

PRE-PUBLICATION DRAFT, TO APPEAR IN IEEE TRANS. ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, DEC. 2012
Copyright (c) 2012 IEEE. Personal use of this material is permitted. However, permission to use this material for any other purposes must be obtained from the
IEEE by sending an email to pubs-permissions@ieee.org.
1
Abstract— High-Efficiency Video Coding (HEVC) is currently
being prepared as the newest video coding standard of the ITU-T
Video Coding Experts Group (VCEG) and the ISO/IEC Moving
Picture Experts Group (MPEG). The main goal of the HEVC
standardization effort is to enable significantly improved
compression performance relative to existing standards – in the
range of 50% bit rate reduction for equal perceptual video
quality. This article provides an overview of the technical features
and characteristics of the HEVC standard.
Index Terms—Video compression, Standards, HEVC, JCT-VC,
MPEG, VCEG, H.264, MPEG-4, AVC.
I. INTRODUCTION
EVC, the High Efficiency Video Coding standard, is the
most recent joint video project of the ITU-T VCEG and
ISO/IEC MPEG standardization organizations, working
together in a partnership known as the Joint Collaborative
Team on Video Coding (JCT-VC) [1]. The first edition of the
HEVC standard is expected to be finalized in January 2013,
resulting in an aligned text that will be published by both ITU-T
and ISO/IEC. Additional work is planned to extend the
standard to support several additional application scenarios
including professional uses with enhanced precision and color
format support, scalable video coding, and 3D / stereo /
multiview video coding. In ISO/IEC, the HEVC standard will
become MPEG-H Part 2 (ISO/IEC 23008-2) and in ITU-T it is
likely to become ITU-T Recommendation H.265.
Video coding standards have evolved primarily through the
development of the well-known ITU-T and ISO/IEC standards.
The ITU-T produced H.261 [2] and H.263 [3], ISO/IEC
produced MPEG-1 [4] and MPEG-4 Visual [5], and the two
organizations jointly produced the H.262/MPEG-2 Video [6]
and H.264/MPEG-4 AVC [7] standards. The two standards that
Manuscript received May 25, 2012.
G. J. Sullivan is with Microsoft Corporation, Redmond, WA 98052 USA
(e-mail: garysull@microsoft.com).
J.-R. Ohm is with the Institute of Communications Engineering, RWTH
Aachen University, Aachen 52056, Germany (e-mail:
ohm@ient.rwth-aachen.de).
W.-J. Han is with the Dept. of Software Development and Management,
Gachon University, Seongnam, 461-701, Korea (corresponding author to
provide phone: +82-31-750-8668; fax: +82-31-750-5662; e-mail:
hurumi@gmail.com).
T. Wiegand is jointly affiliated with the Fraunhofer Institute for
Telecommunications, Heinrich Hertz Institute, Einsteinufer 37, and the Berlin
Institute of Technology, Einsteinufer 35, both in 10587 Berlin, Germany
(e-mail: twiegand@ieee.org)
were jointly produced have had a particularly strong impact and
have found their way into a wide variety of products that are
increasingly prevalent in our daily lives. Throughout this
evolution, continued efforts have been made to maximize
compression capability and improve other characteristics such
as data loss robustness, while considering the computational
