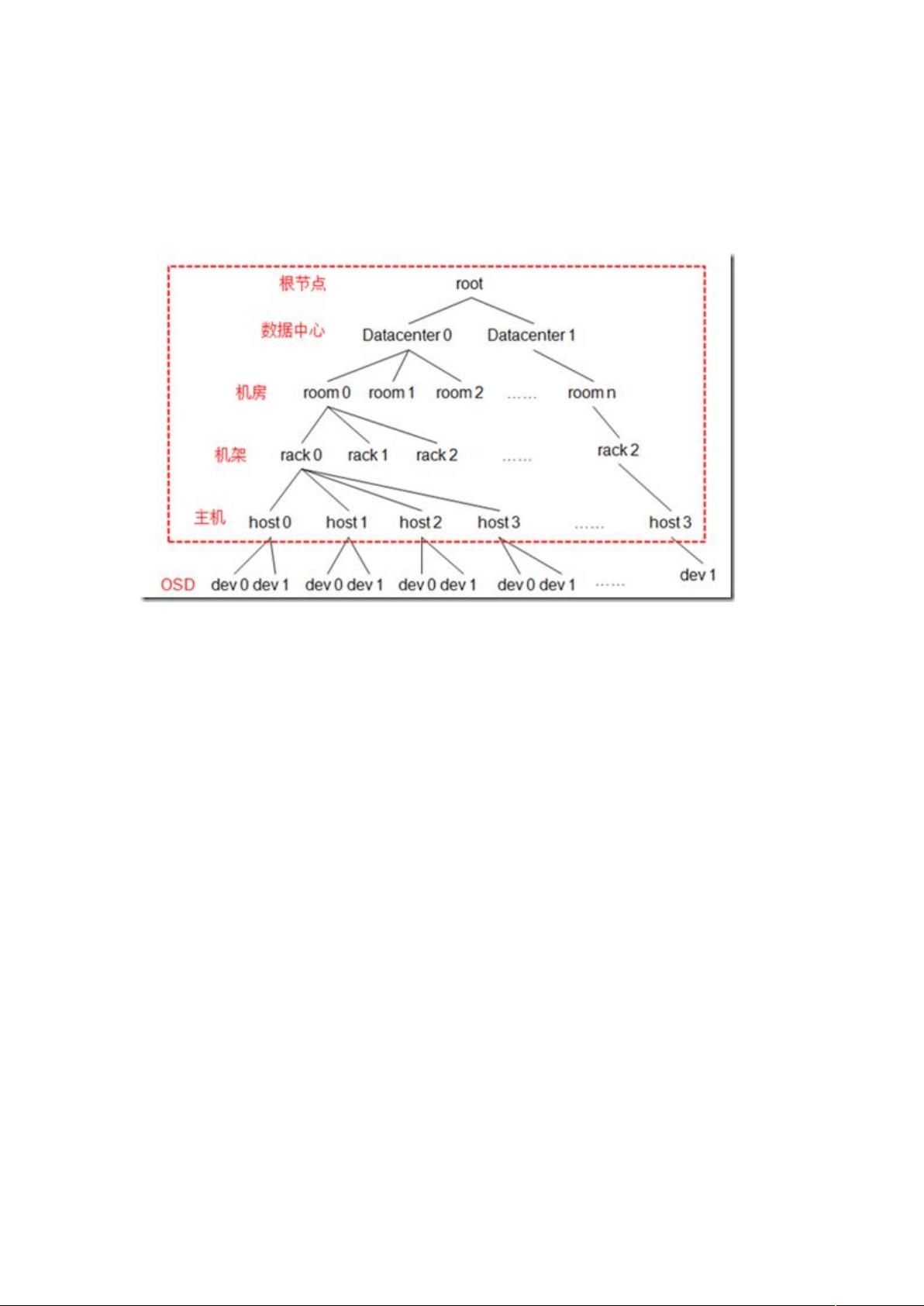
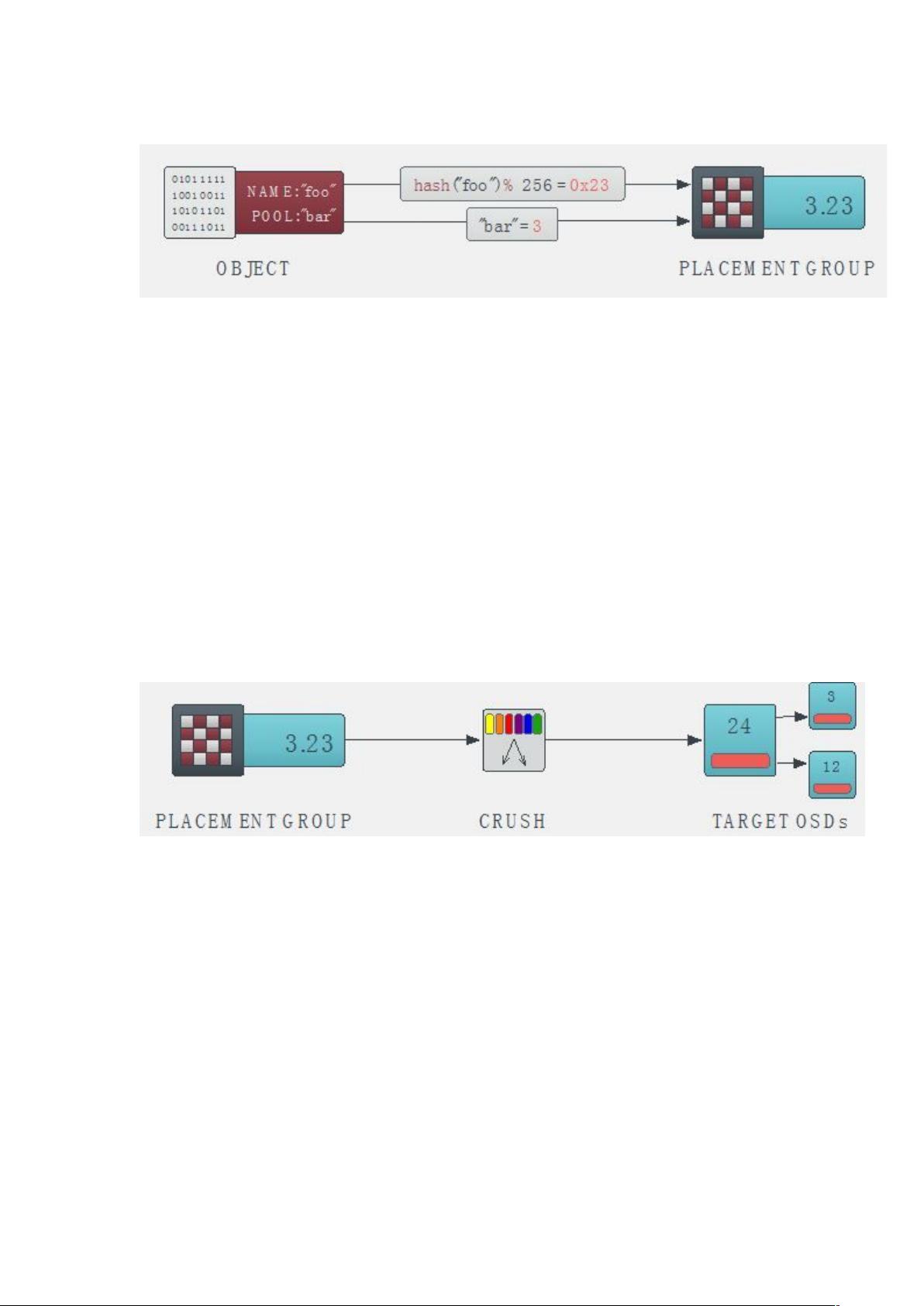
2.1 概念
中 的属性有:$' 的副本数ããã(' & 的数量ãããã)'所使
用的
数据映射( )的方式决定了存储系统的性能和扩展性。
(,&)→ã 的映射由四个因素决定:
($) 算法
(()*:包含当前所有 的状态和 的状态。* 管理当前
中所有的 ,* 规定了 算法的一个范围,在这个范围中选择 结合。

剩余22页未读,继续阅读
资源评论