resources that were practical for use in products at the time of
anticipated deployment of each standard.
The major video coding standard directly preceding the
HEVC project was H.264/MPEG-4 Advanced Video Coding
(AVC), which was initially developed during 1999–2003, and
then was extended in several important ways during
2003–2009. H.264/MPEG-4 AVC was an enabling technology
for digital video in almost every area that was not previously
covered by H.262/MPEG-2 Video, and has substantially
displaced the older standard within its existing application
domain. It is widely used for many applications, including
broadcast of high definition (HD) TV signals over satellite,
cable, and terrestrial transmission systems, video content
acquisition and editing systems, camcorders, security
applications, Internet and mobile network video, Blu-ray discs,
and real-time conversational applications such as video chat,
video conferencing, and telepresence systems.
However, an increasing diversity of services, the growing
popularity of HD video, and the emergence of beyond-HD
formats (e.g. 4k×2k or 8k×4k resolution) are creating even
stronger needs for coding efficiency superior to
H.264/MPEG-4 AVC’s capabilities. The need is even stronger
when higher resolution is accompanied by stereo or multi-view
capture and display. Moreover, the traffic caused by video
applications targeting mobile devices and tablet-PCs, as well as
the transmission needs for video on demand services, are
imposing severe challenges on today’s networks. An increased
desire for higher quality and resolutions is also arising in
mobile applications.
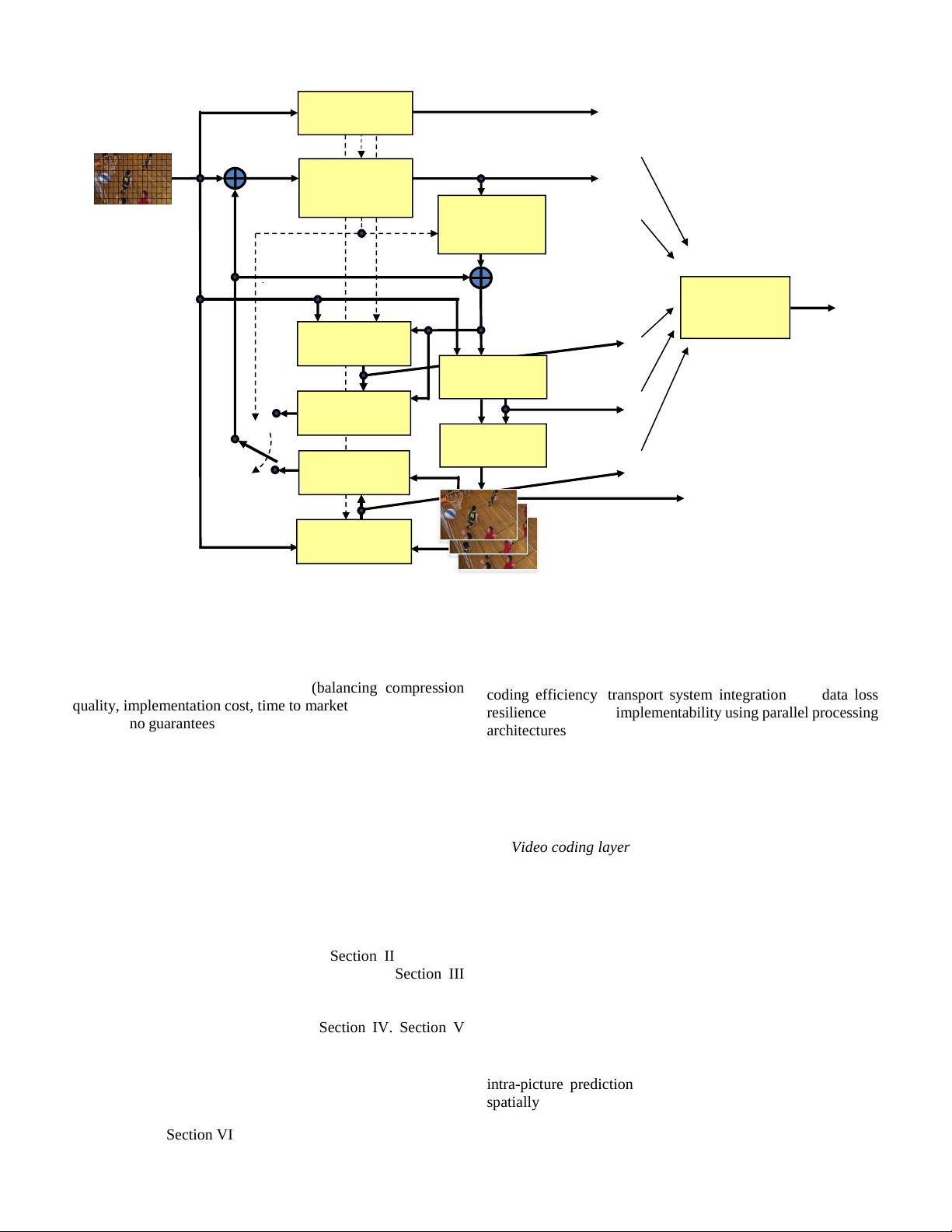
HEVC has been designed to address essentially all existing
applications of H.264/MPEG-4 AVC and to particularly focus
on two key issues: increased video resolution and increased use
of parallel processing architectures. The syntax of HEVC is
generic and should also be generally suited for other
applications that are not specifically mentioned above.
As has been the case for all past ITU-T and ISO/IEC video
coding standards, in HEVC only the bitstream structure and
syntax is standardized, as well as constraints on the bitstream
and its mapping for the generation of decoded pictures. The
mapping is given by defining the semantic meaning of syntax
elements and a decoding process such that every decoder
conforming to the standard will produce the same output when
Overview of the High Efficiency Video Coding
(HEVC) Standard
Gary J. Sullivan, Fellow IEEE, Jens-Rainer Ohm, Member IEEE, Woo-Jin Han, Member IEEE, and
Thomas Wiegand, Fellow IEEE
H

剩余18页未读,继续阅读
资源评论



Nereus_Li
- 粉丝: 18
- 资源: 1









最新资源
- NSKeyValueObservationException如何解决.md
- 基于Java的环境保护与宣传网站论文.doc
- 前端开发中的JS快速排序算法原理及实现方法
- 常见排序算法概述及其性能比较
- 形状分类31-YOLO(v5至v11)、COCO、CreateML、Darknet、Paligemma、VOC数据集合集.rar
- 2018年最新 ECshop母婴用品商城新版系统(微商城+微分销+微信支付)
- BookShopTuto.zip
- 论文复现:结合 CNN 和 LSTM 的滚动轴承剩余使用寿命预测方法
- MySQL中的数据库管理语句-ALTER USER.pdf
- 冒泡排序算法解析及优化.md
- 2024年智算云市场发展与生态分析报告
- qwewq23132131231
- 《木兰诗》教学设计.docx
- 《台阶》教学设计.docx
- 《卖油翁》文言文教学方案.docx
- 《老王》教学设计方案.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


